In Teil 2 dieser Reihe haben Sie die Möglichkeit hinzugefügt, über die REST-API vorgenommene Änderungen mithilfe von SQLAlchemy in einer Datenbank zu speichern, und Sie haben gelernt, wie Sie diese Daten für die REST-API mit Marshmallow serialisieren. Das Verbinden der REST-API mit einer Datenbank, damit die Anwendung Änderungen an vorhandenen Daten vornehmen und neue Daten erstellen kann, ist großartig und macht die Anwendung viel nützlicher und robuster.
Das ist jedoch nur ein Teil der Leistungsfähigkeit, die eine Datenbank bietet. Eine noch leistungsfähigere Funktion ist das R Teil von RDBMS Systeme:Beziehungen . In einer Datenbank ist eine Beziehung die Fähigkeit, zwei oder mehr Tabellen sinnvoll miteinander zu verbinden. In diesem Artikel erfahren Sie, wie Sie Beziehungen umsetzen und Ihre person verwandeln Datenbank in eine Mini-Blogging-Webanwendung.
In diesem Artikel erfahren Sie:
- Warum mehr als eine Tabelle in einer Datenbank nützlich und wichtig ist
- Wie Tabellen miteinander in Beziehung stehen
- Wie SQLAlchemy Ihnen helfen kann, Beziehungen zu verwalten
- Wie Beziehungen Ihnen helfen, eine Mini-Blogging-Anwendung zu erstellen
An wen richtet sich dieser Artikel?
Teil 1 dieser Serie führte Sie durch den Aufbau einer REST-API, und Teil 2 zeigte Ihnen, wie Sie diese REST-API mit einer Datenbank verbinden.
Dieser Artikel erweitert Ihren Programmierwerkzeuggürtel weiter. Sie lernen, wie Sie hierarchische Datenstrukturen erstellen, die von SQLAlchemy als 1:n-Beziehungen dargestellt werden. Darüber hinaus erweitern Sie die bereits erstellte REST-API, um CRUD-Unterstützung (Create, Read, Update, and Delete) für die Elemente in dieser hierarchischen Struktur bereitzustellen.
Die HTML- und JavaScript-Dateien der in Teil 2 vorgestellten Webanwendung werden in großem Umfang modifiziert, um eine voll funktionsfähigere Mini-Blogging-Anwendung zu erstellen. Sie können die endgültige Version des Codes aus Teil 2 im GitHub-Repository für diesen Artikel überprüfen.
Bleiben Sie dran, wenn Sie mit dem Erstellen von Beziehungen und Ihrer Mini-Blogging-Anwendung beginnen!
Zusätzliche Abhängigkeiten
Es gibt keine neuen Python-Abhängigkeiten, die über das hinausgehen, was für den Artikel in Teil 2 erforderlich war. Sie werden jedoch zwei neue JavaScript-Module in der Webanwendung verwenden, um die Dinge einfacher und konsistenter zu machen. Die beiden Module sind die folgenden:
- Lenker.js ist eine Template-Engine für JavaScript, ähnlich wie Jinja2 für Flask.
- Moment.js ist ein Datetime-Parsing- und Formatierungsmodul, das die Anzeige von UTC-Zeitstempeln vereinfacht.
Sie müssen beides nicht herunterladen, da die Webanwendung sie direkt aus dem Cloudflare CDN (Content Delivery Network) bezieht, wie Sie es bereits für das jQuery-Modul tun.
Personendaten zum Bloggen erweitert
In Teil 2 die People data existierte als Dictionary in der build_database.py Python-Code. Dies ist, was Sie verwendet haben, um die Datenbank mit einigen Anfangsdaten zu füllen. Sie werden die People ändern Datenstruktur, um jeder Person eine Liste mit ihnen zugeordneten Notizen zu geben. Die neuen People Die Datenstruktur sieht folgendermaßen aus:
# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Jede Person in People Das Wörterbuch enthält jetzt einen Schlüssel namens notes , die einer Liste zugeordnet ist, die Tupel von Daten enthält. Jedes Tupel in den notes list repräsentiert eine einzelne Notiz enthält den Inhalt und einen Zeitstempel. Die Zeitstempel werden initialisiert (und nicht dynamisch erstellt), um die spätere Reihenfolge in der REST-API zu demonstrieren.
Jede einzelne Person ist mehreren Notizen zugeordnet, und jede einzelne Notiz ist nur einer Person zugeordnet. Diese Datenhierarchie wird als Eins-zu-Viele-Beziehung bezeichnet, bei der ein einzelnes übergeordnetes Objekt mit vielen untergeordneten Objekten in Beziehung steht. Sie werden sehen, wie diese 1:n-Beziehung in der Datenbank mit SQLAlchemy verwaltet wird.
Brute-Force-Ansatz
Die von Ihnen erstellte Datenbank speicherte die Daten in einer Tabelle, und eine Tabelle ist ein zweidimensionales Array aus Zeilen und Spalten. Können die People Wörterbuch oben in einer einzigen Tabelle mit Zeilen und Spalten dargestellt werden? Es kann auf folgende Weise in Ihrer person sein Datenbanktabelle. Unglücklicherweise erzeugt das Einbeziehen aller tatsächlichen Daten in das Beispiel eine Bildlaufleiste für die Tabelle, wie Sie unten sehen werden:
person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Cool, eine Mini-Blogging-Anwendung! | 06.01.2019 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | Das könnte nützlich sein | 08.01.2019 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | Nun, irgendwie nützlich | 06.03.2019 22:17:54 |
| 4 | Brockmann | Kent | 2018-08-08 21:16:01 | Ich werde wirklich tiefgründige Beobachtungen machen | 2019-01-07 22:17:54 |
| 5 | Brockmann | Kent | 2018-08-08 21:16:01 | Vielleicht sind sie offensichtlicher als ich dachte | 2019-02-06 22:17:54 |
| 6 | Ostern | Hase | 2018-08-08 21:16:01 | Hat jemand meine Ostereier gesehen? | 2019-01-07 22:47:54 |
| 7 | Ostern | Hase | 2018-08-08 21:16:01 | Ich bin wirklich spät dran, diese zu liefern! | 06.04.2019 22:17:54 |
Die obige Tabelle würde tatsächlich funktionieren. Alle Daten werden dargestellt, und eine einzelne Person ist mit einer Sammlung verschiedener Notizen verknüpft.
Vorteile
Konzeptionell hat die obige Tabellenstruktur den Vorteil, dass sie relativ einfach zu verstehen ist. Sie könnten sogar argumentieren, dass die Daten in einer Flatfile statt in einer Datenbank gespeichert werden könnten.
Aufgrund der zweidimensionalen Tabellenstruktur könnten Sie diese Daten in einer Tabellenkalkulation speichern und verwenden. Tabellenkalkulationen wurden ziemlich häufig als Datenspeicher eingesetzt.
Nachteile
Obwohl die obige Tabellenstruktur funktionieren würde, hat sie einige echte Nachteile.
Um die Sammlung von Notizen darzustellen, werden alle Daten für jede Person für jede eindeutige Notiz wiederholt, die Personendaten sind daher redundant. Dies ist keine so große Sache für Ihre Personendaten, da es nicht so viele Spalten gibt. Aber stellen Sie sich vor, eine Person hätte viel mehr Spalten. Selbst bei großen Laufwerken kann dies zu einem Speicherproblem werden, wenn Sie mit Millionen von Datenzeilen arbeiten.
Redundante Daten wie diese können im Laufe der Zeit zu Wartungsproblemen führen. Was zum Beispiel, wenn der Osterhase eine Namensänderung für eine gute Idee hält. Dazu müsste jeder Datensatz, der den Namen des Osterhasen enthält, aktualisiert werden, um die Daten konsistent zu halten. Diese Art von Arbeit gegen die Datenbank kann zu Dateninkonsistenzen führen, insbesondere wenn die Arbeit von einer Person ausgeführt wird, die eine SQL-Abfrage von Hand ausführt.
Das Benennen von Spalten wird umständlich. In der obigen Tabelle gibt es einen timestamp Spalte zum Nachverfolgen der Erstellungs- und Aktualisierungszeit einer Person in der Tabelle. Sie möchten auch eine ähnliche Funktionalität für die Erstellungs- und Aktualisierungszeit für eine Notiz haben, aber wegen timestamp bereits verwendet wird, ein erfundener Name von note_timestamp verwendet wird.
Was wäre, wenn Sie der person zusätzliche 1:n-Beziehungen hinzufügen möchten Tisch? Zum Beispiel, um die Kinder oder Telefonnummern einer Person einzuschließen. Jede Person könnte mehrere Kinder und mehrere Telefonnummern haben. Dies könnte relativ einfach mit den Python People durchgeführt werden Wörterbuch oben, indem Sie children hinzufügen und phone_numbers Schlüssel mit neuen Listen, die die Daten enthalten.
Repräsentieren Sie jedoch diese neuen Eins-zu-Viele-Beziehungen in Ihrer person Datenbanktabelle oben deutlich schwieriger wird. Jede neue Eins-zu-Viele-Beziehung erhöht die Anzahl der Zeilen, die zur Darstellung jedes einzelnen Eintrags in den untergeordneten Daten erforderlich sind, dramatisch. Außerdem werden die Probleme im Zusammenhang mit Datenredundanz größer und schwieriger zu handhaben.
Schließlich wären die Daten, die Sie aus der obigen Tabellenstruktur zurückerhalten würden, nicht sehr pythonisch:Es wäre nur eine große Liste von Listen. SQLAlchemy könnte Ihnen nicht sehr helfen, da die Beziehung nicht vorhanden ist.
Relationaler Datenbankansatz
Basierend auf dem, was Sie oben gesehen haben, wird deutlich, dass der Versuch, selbst einen mäßig komplexen Datensatz in einer einzigen Tabelle darzustellen, ziemlich schnell unhandlich wird. Welche Alternative bietet da eine Datenbank? Hier ist das R Teil von RDBMS Datenbanken kommen ins Spiel. Die Darstellung von Beziehungen beseitigt die oben skizzierten Nachteile.
Anstatt zu versuchen, hierarchische Daten in einer einzigen Tabelle darzustellen, werden die Daten in mehrere Tabellen aufgeteilt, mit einem Mechanismus, um sie miteinander in Beziehung zu setzen. Die Tabellen sind nach Sammlungslinien gegliedert, also für Ihre People Wörterbuch oben, bedeutet dies, dass es eine Tabelle gibt, die Personen darstellt, und eine andere, die Notizen darstellt. Dies bringt Ihre ursprüngliche person zurück Tabelle, die so aussieht:
person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockmann | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Ostern | Hase | 2018-08-08 21:16:01.886834 |
Um die neuen Notizinformationen darzustellen, erstellen Sie eine neue Tabelle mit dem Namen note . (Denken Sie an unsere Namenskonvention für Tabellen im Singular.) Die Tabelle sieht folgendermaßen aus:
note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Cool, eine Mini-Blogging-Anwendung! | 06.01.2019 22:17:54 |
| 2 | 1 | Das könnte nützlich sein | 08.01.2019 22:17:54 |
| 3 | 1 | Nun, irgendwie nützlich | 06.03.2019 22:17:54 |
| 4 | 2 | Ich werde wirklich tiefgründige Beobachtungen machen | 2019-01-07 22:17:54 |
| 5 | 2 | Vielleicht sind sie offensichtlicher als ich dachte | 2019-02-06 22:17:54 |
| 6 | 3 | Hat jemand meine Ostereier gesehen? | 2019-01-07 22:47:54 |
| 7 | 3 | Ich bin wirklich spät dran, diese zu liefern! | 06.04.2019 22:17:54 |
Beachten Sie das, wie die person Tabelle, die note Die Tabelle hat eine eindeutige Kennung namens note_id , das ist der Primärschlüssel für die note Tisch. Eine Sache, die nicht offensichtlich ist, ist die Einbeziehung der person_id Wert in der Tabelle. Wozu dient das? Dadurch entsteht die Beziehung zur person Tisch. Während note_id ist der Primärschlüssel für die Tabelle, person_id ist ein sogenannter Fremdschlüssel.
Der Fremdschlüssel gibt jeden Eintrag in der note an Tabelle den Primärschlüssel der person Aufzeichnung, mit der es verknüpft ist. Auf diese Weise kann SQLAlchemy alle Notizen sammeln, die jeder Person zugeordnet sind, indem die person.person_id verknüpft wird Primärschlüssel zu note.person_id Fremdschlüssel, Erstellen einer Beziehung.
Vorteile
Indem Sie den Datensatz in zwei Tabellen aufteilen und das Konzept eines Fremdschlüssels einführen, haben Sie die Daten ein wenig komplexer gemacht und die Nachteile einer einzelnen Tabellendarstellung beseitigt. SQLAlchemy hilft Ihnen, die erhöhte Komplexität ziemlich einfach zu codieren.
Die Daten sind in der Datenbank nicht mehr redundant. Für jede Person, die Sie in der Datenbank speichern möchten, gibt es nur einen Personeneintrag. Dies löst das Speicherproblem sofort und vereinfacht die Wartungsprobleme erheblich.
Wenn der Osterhase trotzdem Namen ändern wollte, müssten Sie nur eine einzige Zeile im person ändern Tabelle und alles andere, was mit dieser Zeile zusammenhängt (wie die note Tabelle) würde die Änderung sofort nutzen.
Die Spaltenbenennung ist konsistenter und aussagekräftiger. Da Personen- und Notizdaten in separaten Tabellen vorhanden sind, kann der Erstellungs- und Aktualisierungszeitstempel in beiden Tabellen konsistent benannt werden, da es keinen Namenskonflikt zwischen den Tabellen gibt.
Außerdem müssen Sie für neue 1:n-Beziehungen, die Sie möglicherweise darstellen möchten, keine Permutationen mehr für jede Zeile erstellen. Nehmen Sie unsere children und phone_numbers Beispiel von früher. Um dies zu implementieren, wäre child erforderlich und phone_number Tische. Jede Tabelle würde einen Fremdschlüssel von person_id enthalten es auf die person zurückbeziehen Tabelle.
Bei Verwendung von SQLAlchemy wären die Daten, die Sie aus den obigen Tabellen zurückerhalten würden, unmittelbar nützlicher, da Sie ein Objekt für jede Personenzeile erhalten würden. Dieses Objekt hat benannte Attribute, die den Spalten in der Tabelle entsprechen. Eines dieser Attribute ist eine Python-Liste, die die zugehörigen Notizobjekte enthält.
Nachteile
Während der Brute-Force-Ansatz einfacher zu verstehen war, macht das Konzept der Fremdschlüssel und Beziehungen das Denken über die Daten etwas abstrakter. Über diese Abstraktion muss bei jeder Beziehung nachgedacht werden, die Sie zwischen Tabellen herstellen.
Die Nutzung von Beziehungen bedeutet, sich auf die Nutzung eines Datenbanksystems festzulegen. Dies ist ein weiteres Tool zum Installieren, Erlernen und Warten über die Anwendung hinaus, die die Daten tatsächlich verwendet.
SQLAlchemy-Modelle
Um die beiden obigen Tabellen und die Beziehung zwischen ihnen zu verwenden, müssen Sie SQLAlchemy-Modelle erstellen, die beide Tabellen und die Beziehung zwischen ihnen kennen. Hier ist die SQLAlchemy person Modell aus Teil 2, aktualisiert, um eine Beziehung zu einer Sammlung von notes aufzunehmen :
1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
Die Zeilen 1 bis 8 der obigen Python-Klasse sehen genauso aus wie das, was Sie zuvor in Teil 2 erstellt haben. Die Zeilen 9 bis 16 erstellen ein neues Attribut im person Klasse namens notes . Diese neuen notes Attribute wird in den folgenden Codezeilen definiert:
-
Zeile 9: Wie die anderen Attribute der Klasse erstellt diese Zeile ein neues Attribut namens
notesund setzt es gleich einer Instanz eines Objekts namensdb.relationship. Dieses Objekt erstellt die Beziehung, die Sie derpersonhinzufügen Klasse und wird mit allen in den folgenden Zeilen definierten Parametern erstellt. -
Zeile 10: Der String-Parameter
'Note'definiert die SQLAlchemy-Klasse, diepersonKlasse wird verwandt sein. Dienoteclass ist noch nicht definiert, weshalb es hier ein String ist. Dies ist eine Vorwärtsreferenz und hilft bei der Behandlung von Problemen, die die Reihenfolge der Definitionen verursachen könnte, wenn etwas benötigt wird, das erst später im Code definiert wird. Der'Note'string erlaubt diepersonKlasse, um dieNotezu finden Klasse zur Laufzeit, die nach beidenpersonist undNotewurden definiert. -
Zeile 11: Die
backref='person'Parameter ist schwieriger. Es erstellt eine sogenannte Rückwärtsreferenz inNoteObjekte. Jede Instanz einerNote-Objekt enthält ein Attribut namensperson. Dieperson-Attribut verweist auf das übergeordnete Objekt, das ein bestimmterNoteenthält Instanz zugeordnet ist. Einen Verweis auf das übergeordnete Objekt (personin diesem Fall) im untergeordneten Element kann sehr nützlich sein, wenn Ihr Code über Notizen iteriert und Informationen über das übergeordnete Element enthalten muss. Dies passiert überraschend oft im Display-Rendering-Code. -
Zeile 12: Die
cascade='all, delete, delete-orphan'Der Parameter bestimmt, wie Notizobjektinstanzen behandelt werden, wenn Änderungen an der übergeordnetenpersonvorgenommen werden Beispiel. Wenn beispielsweise einepersonObjekt gelöscht wird, erstellt SQLAlchemy die SQL, die zum Löschen derpersonerforderlich ist aus der Datenbank. Zusätzlich teilt dieser Parameter mit, dass auch allenotesgelöscht werden sollen damit verbundenen Instanzen. Weitere Informationen zu diesen Optionen finden Sie in der SQLAlchemy-Dokumentation. -
Zeile 13: Der
single_parent=TrueParameter ist erforderlich, wenndelete-orphanist Teil der vorherigencascadeParameter. Dies weist SQLAlchemy an, verwaisteNotenicht zuzulassen Instanzen (einNoteohne übergeordnetepersonObjekt) existieren, weil jederNotehat einen alleinerziehenden Elternteil. -
Zeile 14: Der
order_by='desc(Note.timestamp)'Der Parameter teilt SQLAlchemy mit, wie dieNotesortiert werden soll Instanzen, die einerpersonzugeordnet sind . Wenn einepersonObjekt abgerufen wird, standardmäßig dienotesAttributliste enthältNoteObjekte in unbekannter Reihenfolge. Die SQLAlchemydesc(...)Die Funktion sortiert die Notizen in absteigender Reihenfolge von der neuesten zur ältesten. Wenn diese Zeile stattdessenorder_by='Note.timestamp'wäre , würde SQLAlchemy standardmäßigasc(...)verwenden Funktion, und sortieren Sie die Notizen in aufsteigender Reihenfolge, vom ältesten zum neuesten.
Nun, da Ihre person Modell hat die neuen notes -Attribut, und dies stellt die Eins-zu-Viele-Beziehung zu Note dar -Objekte müssen Sie ein SQLAlchemy-Modell für eine Note definieren :
1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
Die note Die Klasse definiert die Attribute, aus denen eine Notiz besteht, wie in unserem Beispiel note zu sehen ist Datenbanktabelle von oben. Die Attribute werden hier definiert:
-
Zeile 1 erstellt die
noteKlasse, die vondb.Modelerbt , genauso wie Sie es zuvor beim Erstellen derpersongetan haben Klasse. -
Zeile 2 teilt der Klasse mit, welche Datenbanktabelle verwendet werden soll, um
Notezu speichern Objekte. -
Zeile 3 erstellt die
note_id-Attribut, das als ganzzahliger Wert und als Primärschlüssel für dieNotedefiniert wird Objekt. -
Zeile 4 erstellt die
person_id-Attribut und definiert es als Fremdschlüssel, der sich aufNotebezieht Klasse zurpersonKlasse mitperson.person_idPrimärschlüssel. Dies und diePerson.notes-Attribut, sind, wie SQLAlchemy weiß, was zu tun ist, wenn mitpersoninteragiert wird undNoteObjekte. -
Zeile 5 erstellt den
content-Attribut, das den eigentlichen Text der Notiz enthält. Dernullable=False-Parameter gibt an, dass es in Ordnung ist, neue Notizen ohne Inhalt zu erstellen. -
Zeile 6 erstellt den
timestampAttribut und genau wiepersonKlasse enthält dies die Erstellungs- oder Aktualisierungszeit für eine bestimmteNoteBeispiel.
Datenbank initialisieren
Jetzt, da Sie die person aktualisiert haben und erstellte die note Modelle verwenden, werden Sie sie verwenden, um die Testdatenbank people.db neu zu erstellen . Sie tun dies, indem Sie build_database.py aktualisieren Code aus Teil 2. So sieht der Code aus:
1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
Der obige Code stammt aus Teil 2, mit einigen Änderungen, um die Eins-zu-Viele-Beziehung zwischen person zu erstellen und Note . Hier sind die aktualisierten oder neuen Zeilen, die dem Code hinzugefügt wurden:
-
Zeile 4 wurde aktualisiert, um die
Notezu importieren zuvor definierte Klasse. -
Zeile 7 bis 39 enthalten die aktualisierten
PEOPLEWörterbuch, das unsere Personendaten enthält, zusammen mit der Liste der Notizen, die jeder Person zugeordnet sind. Diese Daten werden in die Datenbank eingefügt. -
Zeile 49 bis 61 Iterieren Sie über
PEOPLEWörterbuch, das jedepersonerhält wiederum und verwendet es, um einepersonzu erstellen Objekt. -
Zeile 53 iteriert über
person.notesListe, wobei jedenoteabgerufen wird wiederum. -
Zeile 54 entpackt den
contentundtimestampaus jedernoteTupel. -
Zeile 55 bis 60 erstellt eine
note-Objekt und hängt es mitp.notes.append()an die Sammlung von Personennotizen an . -
Zeile 61 fügt die
personhinzu Objektpzur Datenbanksitzung. -
Zeile 63 schreibt alle Aktivitäten in der Sitzung in die Datenbank. An diesem Punkt werden alle Daten an
persongeschrieben undNoteTabellen in derpeople.dbDatenbankdatei.
Sie können das mit den notes sehen Sammlung in der person Objektinstanz p ist genau wie das Arbeiten mit jeder anderen Liste in Python. SQLAlchemy kümmert sich um die zugrunde liegenden Eins-zu-Viele-Beziehungsinformationen, wenn db.session.commit() Anruf wird getätigt.
Zum Beispiel genau wie eine person Instanz hat ihr Primärschlüsselfeld person_id von SQLAlchemy initialisiert, wenn es an die Datenbank übergeben wird, Instanzen von Note werden ihre Primärschlüsselfelder initialisiert. Außerdem der Note Fremdschlüssel person_id wird ebenfalls mit dem Primärschlüsselwert der person initialisiert Instanz, mit der es verknüpft ist.
Hier ist eine Beispielinstanz einer person Objekt vor dem db.session.commit() in einer Art Pseudocode:
Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Hier ist das Beispiel person Objekt nach dem db.session.commit() :
Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Der wichtige Unterschied zwischen den beiden besteht darin, dass der Primärschlüssel der person und Note Objekte wurden initialisiert. Die Datenbank-Engine hat sich darum gekümmert, als die Objekte aufgrund der in Teil 2 besprochenen Funktion zum automatischen Inkrementieren von Primärschlüsseln erstellt wurden.
Zusätzlich die person_id Fremdschlüssel in allen Note -Instanzen wurde initialisiert, um auf ihre übergeordnete Instanz zu verweisen. Dies geschieht aufgrund der Reihenfolge, in der die person und Note Objekte werden in der Datenbank erstellt.
SQLAlchemy ist sich der Beziehung zwischen person bewusst und Note Objekte. Wenn eine person Objekt wird an person übergeben Datenbanktabelle erhält SQLAlchemy die person_id Primärschlüsselwert. Dieser Wert wird verwendet, um den Fremdschlüsselwert von person_id zu initialisieren in einer note Objekt, bevor es an die Datenbank übergeben wird.
SQLAlchemy kümmert sich um diese Datenbankpflege aufgrund der Informationen, die Sie bei Person.notes übergeben haben -Attribut wurde mit db.relationship(...) initialisiert Objekt.
Außerdem der Person.timestamp Attribut wurde mit dem aktuellen Zeitstempel initialisiert.
Ausführen von build_database.py Programm über die Befehlszeile (in der virtuellen Umgebung erstellt die Datenbank mit den neuen Ergänzungen neu und bereitet sie für die Verwendung mit der Webanwendung vor. Diese Befehlszeile erstellt die Datenbank neu:
$ python build_database.py
Die build_database.py Hilfsprogramm gibt bei erfolgreicher Ausführung keine Meldungen aus. Wenn es eine Ausnahme auslöst, wird ein Fehler auf dem Bildschirm ausgegeben.
REST-API aktualisieren
Sie haben die SQLAlchemy-Modelle aktualisiert und sie zum Aktualisieren der people.db verwendet Datenbank. Jetzt ist es an der Zeit, die REST-API zu aktualisieren, um Zugriff auf die neuen Notizinformationen zu gewähren. Hier ist die REST-API, die Sie in Teil 2 erstellt haben:
| Aktion | HTTP-Verb | URL-Pfad | Beschreibung |
|---|---|---|---|
| Erstellen | POST | /api/people | URL zum Erstellen einer neuen Person |
| Lesen | GET | /api/people | URL zum Lesen einer Sammlung von Personen |
| Lesen | GET | /api/people/{person_id} | URL zum Lesen einer einzelnen Person nach person_id |
| Aktualisieren | PUT | /api/people/{person_id} | URL zum Aktualisieren einer bestehenden Person nach person_id |
| Löschen | DELETE | /api/people/{person_id} | URL zum Löschen einer bestehenden Person nach person_id |
Die obige REST-API stellt HTTP-URL-Pfade zu Sammlungen von Dingen und zu den Dingen selbst bereit. Sie können eine Liste von Personen abrufen oder mit einer einzelnen Person aus dieser Personenliste interagieren. Dieser Pfadstil verfeinert das, was von links nach rechts zurückgegeben wird, und wird im Laufe der Zeit detaillierter.
Sie werden dieses Muster von links nach rechts fortsetzen, um detaillierter zu werden und auf die Notizensammlungen zuzugreifen. Hier ist die erweiterte REST-API, die Sie erstellen werden, um Notizen für die Mini-Blog-Webanwendung bereitzustellen:
| Aktion | HTTP-Verb | URL-Pfad | Beschreibung |
|---|---|---|---|
| Erstellen | POST | /api/people/{person_id}/notes | URL zum Erstellen einer neuen Notiz |
| Lesen | GET | /api/people/{person_id}/notes/{note_id} | URL zum Lesen der einzelnen Notiz einer einzelnen Person |
| Aktualisieren | PUT | api/people/{person_id}/notes/{note_id} | URL zum Aktualisieren der einzelnen Notiz einer einzelnen Person |
| Löschen | DELETE | api/people/{person_id}/notes/{note_id} | URL zum Löschen der einzelnen Notiz einer einzelnen Person |
| Lesen | GET | /api/notes | URL, um alle Notizen für alle Personen sortiert nach note.timestamp zu erhalten |
Es gibt zwei Variationen in den notes Teil der REST-API im Vergleich zu der in people verwendeten Konvention Abschnitt:
-
Es ist keine URL definiert, um alle
notesabzurufen einer Person zugeordnet, nur eine URL, um eine einzelne Notiz zu erhalten. Damit wäre die REST-API in gewisser Weise komplettiert worden, aber die Webanwendung, die Sie später erstellen, benötigt diese Funktionalität nicht. Daher wurde es weggelassen. -
Es gibt die Einbindung der letzten URL
/api/notes. Dies ist eine praktische Methode, die für die Webanwendung erstellt wurde. Es wird im Mini-Blog auf der Homepage verwendet, um alle Notizen im System anzuzeigen. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the swagger.yml Datei.
Hinweis:
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id}
There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API.
Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings.
The updated and newly created Marshmallow schemas are in the models.py module, which are explained below, and look like this:
1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes Verhältnis. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes .
The PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes aufführen. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person attribute. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person connected.
The NotePersonSchema class defines what is nested in the NoteSchema.person attribute.
Hinweis:
You might be wondering why the PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person attribute. You may be wondering whether the PersonSchema class could be defined this way:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work.
People
Now that you’ve got the schemas in place to work with the one-to-many relationship between person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API.
The people.py module needs two changes. The first is to import the Note class, along with the person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this:
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no note rows to join with.
At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables, person and note , with a relationship between them.
Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related note row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) .
This is where the outer join comes in handy. It’s a kind of boolean or operation. It returns person data even if there is no associated note data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created person object that has no notes yet.
You can see the complete people.py in the article repository.
Notes
You’ll create a notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) :
1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedpersonSQLAlchemy object comparingperson_idfrom bothpersonandNote. - Line 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete notes.py .
Updated Swagger UI
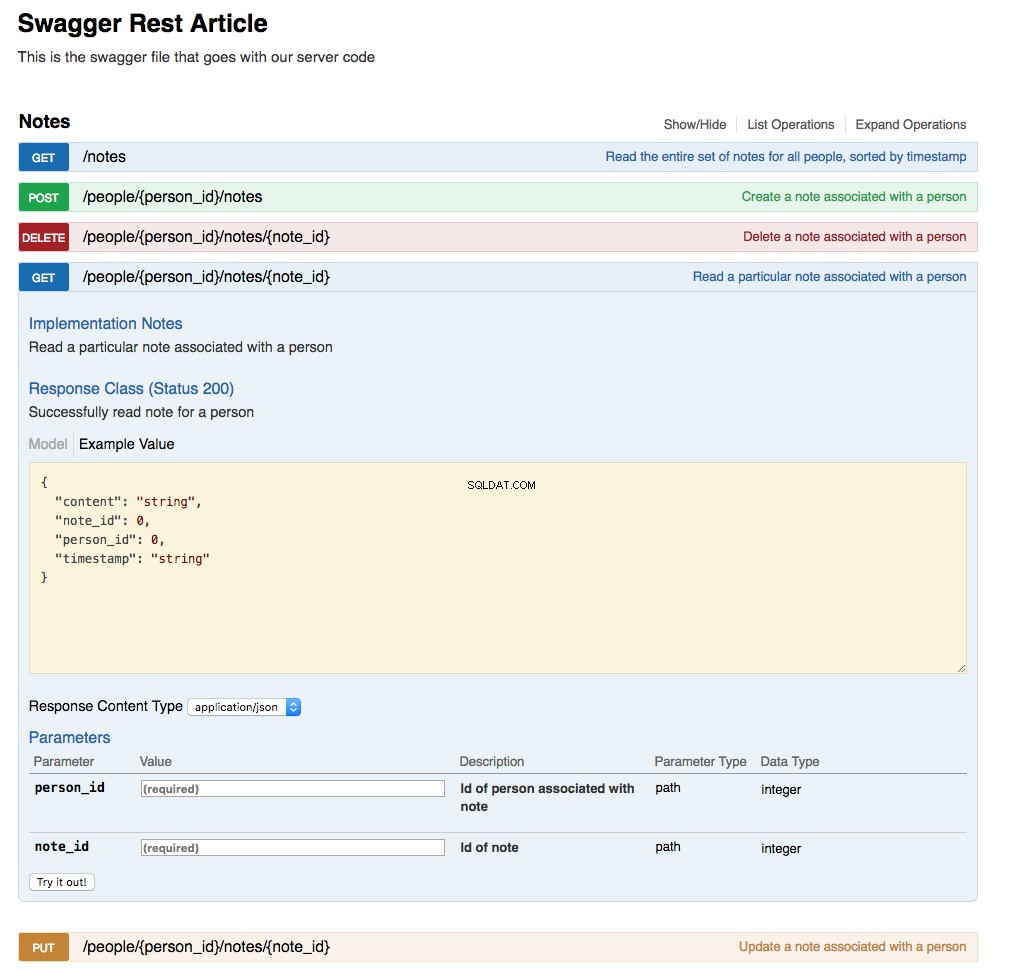
The Swagger UI has been updated by the action of updating the swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded:
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (
localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest -
The people page (
localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one -
The notes page (
localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
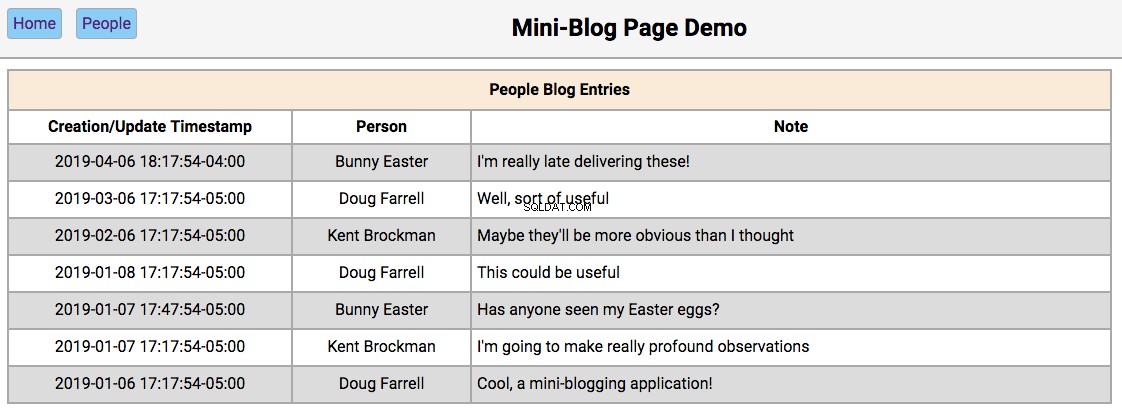
Below is a screenshot of the home page showing the initialized database contents:
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the
/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled. -
Double-clicking on a person’s note will take the user to the
/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
Below is a screenshot of the people page showing the people in the initialized database:
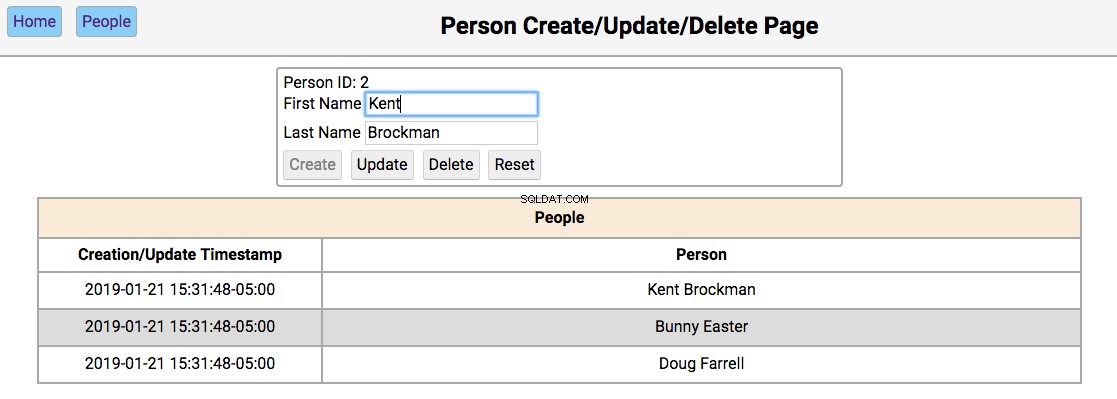
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete Tasten.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
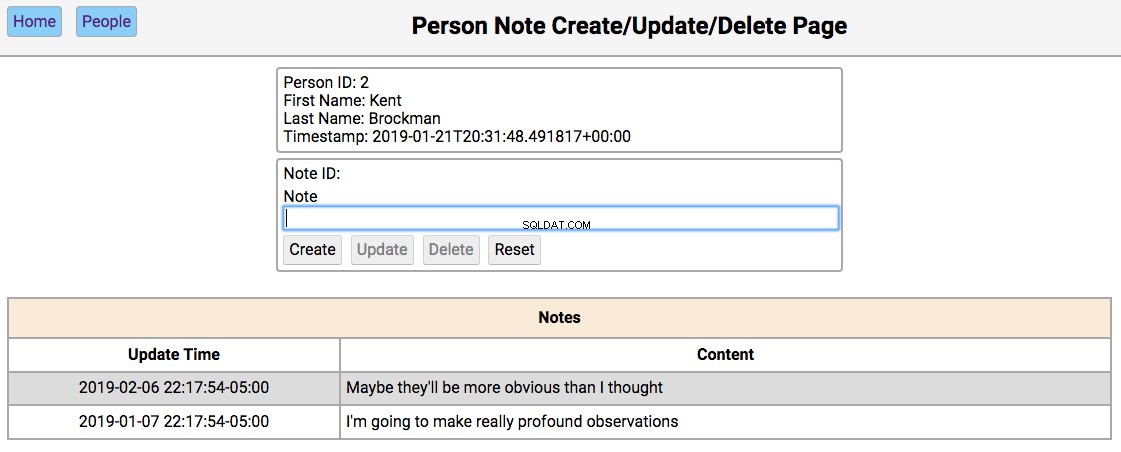
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete Tasten.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Schlussfolgerung
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »