Spielt Ihre Wahl der SQL Server-Datentypen und ihrer Größe eine Rolle?
Die Antwort liegt in dem Ergebnis, das Sie erhalten haben. Ist Ihre Datenbank in kurzer Zeit aufgebläht? Sind Ihre Abfragen langsam? Hatten Sie falsche Ergebnisse? Wie sieht es mit Laufzeitfehlern beim Einfügen und Aktualisieren aus?
Es ist nicht so sehr eine entmutigende Aufgabe, wenn Sie wissen, was Sie tun. Heute lernen Sie die 5 schlechtesten Entscheidungen kennen, die man mit diesen Datentypen treffen kann. Wenn sie zu einer Gewohnheit von Ihnen geworden sind, sollten wir dies für Sie und Ihre Benutzer beheben.
Viele Datentypen in SQL, viel Verwirrung
Als ich zum ersten Mal von SQL Server-Datentypen erfuhr, war die Auswahl überwältigend. Alle Typen sind in meinem Kopf wie diese Wortwolke in Abbildung 1 durcheinander:

Wir können es jedoch in Kategorien organisieren:
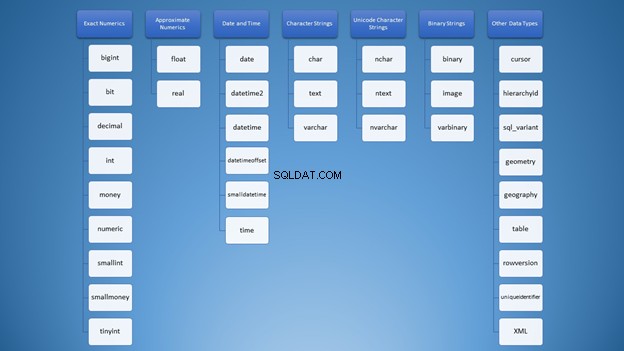
Dennoch haben Sie bei der Verwendung von Zeichenfolgen viele Optionen, die zu einer falschen Verwendung führen können. Zuerst dachte ich, dass varchar und nvarchar waren einfach gleich. Außerdem sind sie beide Zeichenkettentypen. Die Verwendung von Zahlen ist nicht anders. Als Entwickler müssen wir wissen, welcher Typ in verschiedenen Situationen verwendet werden soll.
Aber Sie fragen sich vielleicht, was das Schlimmste ist, was passieren kann, wenn ich die falsche Wahl treffe? Lass es mich dir sagen!
1. Auswahl der falschen SQL-Datentypen
Dieses Element verwendet Zeichenfolgen und ganze Zahlen, um den Punkt zu beweisen.
Verwendung des falschen Zeichenfolge-SQL-Datentyps
Kehren wir zunächst zu den Saiten zurück. Es gibt dieses Ding namens Unicode und Nicht-Unicode-Strings. Beide haben unterschiedliche Speichergrößen. Sie definieren dies oft für Spalten und Variablendeklarationen.
Die Syntax ist entweder varchar (n)/Zeichen (n) oder nvarchar (n)/nchar (n) wobei n ist die Größe.
Beachten Sie, dass n ist nicht die Anzahl der Zeichen, sondern die Anzahl der Bytes. Dies ist ein weit verbreitetes Missverständnis, weil in varchar , die Anzahl der Zeichen entspricht der Größe in Bytes. Aber nicht in nvarchar .
Um diese Tatsache zu beweisen, erstellen wir zwei Tabellen und geben einige Daten in sie ein.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Lassen Sie uns nun ihre Zeilengrößen mit DATALENGTH überprüfen.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Abbildung 3 zeigt, dass der Unterschied zweifach ist. Sieh es dir unten an.
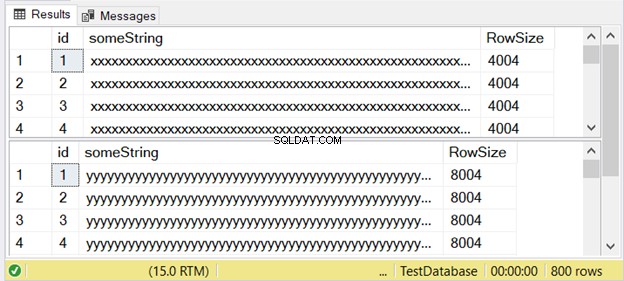
Beachten Sie die zweite Ergebnismenge mit einer Zeilengröße von 8004. Diese verwendet das nvarchar Datentyp. Es ist auch fast doppelt so groß wie die Zeilengröße der ersten Ergebnismenge. Und dies verwendet den varchar Datentyp.
Sie sehen die Auswirkungen auf Speicher und E/A. Abbildung 4 zeigt die logischen Lesevorgänge der beiden Abfragen.
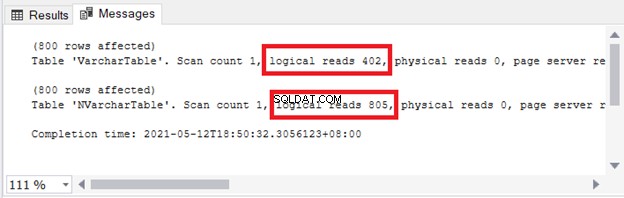
Sehen? Logische Lesevorgänge sind auch zweifach, wenn nvarchar verwendet wird im Vergleich zu varchar .
Sie können also nicht einfach beides austauschbar verwenden. Wenn Sie mehrsprachig speichern müssen Zeichen, verwenden Sie nvarchar . Verwenden Sie andernfalls varchar .
Das heißt, wenn Sie nvarchar verwenden nur für Single-Byte-Zeichen (wie Englisch) ist die Speichergröße höher . Die Abfrageleistung ist auch langsamer bei höheren logischen Lesevorgängen.
In SQL Server 2019 (und höher) können Sie die gesamte Bandbreite an Unicode-Zeichendaten mit varchar speichern oder char mit einer der UTF-8-Sortierungsoptionen.
Verwendung des falschen numerischen Datentyps SQL
Das gleiche Konzept gilt für bigint vs. int – ihre Größe kann Tag und Nacht bedeuten. Wie nvarchar und varchar , bigint ist doppelt so groß wie int (8 Bytes für bigint und 4 Bytes für int ).
Dennoch ist ein weiteres Problem möglich. Wenn Sie die Größe nicht beachten, können Fehler passieren. Wenn Sie ein int verwenden Spalte eingeben und eine Zahl größer als 2.147.483.647 speichern, tritt ein arithmetischer Überlauf auf:
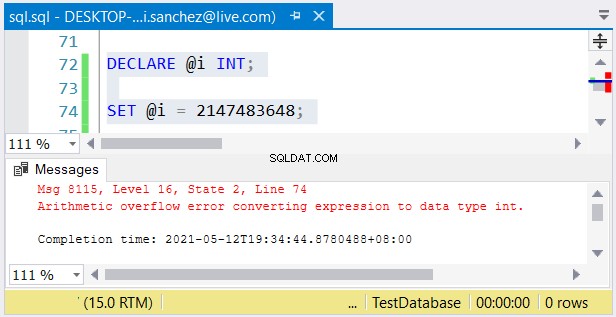
Achten Sie bei der Auswahl ganzzahliger Typen darauf, dass die Daten mit dem Maximalwert passen . Beispielsweise könnten Sie eine Tabelle mit historischen Daten entwerfen. Sie planen, ganze Zahlen als Primärschlüsselwert zu verwenden. Glauben Sie, dass es nicht 2.147.483.647 Zeilen erreichen wird? Verwenden Sie dann int statt bigint als Primärschlüsselspaltentyp.
Das Schlimmste, was passieren kann
Die Auswahl der falschen Datentypen kann die Abfrageleistung beeinträchtigen oder Laufzeitfehler verursachen. Wählen Sie daher den Datentyp, der zu den Daten passt.
2. Erstellen großer Tabellenzeilen mit Big Data-Typen für SQL
Unser nächster Punkt ist mit dem ersten verwandt, aber er wird den Punkt noch weiter mit Beispielen erweitern. Außerdem hat es etwas mit Seiten und großen varchar zu tun oder nvarchar Spalten.
Was ist mit Seiten- und Zeilengrößen?
Das Konzept der Seiten in SQL Server kann mit den Seiten eines Spiralnotizbuchs verglichen werden. Jede Seite in einem Notizbuch hat die gleiche physische Größe. Sie schreiben Wörter und malen Bilder darauf. Wenn eine Seite für eine Reihe von Absätzen und Bildern nicht ausreicht, fahren Sie auf der nächsten Seite fort. Manchmal reißt man auch eine Seite ab und fängt von vorne an.
Ebenso werden Tabellendaten, Indexeinträge und Bilder in SQL Server in Seiten gespeichert.
Eine Seite hat die gleiche Größe von 8 KB. Wenn eine Datenzeile sehr groß ist, passt sie nicht auf die 8-KB-Seite. Eine oder mehrere Spalten werden auf eine andere Seite unter der Zuordnungseinheit ROW_OVERFLOW_DATA geschrieben. Es enthält einen Zeiger auf die ursprüngliche Zeile auf der Seite unter der Zuordnungseinheit IN_ROW_DATA.
Auf dieser Grundlage können Sie während des Datenbankentwurfs nicht einfach viele Spalten in eine Tabelle einfügen. Es wird Auswirkungen auf I/O geben. Außerdem wenn Sie diese Zeilenüberlaufdaten häufig abfragen, ist die Ausführungszeit langsamer . Das kann ein Albtraum sein.
Ein Problem tritt auf, wenn Sie alle Spalten unterschiedlicher Größe maximieren. Dann werden die Daten auf die nächste Seite unter ROW_OVERFLOW_DATA übertragen. Aktualisieren Sie die Spalten mit kleineren Daten, und sie müssen auf dieser Seite entfernt werden. Die neue kleinere Datenzeile wird zusammen mit den anderen Spalten auf die Seite unter IN_ROW_DATA geschrieben. Stellen Sie sich die hier beteiligten E/A vor.
Beispiel für große Zeilen
Bereiten wir zuerst unsere Daten vor. Wir werden Zeichenketten-Datentypen mit großen Größen verwenden.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Ermitteln der Zeilengröße
Untersuchen wir anhand der generierten Daten ihre Zeilengrößen basierend auf DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
Die ersten 300 Datensätze passen auf die IN_ROW_DATA-Seiten, da jede Zeile weniger als 8060 Byte oder 8 KB hat. Aber die letzten 100 Zeilen sind zu groß. Sehen Sie sich die Ergebnismenge in Abbildung 6 an.
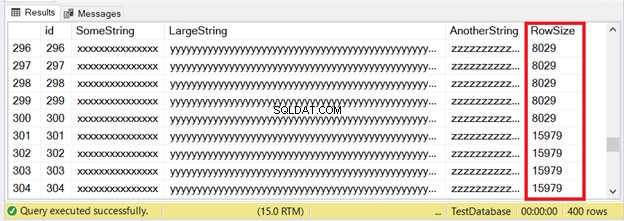
Sie sehen einen Teil der ersten 300 Zeilen. Die nächsten 100 überschreiten die maximale Seitengröße. Woher wissen wir, dass sich die letzten 100 Zeilen in der Zuordnungseinheit ROW_OVERFLOW_DATA befinden?
Inspizieren der ROW_OVERFLOW_DATA
Wir verwenden sys.dm_db_index_physical_stats . Es gibt Seiteninformationen über Tabellen- und Indexeinträge zurück.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Die Ergebnismenge ist in Abbildung 7 dargestellt.

Da ist es. Abbildung 7 zeigt 100 Zeilen unter ROW_OVERFLOW_DATA. Dies stimmt mit Abbildung 6 überein, wenn große Zeilen beginnend mit den Zeilen 301 bis 400 vorhanden sind.
Die nächste Frage ist, wie viele logische Lesevorgänge wir erhalten, wenn wir diese 100 Zeilen abfragen. Versuchen wir es.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Wir sehen 102 logische Lesevorgänge und 100 logische Lob-Lesevorgänge von LargeTable . Belassen Sie diese Zahlen vorerst – wir vergleichen sie später.
Sehen wir uns nun an, was passiert, wenn wir die 100 Zeilen mit kleineren Daten aktualisieren.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Diese Update-Anweisung verwendete dieselben logischen Lesevorgänge und logischen Lob-Lesevorgänge wie in Abbildung 8. Daraus wissen wir, dass aufgrund der logischen Lob-Lesevorgänge von 100 Seiten etwas Größeres passiert ist.
Aber um sicherzugehen, überprüfen wir es mit sys.dm_db_index_physical_stats wie wir es früher getan haben. Abbildung 9 zeigt das Ergebnis:

Gegangen! Seiten und Zeilen von ROW_OVERFLOW_DATA wurden zu Null, nachdem 100 Zeilen mit kleineren Daten aktualisiert wurden. Jetzt wissen wir, dass die Datenverschiebung von ROW_OVERFLOW_DATA nach IN_ROW_DATA erfolgt, wenn große Zeilen verkleinert werden. Stellen Sie sich vor, wenn dies bei Tausenden oder sogar Millionen von Datensätzen häufig vorkommt. Verrückt, nicht wahr?
In Abbildung 8 sahen wir 100 logische Lob-Lesevorgänge. Sehen Sie sich jetzt Abbildung 10 an, nachdem Sie die Abfrage erneut ausgeführt haben:

Es wurde Null!
Das Schlimmste, was passieren kann
Eine langsame Abfrageleistung ist das Nebenprodukt der Zeilenüberlaufdaten. Erwägen Sie, die großen Spalten in eine andere Tabelle zu verschieben, um dies zu vermeiden. Oder reduzieren Sie gegebenenfalls die Größe des varchar oder nvarchar Spalte.
3. Blindes Verwenden der impliziten Konvertierung
SQL erlaubt uns nicht, Daten zu verwenden, ohne den Typ anzugeben. Aber es verzeiht, wenn wir eine falsche Wahl treffen. Es versucht, den Wert in den erwarteten Typ zu konvertieren, jedoch mit einer Strafe. Dies kann in einer WHERE-Klausel oder JOIN geschehen.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Die Kartennummer Spalte ist kein numerischer Typ. Es ist nvarchar . Das erste SELECT bewirkt also eine implizite Konvertierung. Beide werden jedoch problemlos laufen und dieselbe Ergebnismenge erzeugen.
Sehen wir uns den Ausführungsplan in Abbildung 11 an.
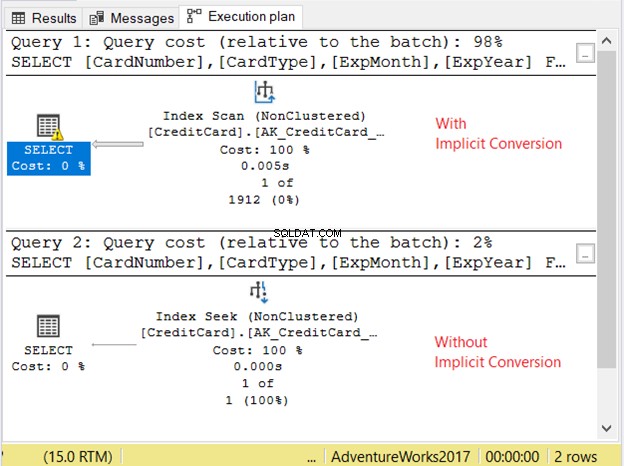
Die 2 Abfragen liefen sehr schnell. In Abbildung 11 sind es null Sekunden. Aber schau dir die 2 Pläne an. Der mit impliziter Konvertierung hatte einen Index-Scan. Es gibt auch ein Warnsymbol und einen dicken Pfeil, der auf den SELECT-Operator zeigt. Es sagt uns, dass es schlecht ist.
Aber es endet nicht dort. Wenn Sie mit der Maus über den SELECT-Operator fahren, sehen Sie etwas anderes:

Das Warnsymbol im SELECT-Operator bezieht sich auf die implizite Konvertierung. Aber wie groß ist der Einfluss? Lassen Sie uns die logischen Lesevorgänge überprüfen.
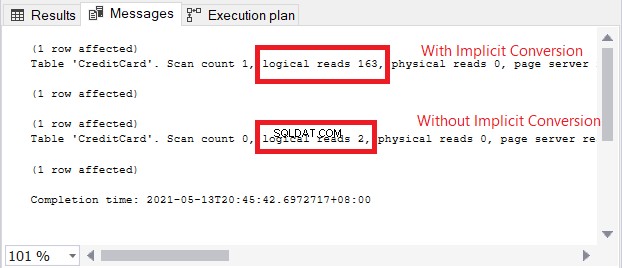
Der Vergleich der logischen Lesevorgänge in Abbildung 13 ist wie Himmel und Erde. Bei der Abfrage von Kreditkarteninformationen verursachte die implizite Konvertierung mehr als das Hundertfache von logischen Lesevorgängen. Sehr schlecht!
Das Schlimmste, was passieren kann
Wenn eine implizite Konvertierung viele logische Lesevorgänge und einen schlechten Plan verursacht hat, müssen Sie mit einer langsamen Abfrageleistung bei großen Ergebnismengen rechnen. Um dies zu vermeiden, verwenden Sie den genauen Datentyp in der WHERE-Klausel und JOINs beim Abgleich der zu vergleichenden Spalten.
4. Verwendung von ungefähren Zahlen und Rundung
Schauen Sie sich noch einmal Bild 2 an. SQL-Server-Datentypen, die zu Näherungszahlen gehören, sind float und echt . Spalten und daraus erstellte Variablen speichern eine enge Annäherung an einen numerischen Wert. Wenn Sie vorhaben, diese Zahlen auf- oder abzurunden, erleben Sie möglicherweise eine große Überraschung. Ich habe hier einen Artikel, in dem dies ausführlich beschrieben wurde. Sehen Sie, wie 1 + 1 3 ergibt und wie Sie mit dem Runden von Zahlen umgehen können.
Das Schlimmste, was passieren kann
Runden eines floats oder echt kann verrückte Ergebnisse haben. Wenn Sie nach dem Runden exakte Werte wünschen, verwenden Sie dezimal oder numerisch stattdessen.
5. Festgelegte String-Datentypen auf NULL setzen
Wenden wir uns nun Datentypen mit fester Größe wie char zu und nchar . Abgesehen von den aufgefüllten Leerzeichen hat das Setzen auf NULL immer noch eine Speichergröße, die der Größe des char entspricht Säule. Also ein char setzen (500)-Spalte auf NULL hat eine Größe von 500, nicht null oder 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
Im obigen Code werden die Daten basierend auf der Größe von char ausgeschöpft und varchar Säulen. Wenn Sie ihre Zeilengröße mit DATALENGTH überprüfen, wird auch die Summe der Größen jeder Spalte angezeigt. Jetzt setzen wir die Spalten auf NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Als nächstes fragen wir die Zeilen mit DATALENGTH:
abSELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Was denken Sie, wird die Datengröße jeder Spalte sein? Sehen Sie sich Abbildung 14 an.
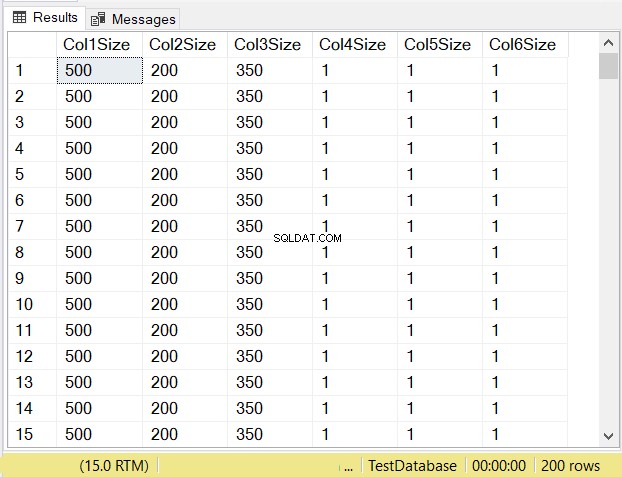
Sehen Sie sich die Spaltengrößen der ersten 3 Spalten an. Vergleichen Sie sie dann mit dem obigen Code, als die Tabelle erstellt wurde. Die Datengröße der NULL-Spalten entspricht der Größe der Spalte. Inzwischen ist die varchar Spalten bei NULL haben eine Datengröße von 1.
Das Schlimmste, was passieren kann
Während des Entwerfens von Tabellen, nullable char Spalten, wenn sie auf NULL gesetzt sind, haben immer noch die gleiche Speichergröße. Sie verbrauchen auch die gleichen Seiten und den gleichen Arbeitsspeicher. Wenn Sie nicht die gesamte Spalte mit Zeichen füllen, ziehen Sie die Verwendung von varchar in Betracht stattdessen.
Was kommt als Nächstes?
Spielen also Ihre Entscheidungen bezüglich der SQL Server-Datentypen und ihrer Größe eine Rolle? Die hier vorgestellten Punkte sollten ausreichen, um einen Punkt zu machen. Also, was kannst du jetzt tun?
- Nehmen Sie sich Zeit, um die von Ihnen unterstützte Datenbank zu überprüfen. Beginnen Sie mit dem einfachsten, wenn Sie mehrere auf Ihrem Teller haben. Und ja, nimm dir Zeit, finde nicht die Zeit. In unserer Branche ist es fast unmöglich, die Zeit zu finden.
- Überprüfen Sie die Tabellen, gespeicherten Prozeduren und alles, was mit Datentypen zu tun hat. Beachten Sie die positiven Auswirkungen beim Identifizieren von Problemen. Sie werden es brauchen, wenn Ihr Chef fragt, warum Sie daran arbeiten müssen.
- Planen Sie, jeden der Problembereiche anzugreifen. Befolgen Sie alle Methoden oder Richtlinien Ihres Unternehmens zur Bewältigung der Probleme.
- Sobald die Probleme weg sind, feiern Sie.
Klingt einfach, aber wir alle wissen, dass es das nicht ist. Wir wissen auch, dass es am Ende der Reise eine gute Seite gibt. Deshalb werden sie Probleme genannt – weil es eine Lösung gibt. Also Kopf hoch.
Haben Sie zu diesem Thema noch etwas hinzuzufügen? Lassen Sie es uns im Kommentarbereich wissen. Und wenn dieser Beitrag Ihnen eine brillante Idee vermittelt hat, teilen Sie sie auf Ihren bevorzugten Social-Media-Plattformen.