Einführung
Entwicklern wird oft gesagt, dass sie gespeicherte Prozeduren verwenden sollen, um die sogenannten Ad-hoc-Abfragen zu vermeiden was zu einer unnötigen Aufblähung des Plancaches führen kann. Sie sehen, wenn wiederkehrender SQL-Code inkonsistent geschrieben wird oder wenn es Code gibt, der spontan dynamisches SQL generiert, neigt SQL Server dazu, einen Ausführungsplan für jede einzelne Ausführung zu erstellen. Dies kann die Gesamtleistung um Folgendes verringern:
Fordern einer Kompilierungsphase für jede Codeausführung.
Aufblasen des Plan-Cache mit zu vielen Plan-Handles, die möglicherweise nicht wiederverwendet werden.
Für Ad-hoc-Workloads optimieren
Ein Weg, wie dieses Problem in der Vergangenheit gelöst wurde, war die Optimierung der Instanz für Ad-hoc-Workloads. Dies kann nur hilfreich sein, wenn die meisten Datenbanken oder die wichtigsten Datenbanken auf der Instanz überwiegend Ad-hoc-SQL ausführen.
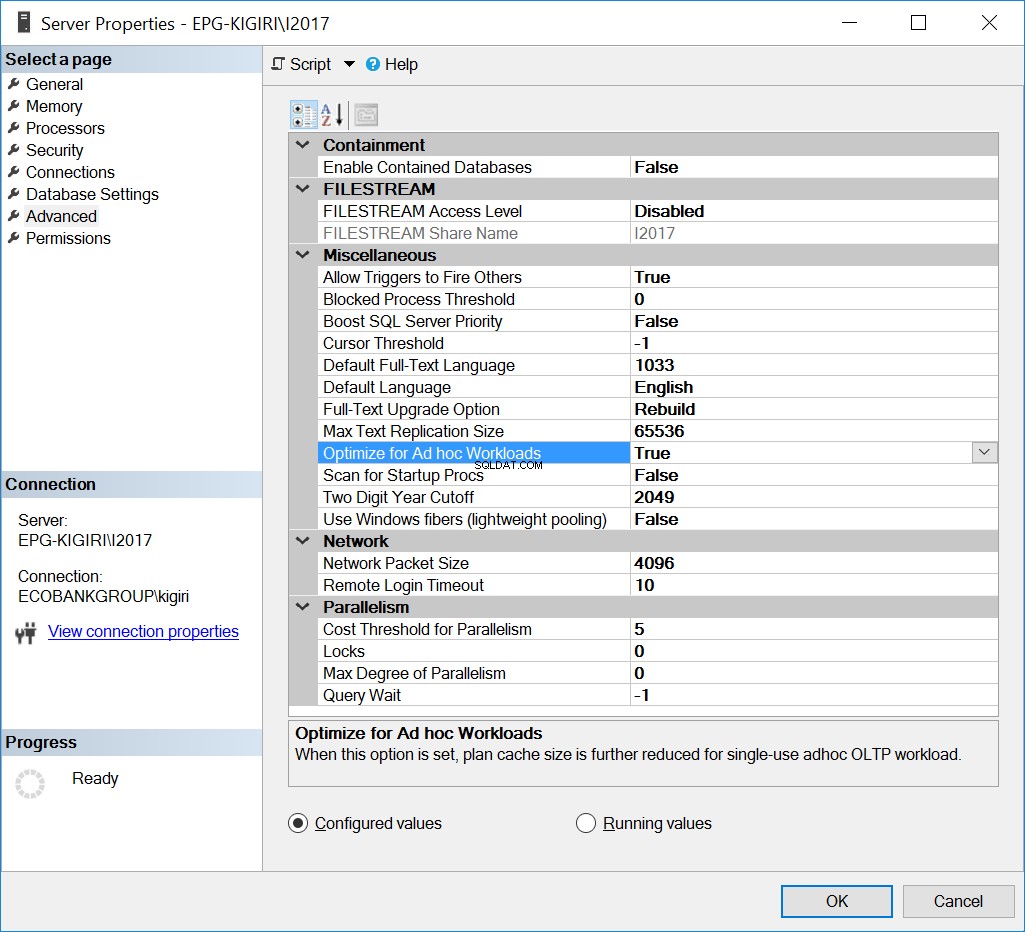
Abb. 1 Für Ad-hoc-Workloads optimieren
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
Im Wesentlichen weist diese Option SQL Server an, eine Teilversion des Plans zu speichern, die als Stub des kompilierten Plans bekannt ist. Der Stub nimmt viel weniger Platz ein als der gesamte Plan.
Als Alternative zu dieser Methode gehen einige Leute ziemlich brutal an das Thema heran und leeren hin und wieder den Plan-Cache. Oder löschen Sie, vorsichtiger, „Einmalnutzungspläne“ mithilfe von DBCC FREESYSTEMCACHE. Das Leeren des gesamten Plan-Cache hat seine Nachteile, wie Sie vielleicht bereits wissen.
Gespeicherte Prozeduren und Parameter verwenden
Durch die Verwendung gespeicherter Prozeduren kann man das durch Ad-Hoc-SQL verursachte Problem praktisch eliminieren. Eine gespeicherte Prozedur wird nur einmal kompiliert, und derselbe Plan wird für nachfolgende Ausführungen derselben oder ähnlicher SQL-Abfragen wiederverwendet. Wenn gespeicherte Prozeduren zum Implementieren von Geschäftslogik verwendet werden, liegt der Hauptunterschied bei den SQL-Abfragen, die schließlich von SQL Server ausgeführt werden, in den Parametern, die zur Ausführungszeit übergeben werden. Da der Plan bereits vorhanden und einsatzbereit ist, verwendet SQL Server denselben Plan, unabhängig davon, welcher Parameter übergeben wird.
Verzerrte Daten
In bestimmten Szenarien sind die Daten, mit denen wir es zu tun haben, nicht gleichmäßig verteilt. Wir können dies demonstrieren – zuerst müssen wir eine Tabelle erstellen:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Unsere Tabelle enthält Daten von Clubmitgliedern aus verschiedenen Ländern. Ein Großteil der Clubmitglieder stammt aus Ghana, zwei weitere Nationen haben zehn bzw. zwei Mitglieder. Um mich auf die Agenda zu konzentrieren und der Einfachheit halber habe ich nur drei Länder und denselben Namen für Mitglieder aus demselben Land Land verwendet. Außerdem habe ich einen geclusterten Index in der ID-Spalte und einen nicht geclusterten Index in der CountryCode-Spalte hinzugefügt, um die Auswirkung verschiedener Ausführungspläne für verschiedene Werte zu demonstrieren.
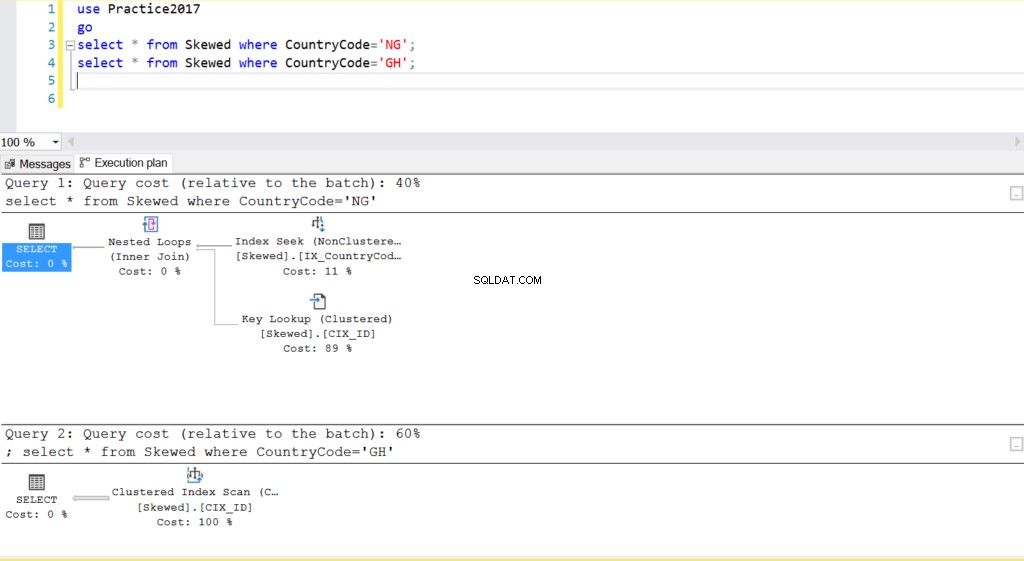
Abb. 2 Ausführungspläne für zwei Abfragen
Wenn wir die Tabelle nach Datensätzen abfragen, bei denen CountryCode NG und GH ist, stellen wir fest, dass SQL Server in diesen Fällen zwei verschiedene Ausführungspläne verwendet. Dies liegt daran, dass die erwartete Anzahl von Zeilen für CountryCode=’NG’ 10 ist, während die für CountryCode=’GH’ 10000 ist. SQL Server bestimmt den bevorzugten Ausführungsplan basierend auf Tabellenstatistiken. Wenn die erwartete Anzahl von Zeilen im Vergleich zur Gesamtzahl von Zeilen in der Tabelle hoch ist, entscheidet SQL Server, dass es besser ist, einfach einen vollständigen Tabellenscan durchzuführen, anstatt auf einen Index zu verweisen. Bei einer viel kleineren geschätzten Anzahl von Zeilen wird der Index nützlich.
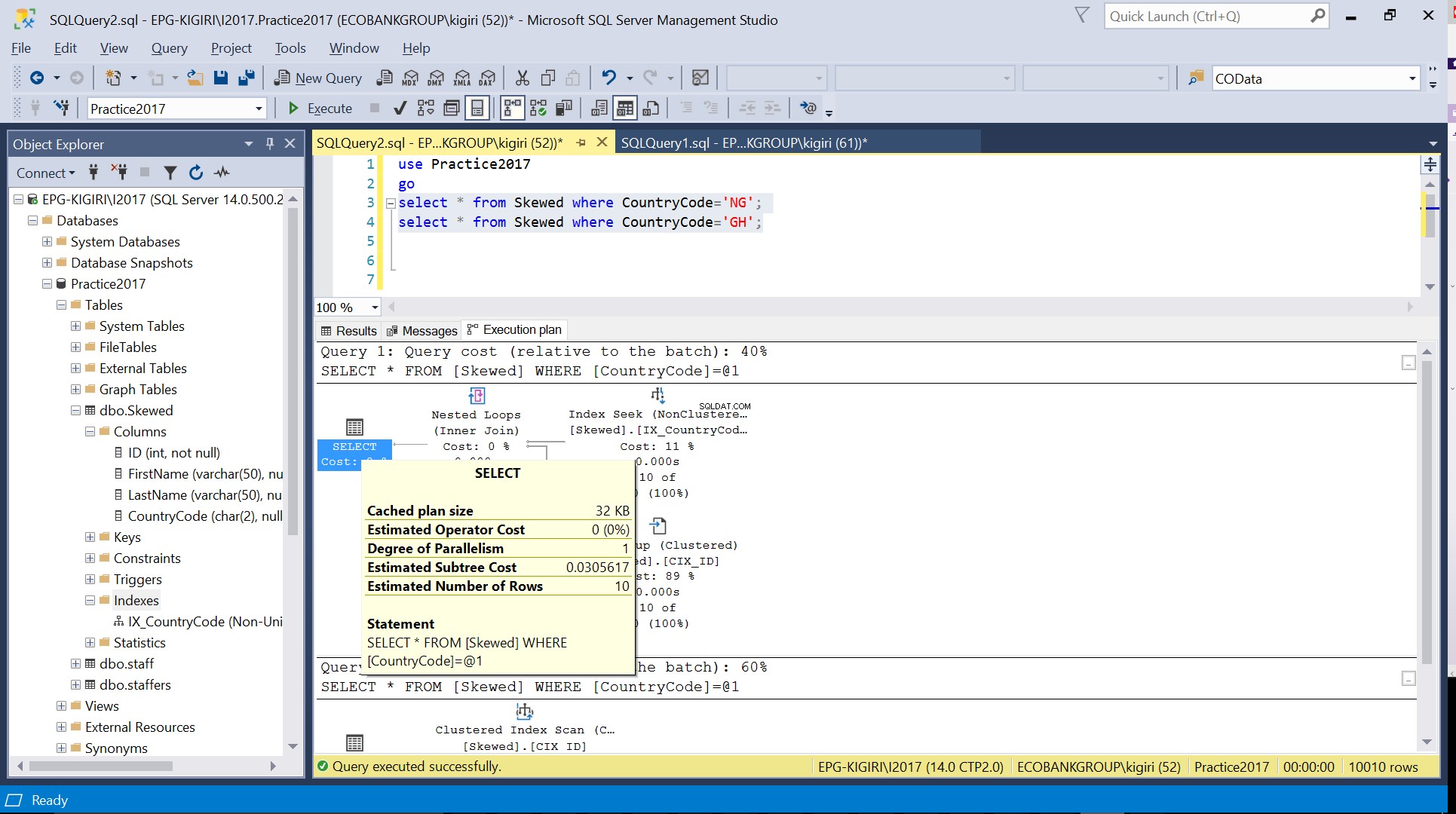
Abb. 3 Geschätzte Zeilenanzahl für CountryCode=’NG’
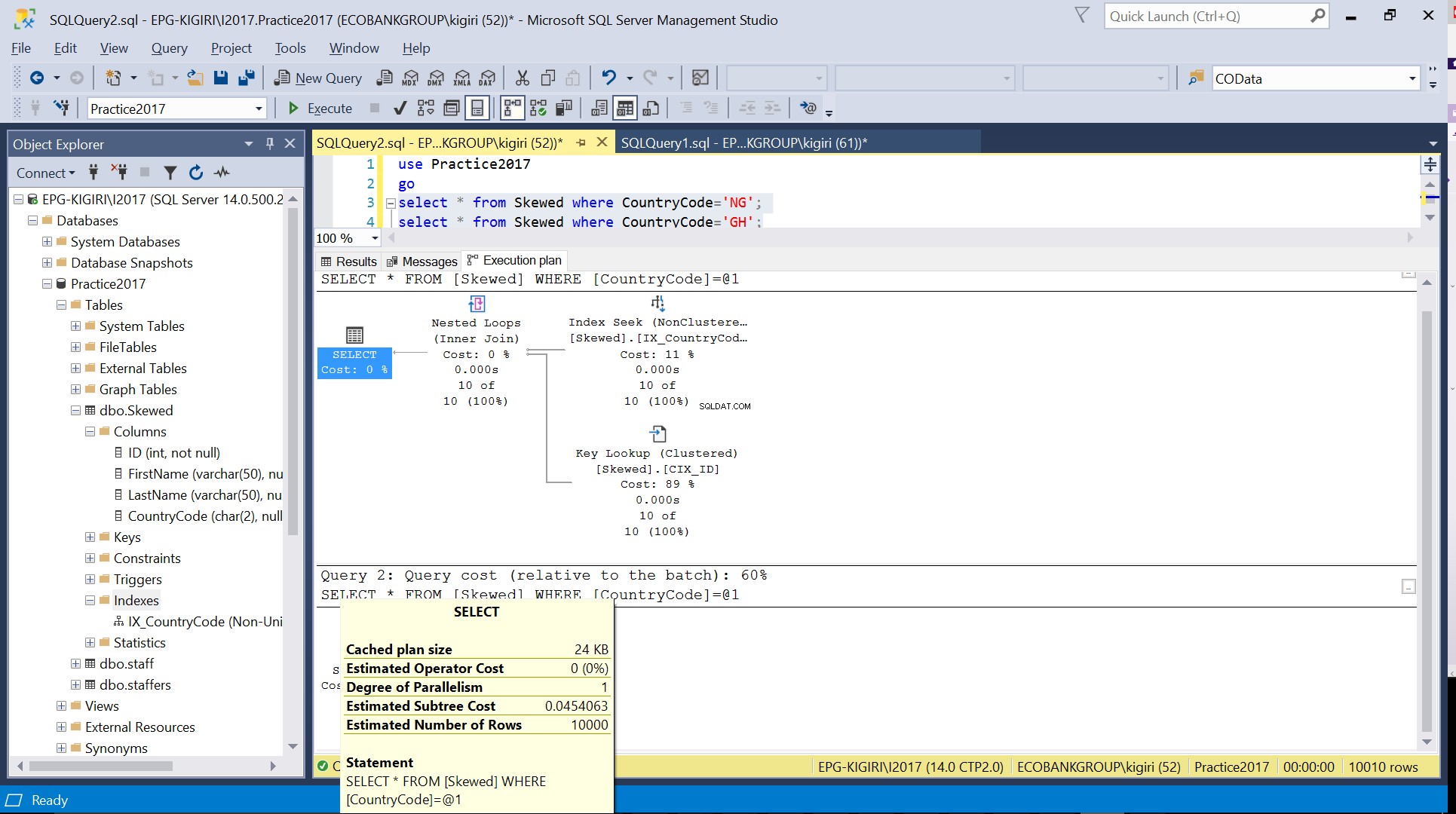
Abb. 4 Geschätzte Zeilenanzahl für CountryCode=’GH’
Gespeicherte Prozeduren eingeben
Wir können eine gespeicherte Prozedur erstellen, um die gewünschten Datensätze abzurufen, indem wir dieselbe Abfrage verwenden. Der einzige Unterschied besteht diesmal darin, dass wir CountryCode als Parameter übergeben (siehe Listing 3). Dabei stellen wir fest, dass der Ausführungsplan derselbe ist, egal welchen Parameter wir übergeben. Der verwendete Ausführungsplan wird durch den Ausführungsplan bestimmt, der beim ersten Aufrufen der gespeicherten Prozedur zurückgegeben wird. Wenn wir beispielsweise die Prozedur zuerst mit CountryCode=’GH’ ausführen, wird ab diesem Zeitpunkt ein vollständiger Tabellenscan verwendet. Wenn wir dann den Prozedur-Cache löschen und die Prozedur zuerst mit CountryCode=’NG’ ausführen, verwendet sie in Zukunft indexbasierte Scans.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
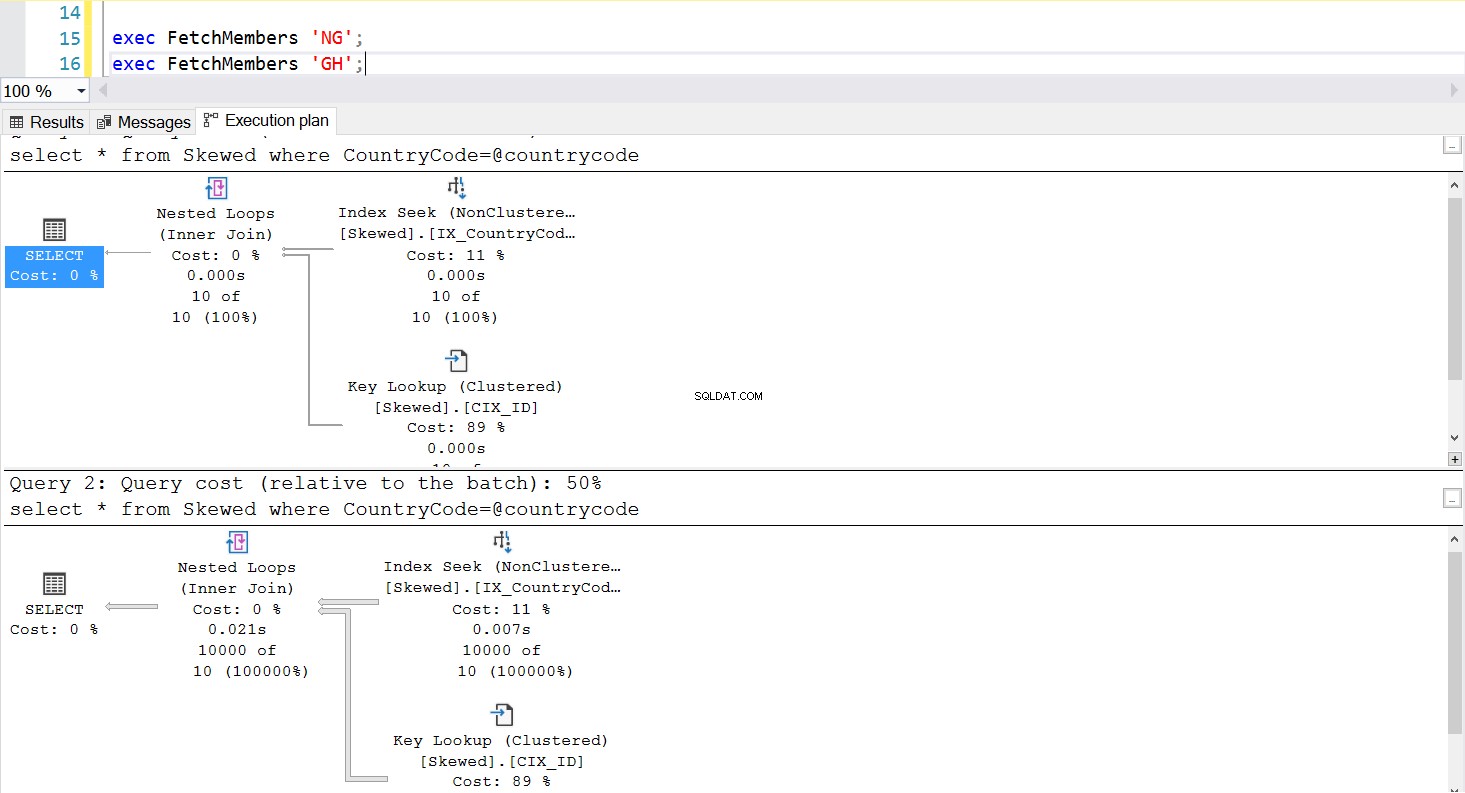
Abb. 5 Ausführungsplan für Indexsuche, wenn „NG“ zuerst verwendet wird
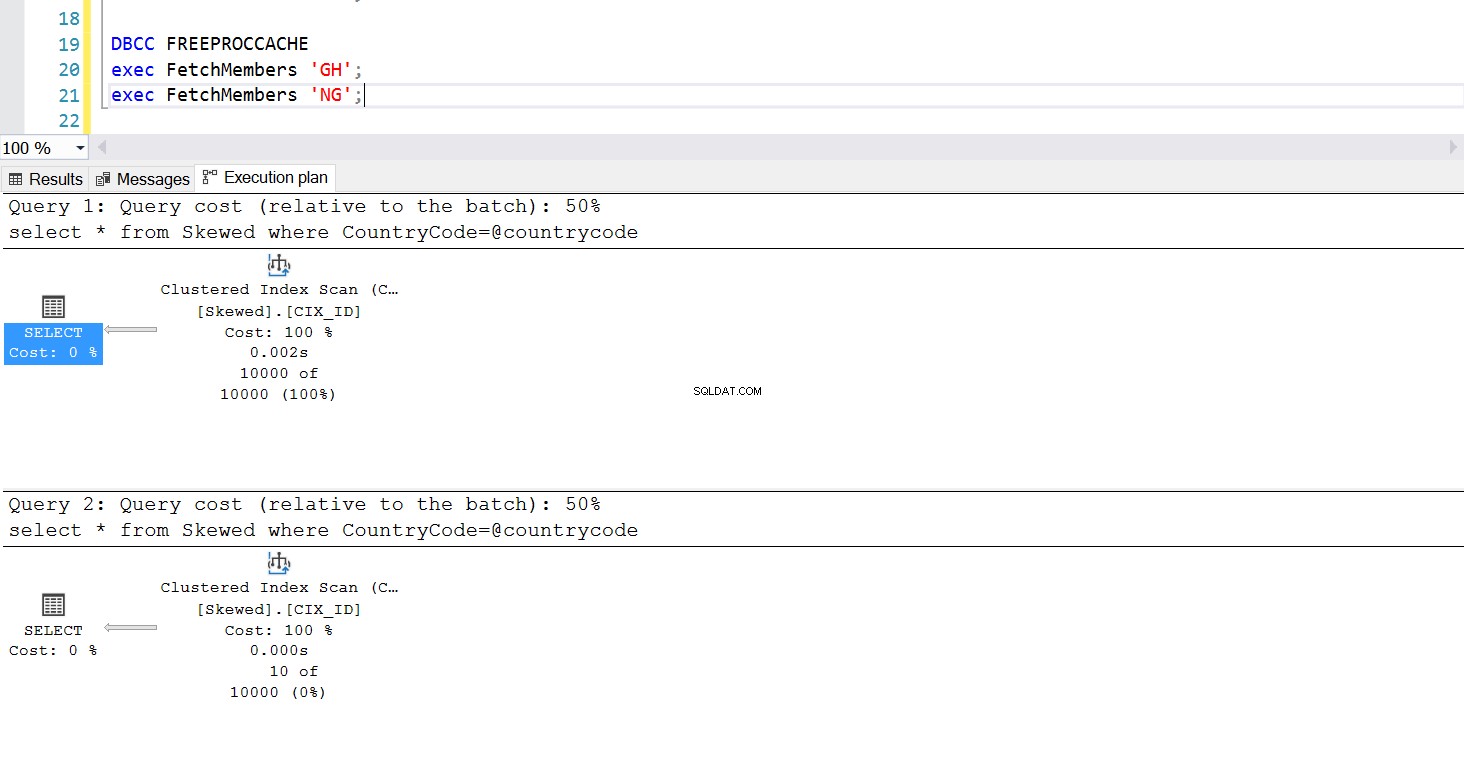
Abb. 6 Ausführungsplan für Clustered-Index-Scans, wenn „GH“ zuerst verwendet wird
Die Ausführung der gespeicherten Prozedur verhält sich wie vorgesehen – der erforderliche Ausführungsplan wird konsistent verwendet. Dies kann jedoch ein Problem darstellen, da ein Ausführungsplan nicht für alle Abfragen geeignet ist, wenn die Daten verzerrt sind. Die Verwendung eines Indexes zum Abrufen einer Sammlung von Zeilen, die fast so groß ist wie die gesamte Tabelle, ist nicht effizient – ebenso wenig wie die Verwendung eines vollständigen Scans, um nur eine kleine Anzahl von Zeilen abzurufen. Das ist das Parameter-Sniffing-Problem.
Mögliche Lösungen
Eine gängige Methode zur Bewältigung des Parameter-Sniffing-Problems besteht darin, bei jeder Ausführung der gespeicherten Prozedur absichtlich eine Neukompilierung aufzurufen. Dies ist viel besser, als den Plan-Cache zu leeren – außer wenn Sie den Cache dieser bestimmten SQL-Abfrage leeren möchten, was durchaus möglich ist. Sehen Sie sich eine aktualisierte Version der gespeicherten Prozedur an. Dieses Mal verwendet es OPTION (RECOMPILE), um das Problem zu verwalten. Abb. 6 zeigt uns, dass jedes Mal, wenn die neue gespeicherte Prozedur ausgeführt wird, sie einen Plan verwendet, der dem Parameter entspricht, den wir übergeben.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
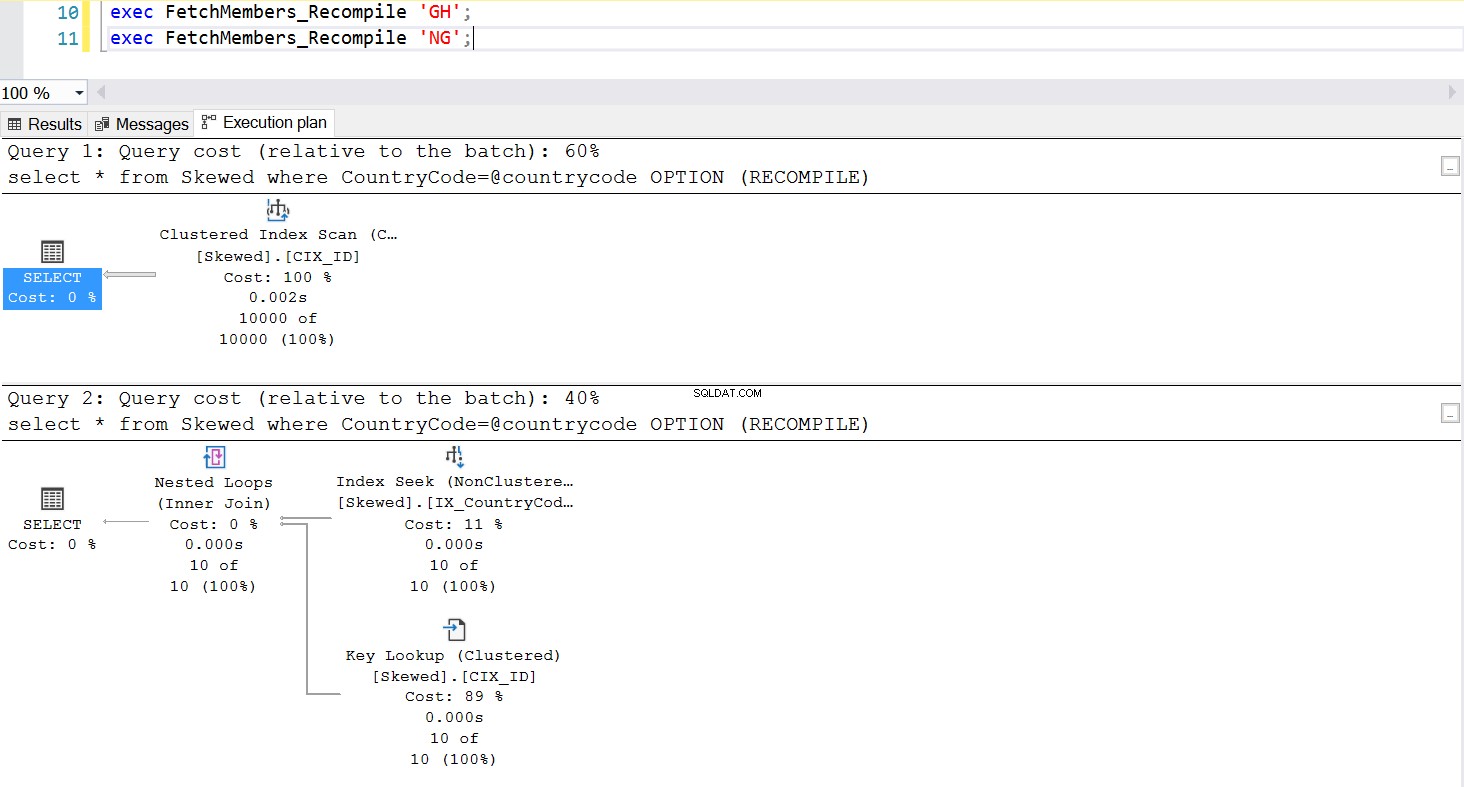
Abb. 7 Verhalten der Stored Procedure mit OPTION (RECOMPILE)
Schlussfolgerung
In diesem Artikel haben wir uns angesehen, wie konsistente Ausführungspläne für gespeicherte Prozeduren zu einem Problem werden können, wenn die Daten, mit denen wir es zu tun haben, verzerrt sind. Wir haben dies auch in der Praxis demonstriert und von einer gemeinsamen Lösung des Problems erfahren. Ich wage zu behaupten, dass dieses Wissen für Entwickler, die SQL Server verwenden, von unschätzbarem Wert ist. Es gibt eine Reihe anderer Lösungen für dieses Problem – Brent Ozar ist tiefer in das Thema eingestiegen und hat auf dem SQLDay Poland 2017 einige tiefgreifendere Details und Lösungen aufgezeigt. Den entsprechenden Link habe ich im Referenzbereich aufgeführt.
Referenzen
Planen Sie den Cache und optimieren Sie Ad-hoc-Workloads
Identifizieren und Beheben von Parameter-Sniffing-Problemen