JPA (Java-Persistenzanmerkung ) ist Javas Standardlösung, um die Lücke zwischen objektorientierten Domänenmodellen und relationalen Datenbanksystemen zu schließen. Die Idee ist, Java-Klassen relationalen Tabellen und Eigenschaften dieser Klassen den Zeilen in der Tabelle zuzuordnen. Dies verändert die Semantik der Gesamterfahrung der Java-Codierung durch die nahtlose Zusammenarbeit zweier unterschiedlicher Technologien innerhalb desselben Programmierparadigmas. Dieser Artikel bietet einen Überblick und die unterstützende Implementierung in Java.
Ein Überblick
Relationale Datenbanken sind vielleicht die stabilste aller Persistenztechnologien, die in der Datenverarbeitung verfügbar sind, anstatt all der damit verbundenen Komplexität. Denn auch im Zeitalter sogenannter „Big Data“ sind relationale „NoSQL“-Datenbanken heute beständig gefragt und florieren. Relationale Datenbanken sind eine stabile Technologie, nicht nur durch Worte, sondern durch ihre Existenz im Laufe der Jahre. NoSQL mag gut für den Umgang mit großen Mengen strukturierter Daten im Unternehmen sein, aber die zahlreichen Transaktionslasten werden besser durch relationale Datenbanken gehandhabt. Außerdem gibt es einige großartige Analysetools für relationale Datenbanken.
Zur Kommunikation mit relationalen Datenbanken hat ANSI eine Sprache namens SQL standardisiert (Strukturierte Abfragesprache ). Eine in dieser Sprache geschriebene Anweisung kann sowohl zum Definieren als auch zum Bearbeiten von Daten verwendet werden. Das Problem von SQL im Umgang mit Java besteht jedoch darin, dass sie eine nicht übereinstimmende syntaktische Struktur haben und im Kern sehr unterschiedlich sind, was bedeutet, dass SQL prozedural ist, während Java objektorientiert ist. Es wird also nach einer funktionierenden Lösung gesucht, bei der Java objektorientiert sprechen kann und die relationale Datenbank sich trotzdem versteht. JPA ist die Antwort auf diesen Aufruf und stellt den Mechanismus bereit, um eine funktionierende Lösung zwischen den beiden herzustellen.
Relational zur Objektzuordnung
Java-Programme interagieren mit relationalen Datenbanken, indem sie JDBC verwenden (Java-Datenbankkonnektivität )-API. Ein JDBC-Treiber ist der Schlüssel zur Konnektivität und ermöglicht es einem Java-Programm, diese Datenbank mithilfe der JDBC-API zu manipulieren. Sobald die Verbindung hergestellt ist, feuert das Java-Programm SQL-Abfragen in Form von String ab s zum Kommunizieren von Erstellungs-, Einfüge-, Aktualisierungs- und Löschvorgängen. Das ist für alle praktischen Zwecke ausreichend, aber aus Sicht eines Java-Programmierers unbequem. Was wäre, wenn die Struktur von relationalen Tabellen in reine Java-Klassen umgestaltet werden könnte und Sie dann auf die übliche objektorientierte Weise damit umgehen könnten? Die Struktur einer relationalen Tabelle ist eine logische Darstellung von Daten in Tabellenform. Tabellen bestehen aus Spalten, die Entitätsattribute beschreiben, und Zeilen sind die Sammlung von Entitäten. Beispielsweise kann eine EMPLOYEE-Tabelle folgende Entitäten mit ihren Attributen enthalten.
| Mitarbeiternummer | Name | dept_no | Gehalt | Ort |
| 112233 | Peter | 123 | 1200 | LA |
| 112244 | Ray | 234 | 1300 | NY |
| 112255 | Sandip | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
Zeilen sind durch den Primärschlüssel (emp_number) innerhalb einer Tabelle eindeutig; dies ermöglicht eine schnelle Suche. Eine Tabelle kann durch einen Schlüssel, wie etwa einen Fremdschlüssel (dept_no), der sich auf die entsprechende Zeile in einer anderen Tabelle bezieht, mit einer oder mehreren Tabellen verknüpft sein.
Gemäß der Java Persistence 2.1-Spezifikation fügt JPA Unterstützung für Schemagenerierung, Typkonvertierungsmethoden, Verwendung von Entitätsdiagrammen in Abfragen und Suchvorgängen, nicht synchronisierten Persistenzkontext, Aufruf gespeicherter Prozeduren und Injektion in Entitäts-Listener-Klassen hinzu. Es enthält auch Verbesserungen der Abfragesprache Java Persistence, der Criteria API und der Zuordnung nativer Abfragen.
Kurz gesagt, es tut alles, um die Illusion zu vermitteln, dass es beim Umgang mit relationalen Datenbanken keinen prozeduralen Teil gibt und alles objektorientiert ist.
JPA-Implementierung
JPA beschreibt die Verwaltung relationaler Daten in einer Java-Anwendung. Es ist eine Spezifikation und es gibt eine Reihe von Implementierungen davon. Einige beliebte Implementierungen sind Hibernate, EclipseLink und Apache OpenJPA. JPA definiert die Metadaten über Annotationen in Java-Klassen oder über XML-Konfigurationsdateien. Wir können jedoch sowohl XML als auch Anmerkungen verwenden, um die Metadaten zu beschreiben. In einem solchen Fall überschreibt die XML-Konfiguration die Anmerkungen. Dies ist sinnvoll, da Anmerkungen mit dem Java-Code geschrieben werden, während XML-Konfigurationsdateien außerhalb des Java-Codes liegen. Daher müssen später ggf. Änderungen in den Metadaten vorgenommen werden; im Fall einer annotationsbasierten Konfiguration ist ein direkter Zugriff auf Java-Code erforderlich. Dies ist möglicherweise nicht immer möglich. In einem solchen Fall können wir neue oder geänderte Metadatenkonfigurationen in eine XML-Datei schreiben, ohne dass der ursprüngliche Code geändert wird, und dennoch den gewünschten Effekt erzielen. Dies ist der Vorteil der XML-Konfiguration. Die annotationsbasierte Konfiguration ist jedoch bequemer zu verwenden und ist die beliebteste Wahl unter Programmierern.
- Ruhezustand ist dank Red Hat die beliebteste und fortschrittlichste aller JPA-Implementierungen. Es verwendet seine eigenen Optimierungen und zusätzlichen Funktionen, die zusätzlich zu seiner JPA-Implementierung verwendet werden können. Es hat eine größere Benutzergemeinschaft und ist gut dokumentiert. Einige der zusätzlichen proprietären Funktionen sind die Unterstützung für Mandantenfähigkeit, das Verbinden nicht zugeordneter Entitäten in Abfragen, Zeitstempelverwaltung und so weiter.
- EclipseLink basiert auf TopLink und ist eine Referenzimplementierung von JPA-Versionen. Es bietet Standard-JPA-Funktionalitäten, abgesehen von einigen interessanten proprietären Funktionen, wie z. B. Unterstützung von Mandantenfähigkeit, Behandlung von Datenbankänderungsereignissen und so weiter.
JPA in einem Java SE-Programm verwenden
Um JPA in einem Java-Programm zu verwenden, benötigen Sie einen JPA-Anbieter wie Hibernate oder EclipseLink oder eine andere Bibliothek. Außerdem benötigen Sie einen JDBC-Treiber, der eine Verbindung zur jeweiligen relationalen Datenbank herstellt. Im folgenden Code haben wir beispielsweise die folgenden Bibliotheken verwendet:
- Anbieter: EclipseLink
- JDBC-Treiber: JDBC-Treiber für MySQL (Connector/J)
Wir werden eine Eins-zu-eins- und eine Eins-zu-viele-Beziehung zwischen zwei Tabellen – Mitarbeiter und Abteilung – herstellen, wie im folgenden EER-Diagramm dargestellt (siehe Abbildung 1).
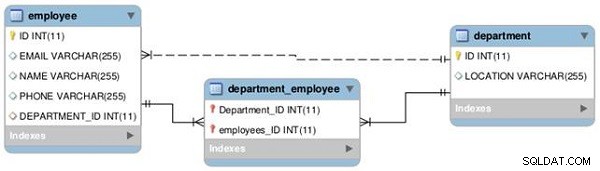
Abbildung 1: Tabellenbeziehungen
Der Mitarbeiter Tabelle wird einer Entitätsklasse unter Verwendung der Annotation wie folgt zugeordnet:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
Und die Abteilung Tabelle wird wie folgt einer Entitätsklasse zugeordnet:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Die Konfigurationsdatei persistence.xml , wird in der META-INF erstellt Verzeichnis. Diese Datei enthält die Verbindungskonfiguration, wie z. B. verwendeter JDBC-Treiber, Benutzername und Passwort für den Datenbankzugriff, und andere relevante Informationen, die der JPA-Anbieter benötigt, um die Datenbankverbindung herzustellen.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Entitäten selbst bestehen nicht. Logik muss angewendet werden, um Entitäten zu manipulieren, um ihren dauerhaften Lebenszyklus zu verwalten. Der EntityManager Die von der JPA bereitgestellte Schnittstelle ermöglicht es der Anwendung, Entitäten in der relationalen Datenbank zu verwalten und nach ihnen zu suchen. Wir erstellen ein Abfrageobjekt mit Hilfe des EntityManager mit der Datenbank zu kommunizieren. So erhalten Sie EntityManager Für eine bestimmte Datenbank verwenden wir ein Objekt, das eine EntityManagerFactory implementiert Schnittstelle. Es gibt ein statisches Methode namens createEntityManagerFactory , in der Persistenz Klasse, die EntityManagerFactory zurückgibt für die als String angegebene Persistenzeinheit Streit. In der folgenden rudimentären Implementierung haben wir die Logik implementiert.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Jetzt können wir loslegen und die Hauptschnittstelle der Anwendung erstellen. Hier haben wir der Einfachheit halber und aus Platzgründen nur die Einfügeoperation implementiert.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Hinweis: Bitte konsultieren Sie die entsprechende Java-API-Dokumentation für detaillierte Informationen zu APIs, die im vorangehenden Code verwendet werden. |
Schlussfolgerung
Wie offensichtlich sein sollte, ist die Kernterminologie des JPA- und Persistenzkontexts umfangreicher als der hier gegebene Einblick, aber mit einem schnellen Überblick zu beginnen ist besser als langer komplizierter schmutziger Code und seine konzeptionellen Details. Wenn Sie ein wenig Programmiererfahrung im Core-JDBC haben, werden Sie zweifellos zu schätzen wissen, wie JPA Ihr Leben einfacher machen kann. Wir werden in den kommenden Artikeln nach und nach tiefer in JPA eintauchen.