Möchten Sie lernen, wie man ein Datenbanksystem entwirft und einen Geschäftsprozess auf ein Datenmodell abbildet? Dann ist dieser Beitrag für Sie.
In diesem Artikel erfahren Sie, wie Sie ein einfaches Datenbankschema für ein Personalvermittlungsunternehmen entwerfen. Nachdem Sie dieses Tutorial gelesen haben, können Sie verstehen, wie Datenbankschemata für reale Anwendungen entworfen werden.
Der Geschäftsprozess des Personalbeschaffungssystems
Vor dem Entwerfen einer Datenbank oder eines Datenmodells ist es unerlässlich, den grundlegenden Geschäftsprozess für dieses System zu verstehen. Das Datenbankschema, das wir erstellen, ist für ein imaginäres Personalvermittlungsunternehmen oder -team. Sehen wir uns zunächst die Schritte zur Einstellung neuer Mitarbeiter an:
- Unternehmen wenden sich an Personalagenturen, um in ihrem Namen einzustellen. In einigen Fällen rekrutieren Unternehmen Mitarbeiter direkt.
- Der Rekrutierungsverantwortliche startet den Rekrutierungsprozess. Dieser Prozess kann mehrere Schritte umfassen, wie z. B. das anfängliche Screening, einen schriftlichen Test, das erste Gespräch, das Folgegespräch, die eigentliche Einstellungsentscheidung usw.
- Haben sich die Recruiter auf einen bestimmten Ablauf geeinigt – und dieser kann sich je nach Auftraggeber, Unternehmen oder Stelle ändern – wird die Stelle auf verschiedenen Plattformen ausgeschrieben.
- Bewerber beginnen mit der Bewerbung um die Stelle.
- Die Bewerber werden in die engere Wahl gezogen und zu einem Test- oder Erstgespräch eingeladen.
- Die Bewerber erscheinen zum Test/Interview.
- Die Tests werden von den Personalvermittlern bewertet. In einigen Fällen werden Tests zur Benotung an Spezialisten weitergeleitet.
- Die Vorstellungsgespräche der Bewerber werden von einem oder mehreren Personalvermittlern bewertet.
- Bewerber werden anhand von Tests und Interviews bewertet.
- Die Einstellungsentscheidung ist gefallen.
Ein Rekrutierungssystem-Datenbankschema
Im Hinblick auf den oben genannten Prozess ist unser Datenbankschema in fünf Themenbereiche unterteilt:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
Wir werden jeden dieser Bereiche in der Reihenfolge, in der sie aufgeführt sind, im Detail überprüfen. Unten sehen Sie das gesamte Datenmodell.
Prozess
Die Prozesskategorie enthält Informationen zu den Rekrutierungsprozessen. Es enthält drei Tabellen:process , step und process_step . Wir werden uns jeden ansehen.
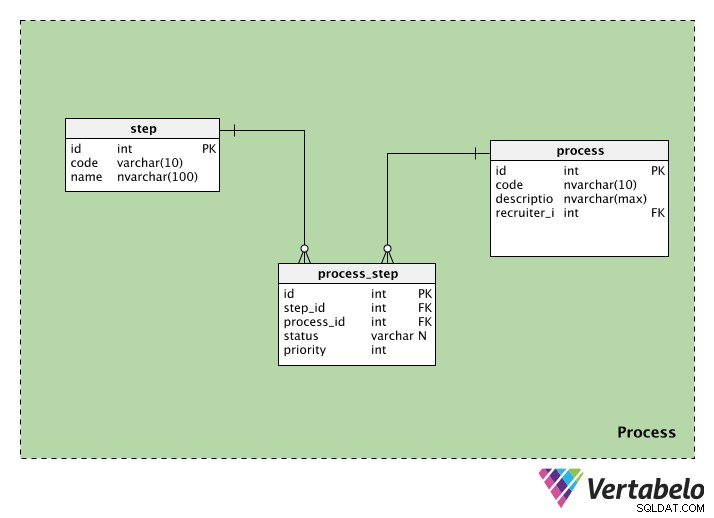
Der Process Tabelle speichert Informationen zu jedem Rekrutierungsprozess. Jeder Prozess hat eine spezielle ID, einen Code und eine description dieses Prozesses. Wir haben auch die recruiter_id der Person, die das Verfahren einleitet.
Der step Die Tabelle enthält Informationen zu den Schritten, die während dieses Einstellungsprozesses durchlaufen wurden. Jeder Schritt hat eine id und einen code Name. Die Namensspalte kann Werte wie „Erstes Screening“, „schriftlicher Test“, „Personalinterview“ usw. enthalten
Da ein Prozess mehrere Schritte haben kann und ein Schritt Teil vieler Prozesse sein kann, benötigen wir eine Nachschlagetabelle. Der process_step Tabelle enthält Informationen zu jedem Schritt (in step_id ) und den Prozess, zu dem es gehört (in process_id ). Wir haben auch einen Status, der uns den Status dieses Schritts in diesem Prozess mitteilt; Dies kann NULL sein, wenn der Schritt noch nicht gestartet wurde. Schließlich haben wir eine priority , die uns sagt, in welcher Reihenfolge die Schritte ausgeführt werden sollen. Die Schritte mit der höchsten priority value wird zuerst ausgeführt.
Jobs
Als nächstes haben wir die Jobs Themenbereich, in dem alle Informationen zu den Stellen gespeichert sind, für die wir rekrutieren. Das Schema für diese Kategorie sieht folgendermaßen aus:
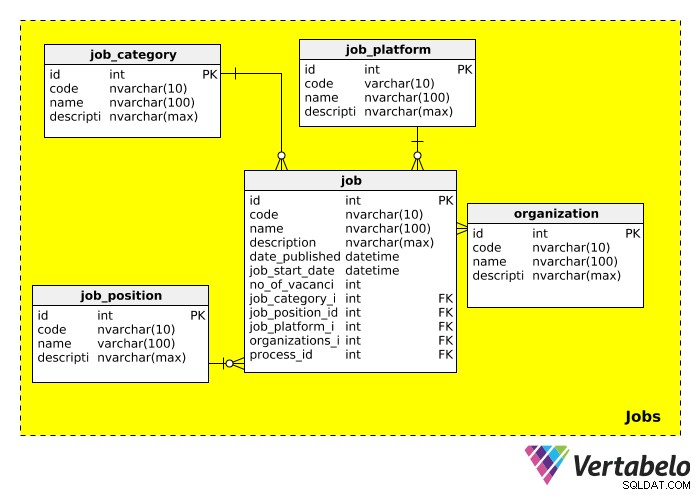
Lassen Sie uns jede der Tabellen im Detail erklären.
Die job_category Die Tabelle beschreibt grob die Art der Tätigkeit. Wir könnten Berufskategorien wie „IT“, „Management“, „Finanzen“, „Bildung“ usw. erwarten
Die job_position Tabelle enthält die eigentliche Berufsbezeichnung. Da ein Titel für mehrere Stellen ausgeschrieben werden kann (z. B. „IT-Manager“, „Vertriebsleiter“), haben wir eine separate Tabelle für Stellenangebote erstellt. Wir könnten Werte wie „IT Team Lead“, „Vice President“ und „Manager“ in dieser Tabelle erwarten.
Die job_platform Tabelle bezieht sich auf das Medium, mit dem die Stellenausschreibung beworben wird. Beispielsweise könnte ein Job auf Facebook, einer Online-Jobbörse oder in einer Lokalzeitung veröffentlicht werden. Ein Link zu dieser Stellenausschreibung kann in der description hinzugefügt werden Feld.
Die organization Tabelle speichert Informationen über alle Unternehmen, die diese Datenbank jemals im Rahmen ihres Einstellungsprozesses verwendet haben. Natürlich ist diese Tabelle wichtig, wenn für ein anderes Unternehmen geworben wird.
Die letzte Tabelle in diesem Themenbereich, job , enthält die eigentliche Stellenbeschreibung. Die meisten Attribute sind selbsterklärend. Wir sollten beachten, dass diese Tabelle viele Fremdschlüssel enthält, was bedeutet, dass sie verwendet werden kann, um die Kategorie, die Position, die Plattform, die einstellende Organisation und den Rekrutierungsprozess im Zusammenhang mit dieser Stellenausschreibung nachzuschlagen.
Bewerbung, Bewerber und Dokumente
Der dritte Teil des Schemas besteht aus den Tabellen, die Informationen über Stellenbewerber, ihre Bewerbungen und alle mit den Bewerbungen gelieferten Dokumente speichern.
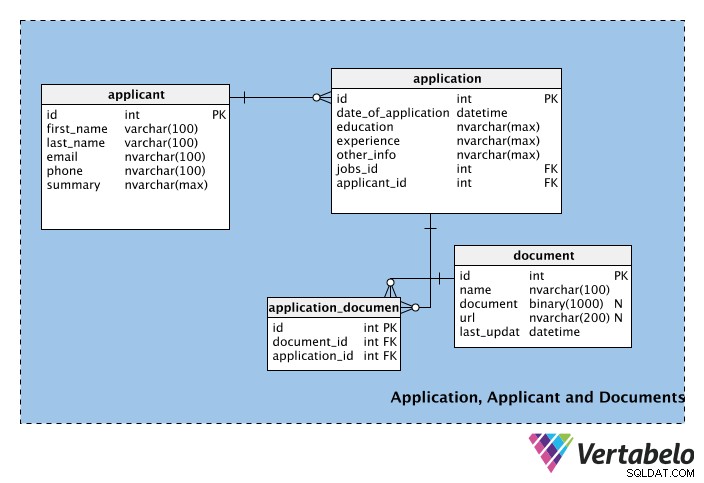
Die erste Tabelle, applicant , speichert die persönlichen Daten von Bewerbern wie Vorname, Nachname, E-Mail, Telefonnummer usw. Das Zusammenfassungsfeld kann verwendet werden, um ein Kurzprofil des Bewerbers (d. h. einen Absatz) zu speichern.
Die nächste Tabelle enthält Informationen für jede application , einschließlich seines Datums. Die Tabelle enthält auch die experience und education Säulen. Diese Spalten könnten Teil des applicant Tabelle, aber ein Bewerber kann oder möchte nicht bei jeder Bewerbung, die er einreicht, einen bestimmten Bildungsabschluss oder eine bestimmte Berufserfahrung angeben. Daher sind diese Spalten Teil der application Tisch. Die other_info Spalte speichert alle anderen anwendungsbezogenen Informationen. In der application In der Tabelle jobs_id und Bewerber_ID handelt es sich um Fremdschlüssel aus den Job- bzw. Bewerbertabellen.
Da es für jede Stelle mehrere Bewerbungen geben kann, aber jede Bewerbung nur für eine Stelle gilt, besteht zwischen den jobs und applications Tische. Ebenso kann ein Bewerber mehrere Bewerbungen (d. h. für verschiedene Stellen) einreichen, aber jede Bewerbung stammt nur von einem Teilnehmer; wir haben eine weitere 1:n-Beziehung zwischen den applicants und applications Tabellen, um dies zu handhaben.
Das document table verwaltet die Nachweise, die Bewerber ihrer Bewerbung beifügen können. Dies können Lebensläufe, Lebensläufe, Referenzschreiben, Anschreiben usw. sein. Beachten Sie, dass diese Tabelle eine binäre Spalte mit dem Namen Dokument enthält, in der die Datei im Binärformat gespeichert wird. In der url kann ein Link zum Dokument hinterlegt werden Feld; Die Namensspalte speichert den Namen des Dokuments und last_update bezeichnet die neueste vom Antragsteller hochgeladene Version. Beachten Sie, dass beide document und url sind nullable; keines ist obligatorisch, und ein Bewerber kann wählen, ob er eine oder beide Methoden verwenden möchte, um Informationen zu seiner Bewerbung hinzuzufügen.
Nicht jeder Bewerbung wird ein Dokument beigefügt. Ein Dokument kann mehreren Bewerbungen beigefügt werden, und eine Bewerbung kann mehrere Belege enthalten. Das bedeutet, dass zwischen der application und document Tische. Zur Verwaltung dieser Beziehung wird die Nachschlagetabelle application_document wurde erstellt.
Tests und Interviews
Jetzt gehen wir zu den Tabellen über, in denen Informationen zu den Tests und Interviews im Zusammenhang mit dem Einstellungsprozess gespeichert sind.
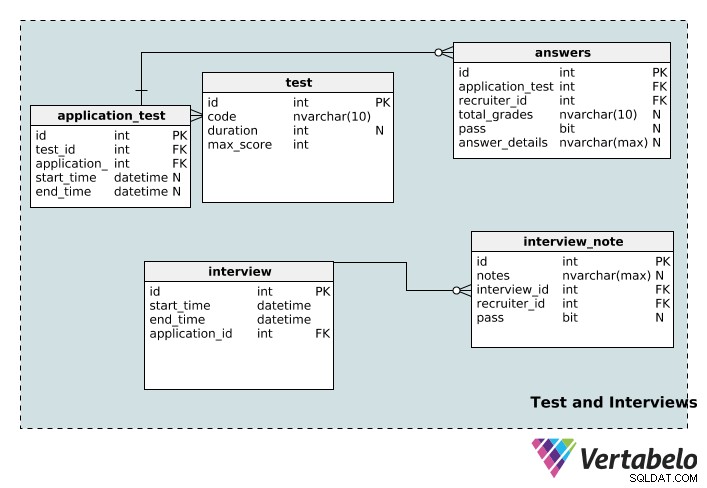
Der test Tabelle speichert Testdetails einschließlich ihrer eindeutigen id , code Name, seine duration in Minuten und das maximum Punktzahl für diesen Test möglich.
Eine Anwendung kann mehreren Tests zugeordnet werden und ein Test kann mehreren Anwendungen zugeordnet werden. Auch hier haben wir eine Nachschlagetabelle, um diese Beziehung zu implementieren:application_test . Die start_time und end_time Spalten sind nullable, da ein Test möglicherweise keine bestimmte Dauer, Startzeit oder Endzeit hat.
Ein Test kann von mehreren Personalvermittlern bewertet werden und ein Personalvermittler kann mehrere Tests bewerten. Die answers table ist der Tisch, der dies ermöglicht. Die total_grades Spalte zeigt an, wie gut der Kandidat beim Test abgeschnitten hat, und die Pass-Spalte gibt einfach an, ob diese Person bestanden oder nicht bestanden hat. Einzelheiten zu jedem einzelnen Test werden in den answer_details aufgezeichnet Säule. Beachten Sie, dass diese drei Spalten nullable sind; Ein Bewerbungstest kann einem Personalvermittler zugewiesen werden, der ihn noch nicht benotet hat. Darüber hinaus kann einem Personalvermittler ein Test zugewiesen werden, bevor er tatsächlich abgelegt wird.
Das interview Tabelle speichert grundlegende Informationen (die start_time , end_time , eine eindeutige id , und die relevante application_id ) für jedes Gespräch. Ein Vorstellungsgespräch kann nur einer Bewerbung zugeordnet werden. Andererseits kann eine Bewerbung mehrere Vorstellungsgespräche haben. Daher besteht zwischen der Bewerbungs- und der Interviewtabelle eine Eins-zu-Viele-Beziehung.
Ein Interview kann von mehreren Gutachtern durchgeführt werden, und ein Gutachter kann mehrere Interviews führen. Es ist eine weitere Viele-zu-Viele-Beziehung, also haben wir die Nachschlagetabelle interview_note . Es speichert Informationen über das Interview (in interview_id ), der Anwerber (in recruiter_id ) und die Notizen des Personalvermittlers zum Vorstellungsgespräch. Personalvermittler können in der Spalte „bestanden“ auch festhalten, ob der Bewerber das Vorstellungsgespräch bestanden hat, was nullable ist.
Recruiter Bewerbungsbewertung und -status
Der letzte Teil unseres Rekrutierungsmodells speichert Informationen über Personalvermittler, Bewerbungsstatus und Bewerbungsbewertungen.
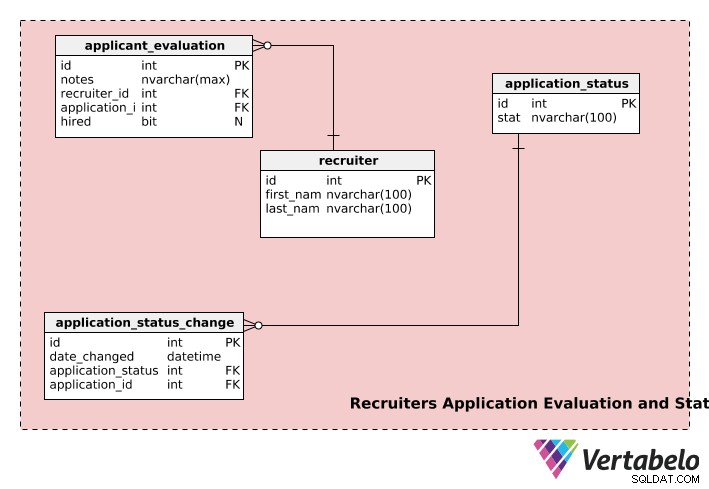
Die recruiters Tabelle speichert den first_name jedes Anwerbers , last_name , und eindeutige id Anzahl.
Die application_evaluation Tabelle enthält Informationen zu Anwendungsauswertungen. Zusätzlich zur application_id und recruiter_id , es enthält das Feedback des Personalvermittlers (in notes ) und die endgültige Einstellungsentscheidung, falls vorhanden, in hired . Eine Bewerbung kann von mehreren Personalvermittlern bewertet werden und ein Personalvermittler kann mehrere Bewerbungen bewerten, also sowohl der recruiter und die application Tabelle haben eine Eins-zu-Viele-Beziehung mit application_evaluation Tisch.
Eine Bewerbung kann im Einstellungsprozess mehrere Phasen durchlaufen, z.B. „nicht eingereicht“, „in Prüfung“, „Warten auf Entscheidung“, „Entscheidung getroffen“ usw. Eine Bewerbung hat den Status „nicht_eingereicht“, wenn der Benutzer eine Bewerbung gestartet, aber nicht zur Überprüfung an die Personalvermittler übermittelt hat. Sobald der Antrag eingereicht wurde, ändert sich der Status in „in Bearbeitung“ und so weiter. Der application_status Tabelle wird verwendet, um solche Informationen zu speichern.
Der application_status_change Tabelle wird verwendet, um eine Aufzeichnung der Statusänderungen für alle eingereichten Bewerbungen zu führen. Das date_changed Spalte speichert das Datum der Statusänderung. Diese Tabelle kann nützlich sein, wenn Sie die Bearbeitungszeit für jede Phase verschiedener Anwendungen analysieren möchten. Darüber hinaus kann der Status einer bestimmten Spalte mithilfe der application_id abgerufen werden Spalte aus application_status_change Tisch.
Ein einfacher Anwendungsfall für die Personalbeschaffung
Sehen wir uns an, wie unsere Datenbank den Rekrutierungsprozess unterstützen kann.
Angenommen, ein Unternehmen hat Sie beauftragt, einen IT-Manager mit Programmiererfahrung einzustellen. Unsere Datenbank kann uns helfen, eine solche Person einzustellen, indem sie die folgenden Schritte ausführt:
- Der erste Schritt besteht darin, einen neuen Einstellungsprozess zu starten. Dazu werden Daten in den
processundstepsTische. Ein Personalvermittler kann beliebig viele Schritte hinzufügen. - Während der obigen Aufgabe kann der Personalvermittler eine neue Stelle erstellen und die Details in
job,job_category,job_position, undorganizationTische. Abschließend wird eine Stellenanzeige in einer der unterjob_platformTabelle. - Als nächstes erstellen die Bewerber ein Profil, indem sie ihre Daten an den
applicantTisch. Dann starten sie eine neue Anwendung, indem sie weitere Daten in dieapplicationTabelle. - Antragsteller können ihren Bewerbungen auch Dokumente beifügen. Diese Daten werden im
documentundapplication_documentTabellen. - Wenn sich ein Nutzer auf mehr als eine Stelle bewerben möchte, wiederholt er die Schritte 3 und 4.
- Sobald die Bewerbung eingereicht wurde, wird der Status der Bewerbung auf „abgesendet“ (oder einen anderen vom Anwerber gewählten Statusnamen) gesetzt.
- Der Personalvermittler bewertet die Bewerbung und gibt sein Feedback in
application_evaluationTisch. Zu diesem Zeitpunkt enthält die eingestellte Spalte keine Informationen. - Sobald eine ausreichende Anzahl von Bewerbungen eingegangen ist, führt der Personalvermittler den nächsten Schritt aus, der im
process_stepTabelle. - Wenn der nächste Schritt darin besteht, eine Art Test durchzuführen, erstellt der Personalvermittler einen Test, indem er Daten zum
testTabelle. - Die in Schritt 9 erstellten Tests werden einer bestimmten Anwendung zugewiesen. Die Informationen, die jeden Test jeder Anwendung zuordnen, werden im
application_testTisch. Beachten Sie, dass sich der Status der Bewerbung in jeder Phase ständig ändert. Dies wird imapplication_status_changeTabelle. - Sobald der Bewerber den Test abgeschlossen hat, werden die Noten für jeden Bewerbungstest vom Personalvermittler bewertet und in die
answerTabelle. - Sobald der Test bestanden ist, der nächste Schritt von
process_stepTabelle wird ausgeführt. Nehmen wir an, der nächste Schritt ist das Vorstellungsgespräch. - Die Interviewdaten werden im
interviewTisch. Der Personalvermittler gibt seine Kommentare ein und sagt, ob die Person das Vorstellungsgespräch bestanden hat oder nicht. Dies wird in derinterview_noteTabelle. - Wenn der
ProcessTabelle enthält weitere Interview- und Testschritte, diese werden bis zum letzten Schritt ausgeführt. - Der letzte Schritt im
process_stepTabelle ist normalerweise die Einstellungsentscheidung. Wenn der Bewerber seine Tests und Vorstellungsgespräche besteht und das Unternehmen entscheidet, ihn einzustellen, werden die Daten in die Einstellungsspalte derapplication_evaluationTisch und die Person ist eingestellt.
Was halten Sie von unserem Datenmodell für das Rekrutierungssystem?
In diesem Artikel haben wir gesehen, wie man ein sehr einfaches Datenbankschema für ein Rekrutierungssystem erstellt. Wir haben das Schema in vier Kategorien eingeteilt und jede davon im Detail erklärt. Schließlich haben wir einen Anwendungsfall durchgeführt, um zu zeigen, dass unser Schema tatsächlich bei der Rekrutierung eines Mitarbeiters helfen kann.
Jobs im Bereich Datenbankdesign boomen. Möchten Sie Ihre Datenbankkenntnisse erweitern? Egal, ob Sie ein Neuling sind, der die SQL-Grundlagen lernen möchte, oder ein erfahrener Profi, der sich in das Erstellen von Tabellen in SQL | verzweigen möchte Interaktiver Kurs | Vertabelo Academy" target="_blank">Datenbankdesign finden Sie in den Selbstlernkursen von LearnSQL.com.