Ausführungspläne stellen eine reichhaltige Informationsquelle dar, die uns dabei helfen kann, Möglichkeiten zur Verbesserung der Leistung wichtiger Abfragen zu identifizieren. Die Leute suchen oft nach Dingen wie großen Scans und Lookups, um potenzielle Optimierungen des Datenzugriffspfads zu identifizieren. Diese Probleme können oft schnell gelöst werden, indem ein neuer Index erstellt oder ein bestehender Index um mehr eingeschlossene Spalten erweitert wird.
Wir können auch Post-Execution-Pläne verwenden, um die tatsächlichen mit den erwarteten Zeilenzahlen zwischen den Planbetreibern zu vergleichen. Wenn sich herausstellt, dass diese erheblich voneinander abweichen, können wir versuchen, dem Optimierer bessere statistische Informationen bereitzustellen, indem wir vorhandene Statistiken aktualisieren, neue Statistikobjekte erstellen, Statistiken zu berechneten Spalten verwenden oder vielleicht eine komplexe Abfrage in weniger komplexe Komponenten aufteilen Teile.
Darüber hinaus können wir auch teure Operationen im Plan betrachten, insbesondere speicherintensive Operationen wie Sortieren und Hashing. Das Sortieren kann manchmal durch Indizierungsänderungen vermieden werden. In anderen Fällen müssen wir die Abfrage möglicherweise umgestalten, indem wir eine Syntax verwenden, die einen Plan bevorzugt, der eine bestimmte gewünschte Reihenfolge beibehält.
Manchmal ist die Leistung auch nach Anwendung all dieser Leistungsoptimierungstechniken immer noch nicht gut genug. Ein möglicher nächster Schritt besteht darin, ein bisschen mehr über den Plan als Ganzes nachzudenken . Das bedeutet, einen Schritt zurückzutreten und zu versuchen, die vom Abfrageoptimierer gewählte Gesamtstrategie zu verstehen, um zu sehen, ob wir eine algorithmische Verbesserung identifizieren können.
Dieser Artikel untersucht diese letztere Art der Analyse anhand eines einfachen Beispielproblems zum Auffinden eindeutiger Spaltenwerte in einem mäßig großen Datensatz. Wie es oft bei analogen Problemen in der realen Welt der Fall ist, hat die interessierende Spalte im Vergleich zur Anzahl der Zeilen in der Tabelle relativ wenige eindeutige Werte. Diese Analyse besteht aus zwei Teilen:dem Erstellen der Beispieldaten und dem Schreiben der Distinct-Values-Abfrage selbst.
Erstellen der Beispieldaten
Um das einfachste mögliche Beispiel zu geben, hat unsere Testtabelle nur eine einzige Spalte mit einem gruppierten Index (diese Spalte enthält doppelte Werte, sodass der Index nicht als eindeutig deklariert werden kann):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
Um einige Zahlen aus der Luft zu holen, werden wir uns dafür entscheiden, zehn Millionen Zeilen zu laden insgesamt mit einer gleichmäßigen Verteilung über tausend verschiedene Werte . Eine gängige Technik zum Generieren solcher Daten besteht darin, einige Systemtabellen zu verknüpfen und die ROW_NUMBER anzuwenden Funktion. Wir werden auch den Modulo-Operator verwenden, um die generierten Zahlen auf die gewünschten eindeutigen Werte zu begrenzen:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Der geschätzte Ausführungsplan für diese Abfrage lautet wie folgt (klicken Sie ggf. auf das Bild, um es zu vergrößern):

Dies dauert ungefähr 30 Sekunden um die Beispieldaten auf meinem Laptop zu erstellen. Das ist keineswegs eine enorme Zeitspanne, aber es ist dennoch interessant zu überlegen, was wir tun könnten, um diesen Prozess effizienter zu gestalten …
Plananalyse
Wir beginnen damit, zu verstehen, wofür jede Operation im Plan da ist.
Der Abschnitt des Ausführungsplans rechts vom Segment-Operator befasst sich mit der Herstellung von Zeilen durch Kreuzfügen von Systemtabellen:

Der Segment-Operator ist vorhanden, falls die Fensterfunktion einen PARTITION BY hatte Klausel. Das ist hier nicht der Fall, aber es kommt trotzdem im Abfrageplan vor. Der Sequence Project-Operator generiert die Zeilennummern, und Top begrenzt die Planausgabe auf zehn Millionen Zeilen:

Der Berechnungsskalar definiert den Ausdruck, der die Modulo-Funktion anwendet und eins zum Ergebnis hinzufügt:

Auf der Registerkarte „Ausdrücke“ des Plan-Explorers können wir sehen, wie die Ausdrucksbezeichnungen „Sequence Project“ und „Compute Scalar“ zusammenhängen:

Dies gibt uns ein vollständigeres Gefühl für den Ablauf dieses Plans:Das Sequenzprojekt nummeriert die Zeilen und beschriftet den Ausdruck Expr1050; der Compute Scalar bezeichnet das Ergebnis der Modulo- und Plus-Eins-Berechnung als Expr1052 . Beachten Sie auch die implizite Konvertierung im Compute Scalar-Ausdruck. Die Spalte der Zieltabelle ist vom Typ Integer, während ROW_NUMBER -Funktion erzeugt einen Bigint, daher ist eine einschränkende Konvertierung erforderlich.
Der nächste Operator im Plan ist ein Sort. Gemäß den Kostenschätzungen des Abfrageoptimierers ist dies voraussichtlich der teuerste Vorgang (88,1 % geschätzt ):

Es ist möglicherweise nicht sofort ersichtlich, warum dieser Plan eine Sortierung enthält, da es in der Abfrage keine explizite Sortieranforderung gibt. Die Sortierung wird dem Plan hinzugefügt, um sicherzustellen, dass die Zeilen beim Clustered Index Insert-Operator in der Reihenfolge der Clustered-Indizes ankommen. Dies fördert sequentielles Schreiben, vermeidet Seitenaufteilung und ist eine der Voraussetzungen für minimal protokolliertes INSERT Operationen.
Das sind alles potenziell gute Dinge, aber das Sortieren selbst ist ziemlich teuer. In der Tat zeigt die Überprüfung des Ausführungsplans nach der Ausführung ("tatsächlich"), dass Sort auch zur Ausführungszeit keinen Speicher mehr hatte und in die physische tempdb überlaufen musste Festplatte:

Der Sortierüberlauf tritt auf, obwohl die geschätzte Anzahl von Zeilen genau richtig ist und obwohl der Abfrage der gesamte angeforderte Speicher gewährt wurde (wie in den Planeigenschaften für den Stamm INSERT zu sehen ist Knoten):

Sortierüberläufe werden auch durch das Vorhandensein von IO_COMPLETION angezeigt Wartezeiten in der Wartestatistik des Plan Explorer PRO:

Beachten Sie schließlich für diesen Abschnitt zur Plananalyse die DML Request Sort -Eigenschaft des Clustered Index Insert-Operators auf true gesetzt ist:

Dieses Flag zeigt an, dass der Optimierer den Teilbaum unter dem Insert benötigt, um Zeilen in sortierter Reihenfolge nach Indexschlüsseln bereitzustellen (daher die Notwendigkeit für den problematischen Sort-Operator).
Vermeiden der Sortierung
Jetzt wissen wir warum das Sortieren erscheint, können wir testen, was passiert, wenn wir es entfernen. Es gibt Möglichkeiten, wie wir die Abfrage umschreiben könnten, um den Optimierer zu „täuschen“, dass er denkt, dass weniger Zeilen eingefügt würden (also würde sich das Sortieren nicht lohnen), aber eine schnelle Möglichkeit, die Sortierung direkt zu vermeiden (nur für experimentelle Zwecke), ist die Verwendung eines undokumentierten Trace-Flags 8795. Dies setzt die DML Request Sort -Eigenschaft auf „false“ setzen, sodass Zeilen nicht mehr in gruppierter Schlüsselreihenfolge zum Clustered Index Insert gelangen müssen:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Der neue Abfrageplan nach der Ausführung lautet wie folgt (zum Vergrößern auf das Bild klicken):

Der Sort-Operator ist weg, aber die neue Abfrage wird länger als 50 Sekunden ausgeführt (im Vergleich zu 30 Sekunden Vor). Dafür gibt es mehrere Gründe. Erstens verlieren wir jede Möglichkeit minimal protokollierter Einfügungen, da diese sortierte Daten erfordern (DML Request Sort =true). Zweitens wird während des Einfügens eine große Anzahl "schlechter" Seitenteilungen auftreten. Falls dies nicht intuitiv erscheint, denken Sie daran, dass obwohl die ROW_NUMBER Funktion Zeilen sequentiell nummeriert, besteht der Effekt des Modulo-Operators darin, dem Clustered Index Insert eine sich wiederholende Zahlenfolge von 1 bis 1000 zu präsentieren.
Das gleiche grundlegende Problem tritt auf, wenn wir T-SQL-Tricks verwenden, um die erwartete Zeilenanzahl zu verringern, um die Sortierung zu vermeiden, anstatt das nicht unterstützte Trace-Flag zu verwenden.
Vermeidung der Sorte II
Wenn wir den Plan als Ganzes betrachten, scheint es klar, dass wir Zeilen so generieren möchten, dass eine explizite Sortierung vermieden wird, aber dennoch die Vorteile einer minimalen Protokollierung und der Vermeidung von fehlerhaften Seitenaufteilungen genutzt werden. Einfach ausgedrückt:Wir wollen einen Plan, der Zeilen in gruppierter Schlüsselreihenfolge darstellt, aber ohne Sortierung.
Bewaffnet mit dieser neuen Einsicht können wir unsere Frage anders ausdrücken. Die folgende Abfrage generiert jede Zahl von 1 bis 1000 und Kreuzverknüpfungen, die mit 10.000 Zeilen festgelegt werden, um den erforderlichen Duplizierungsgrad zu erzeugen. Die Idee ist, einen Einfügungssatz zu erstellen, der 10.000 Zeilen mit der Nummerierung „1“ und dann 10.000 Zeilen mit der Nummerierung „2“ enthält … und so weiter.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Leider erzeugt der Optimierer immer noch einen Plan mit einer Sortierung:

Zur Verteidigung des Optimierers gibt es hier nicht viel zu sagen, dies ist nur ein dummer Plan. Es hat sich entschieden, 10.000 Zeilen zu generieren und dann diejenigen mit Zahlen von 1 bis 1000 zu verknüpfen. Dadurch kann die natürliche Reihenfolge der Zahlen nicht beibehalten werden, sodass die Sortierung nicht vermieden werden kann.
Sortierung vermeiden – Endlich!
Die Strategie, die der Optimierer verpasst hat, ist, die Zahlen 1…1000 zuerst zu nehmen , und verbinden Sie jede Zahl mit 10.000 Reihen (machen Sie 10.000 Kopien jeder Zahl in Folge). Der erwartete Plan würde eine Sortierung vermeiden, indem er eine Kreuzverbindung mit verschachtelten Schleifen verwendet, die die Reihenfolge beibehält der Zeilen auf der äußeren Eingabe.
Wir können dieses Ergebnis erreichen, indem wir den Optimierer zwingen, auf die abgeleiteten Tabellen in der in der Abfrage angegebenen Reihenfolge zuzugreifen, indem wir FORCE ORDER verwenden Abfragehinweis:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Schließlich bekommen wir den Plan, nach dem wir gesucht haben:
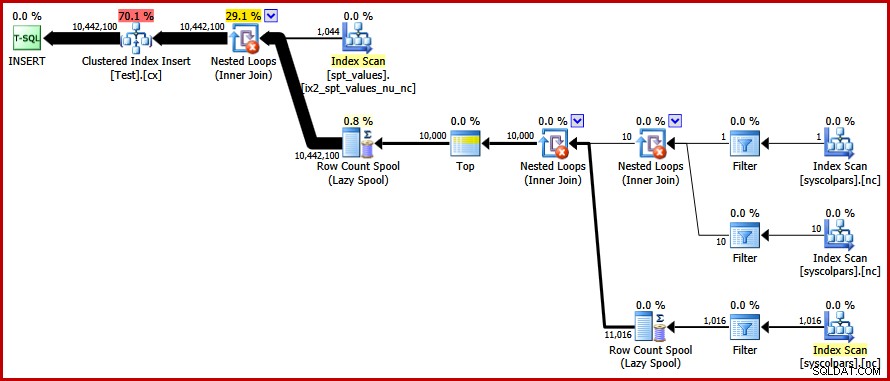
Dieser Plan vermeidet eine explizite Sortierung, vermeidet aber dennoch "schlechte" Seitenteilungen und ermöglicht minimal protokollierte Einfügungen in den gruppierten Index (vorausgesetzt, die Datenbank verwendet nicht den FULL Wiederherstellungsmodell). Es lädt alle zehn Millionen Zeilen in etwa 9 Sekunden auf meinem Laptop (mit einer einzigen 7200 U / min SATA-Festplatte). Dies stellt einen deutlichen Effizienzgewinn über die 30–50 Sekunden dar verstrichene Zeit vor dem Neuschreiben.
Die eindeutigen Werte finden
Nachdem wir die Beispieldaten erstellt haben, können wir uns dem Schreiben einer Abfrage zuwenden, um die unterschiedlichen Werte in der Tabelle zu finden. Eine natürliche Möglichkeit, diese Anforderung in T-SQL auszudrücken, ist wie folgt:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Der Ausführungsplan ist erwartungsgemäß sehr einfach:

Dies dauert etwa 2900 ms um auf meinem Rechner zu laufen und erfordert 43.406 logische Lesevorgänge:

Entfernen des MAXDOP (1) Abfragehinweis generiert einen parallelen Plan:

Dies ist in etwa 1500 ms abgeschlossen (aber mit 8.764 ms verbrauchter CPU-Zeit) und 43.804 logische Lesevorgänge:

Dieselben Pläne und Leistungen ergeben sich, wenn wir GROUP BY verwenden statt DISTINCT .
Ein besserer Algorithmus
Die oben gezeigten Abfragepläne lesen alle Werte aus der Basistabelle und verarbeiten sie über ein Stream-Aggregat. Betrachtet man die Aufgabe als Ganzes, scheint es ineffizient, alle 10 Millionen Zeilen zu scannen, wenn man weiß, dass es relativ wenige eindeutige Werte gibt.
Eine bessere Strategie könnte darin bestehen, den niedrigsten Einzelwert in der Tabelle zu finden, dann den nächsthöheren und so weiter, bis uns die Werte ausgehen. Entscheidend ist, dass sich dieser Ansatz für die Suche nach Singletons im Index eignet, anstatt jede Zeile zu scannen.
Wir können diese Idee in einer einzigen Abfrage mit einem rekursiven CTE implementieren, bei dem der Ankerteil den niedrigsten findet eindeutigen Wert, dann findet der rekursive Teil den nächsten eindeutigen Wert und so weiter. Ein erster Versuch, diese Abfrage zu schreiben, ist:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Leider lässt sich diese Syntax nicht kompilieren:

Ok, Aggregatfunktionen sind also nicht erlaubt. Anstatt MIN zu verwenden , können wir die gleiche Logik mit TOP (1) schreiben mit einem ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Immer noch keine Freude.
Es stellt sich heraus, dass wir diese Einschränkungen umgehen können, indem wir den rekursiven Teil neu schreiben, um die Kandidatenzeilen in der erforderlichen Reihenfolge zu nummerieren und dann nach der Zeile mit der Nummer „eins“ zu filtern. Das mag etwas umständlich erscheinen, aber die Logik ist genau die gleiche:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Diese Abfrage tut es kompilieren und erzeugt den folgenden Post-Execution-Plan:

Beachten Sie den Top-Operator im rekursiven Teil des Ausführungsplans (hervorgehoben). Wir können kein T-SQL TOP schreiben im rekursiven Teil eines rekursiven allgemeinen Tabellenausdrucks, aber das bedeutet nicht, dass der Optimierer keinen verwenden kann! Der Optimierer führt das Top ein, basierend auf Überlegungen zur Anzahl der Zeilen, die er überprüfen muss, um diejenige mit der Nummer '1' zu finden.
Die Leistung dieses (nicht parallelen) Plans ist viel besser als der Stream Aggregate-Ansatz. Es ist in etwa 50 ms abgeschlossen , mit 3007 logische Lesevorgänge gegen die Quelltabelle (und 6001 Zeilen, die aus der Spool-Arbeitstabelle gelesen wurden), verglichen mit dem vorherigen Bestwert von 1500 ms (8764 ms CPU-Zeit bei DOP 8) und 43.804 logische Lesevorgänge:


Schlussfolgerung
Es ist nicht immer möglich, Durchbrüche in der Abfrageleistung zu erzielen, indem einzelne Elemente des Abfrageplans allein betrachtet werden. Manchmal müssen wir die Strategie hinter dem gesamten Ausführungsplan analysieren und dann quer denken, um einen effizienteren Algorithmus und eine effizientere Implementierung zu finden.