Hinweis:Dieser Beitrag wurde ursprünglich nur in unserem eBook High Performance Techniques for SQL Server, Band 2 veröffentlicht. Sie können sich hier über unsere eBooks informieren.
Zusammenfassung:Dieser Artikel untersucht ein überraschendes Verhalten von INSTEAD OF-Triggern und enthüllt einen schwerwiegenden Fehler bei der Kardinalitätsschätzung in SQL Server 2014.
Trigger und Zeilenversionierung
Nur DML-AFTER-Trigger verwenden Zeilenversionierung (ab SQL Server 2005), um die eingefügten bereitzustellen und gelöscht Pseudotabellen innerhalb einer Triggerprozedur. Dieser Punkt wird in weiten Teilen der offiziellen Dokumentation nicht deutlich gemacht. An den meisten Stellen sagt die Dokumentation einfach, dass die Zeilenversionierung verwendet wird, um die eingefügten zu erstellen und gelöscht Tabellen in Triggern ohne Qualifizierung (Beispiele unten):
Ressourcennutzung für die Zeilenversionierung
Zeilenversionsbasierte Isolationsstufen verstehen
Trigger-Ausführung beim Massenimport von Daten steuern
Vermutlich wurden die Originalversionen dieser Einträge geschrieben, bevor INSTEAD OF-Trigger zum Produkt hinzugefügt und nie aktualisiert wurden. Entweder das, oder es ist ein einfaches (aber wiederholtes) Versehen.
Wie auch immer, die Art und Weise, wie die Zeilenversionierung mit AFTER-Triggern funktioniert, ist recht intuitiv. Diese Trigger werden nach ausgelöst Die fraglichen Änderungen wurden durchgeführt, daher ist es leicht zu erkennen, wie das Verwalten von Versionen der geänderten Zeilen es der Datenbank-Engine ermöglicht, die eingefügten bereitzustellen und gelöscht Pseudo-Tabellen. Die gelöschte Pseudo-Tabelle wird aus Versionen der betroffenen Zeilen erstellt, bevor die Änderungen stattfanden; die eingefügt Pseudo-Tabelle wird aus den Versionen der betroffenen Zeilen zum Zeitpunkt des Starts der Trigger-Prozedur gebildet.
Statt Auslöser
INSTEAD OF-Trigger sind anders, da diese Art von DML-Trigger vollständig ersetzt die ausgelöste Aktion. Die eingefügte und gelöscht Pseudo-Tabellen stellen jetzt Änderungen dar, die hätten gemacht worden, wäre die auslösende Anweisung tatsächlich ausgeführt worden. Die Zeilenversionierung kann für diese Trigger nicht verwendet werden, da definitionsgemäß keine Änderungen vorgenommen wurden. Wenn also keine Zeilenversionen verwendet werden, wie macht SQL Server das?
Die Antwort lautet, dass SQL Server den Ausführungsplan für die auslösende DML-Anweisung ändert, wenn ein INSTEAD OF-Trigger vorhanden ist. Anstatt die betroffenen Tabellen direkt zu ändern, schreibt der Ausführungsplan Informationen über die Änderungen in eine verborgene Arbeitstabelle. Diese Arbeitstabelle enthält alle Daten, die zum Durchführen der ursprünglichen Änderungen erforderlich sind, die Art der Änderung, die für jede Zeile durchgeführt werden soll (Löschen oder Einfügen), sowie alle Informationen, die im Trigger für eine OUTPUT-Klausel benötigt werden.
Ausführungsplan ohne Trigger
Um all dies in Aktion zu sehen, führen wir zunächst einen einfachen Test ohne einen INSTEAD OF-Trigger durch:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Der Ausführungsplan für das Löschen ist sehr einfach:
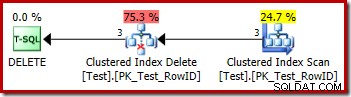
Jede qualifizierte Zeile wird direkt an einen Clustered Index Delete-Operator übergeben, der sie löscht. Ganz einfach.
Ausführungsplan mit einem INSTEAD OF-Trigger
Lassen Sie uns nun den Test so ändern, dass er einen INSTEAD OF DELETE-Trigger enthält (einen, der der Einfachheit halber nur dieselbe Löschaktion durchführt):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Der Ausführungsplan für das DELETE ist jetzt ganz anders:
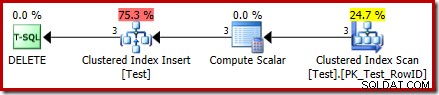
Der Clustered Index Delete Operator wurde durch einen Clustered Index Insert ersetzt . Dies ist die Einfügung in die verborgene Arbeitstabelle, die (in der Darstellung des öffentlichen Ausführungsplans) in den Namen der vom Löschvorgang betroffenen Basistabelle umbenannt wird. Die Umbenennung erfolgt, wenn der XML-Showplan aus der internen Darstellung des Ausführungsplans generiert wird, sodass es keine dokumentierte Möglichkeit gibt, die verborgene Arbeitstabelle anzuzeigen.
Als Ergebnis dieser Änderung scheint der Plan daher eine Einfügung durchzuführen in die Basistabelle zum Löschen Reihen daraus. Das ist verwirrend, offenbart aber zumindest das Vorhandensein eines INSTEAD OF-Triggers. Das Ersetzen des Insert-Operators durch einen Delete-Operator könnte noch verwirrender sein. Vielleicht wäre das Ideal ein neues grafisches Symbol für eine INSTEAD OF-Trigger-Arbeitstabelle? Wie auch immer, es ist, was es ist.
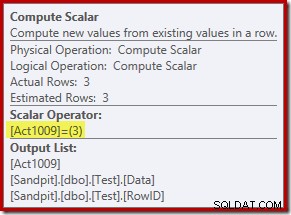
Der neue Compute Scalar-Operator definiert die Art der Aktion, die für jede Zeile ausgeführt wird. Dieser Aktionscode ist eine Ganzzahl mit folgenden Bedeutungen:
- 3 =LÖSCHEN
- 4 =EINFÜGEN
- 259 =DELETE in einem MERGE-Plan
- 260 =INSERT in einem MERGE-Plan
Für diese Abfrage ist die Aktion eine Konstante 3, was bedeutet, dass jede Zeile gelöscht werden soll :
Aktionen aktualisieren
Übrigens ersetzt ein INSTEAD OF UPDATE-Ausführungsplan einen einzelnen Update-Operator durch zwei Clustered Index Inserts in dieselbe versteckte Arbeitstabelle – eine für die eingefügte Pseudo-Tabellenzeilen und eine für die gelöschten Pseudotabellenzeilen. Ein beispielhafter Ausführungsplan:

Ein MERGE, das ein UPDATE durchführt, erzeugt aus ähnlichen Gründen auch einen Ausführungsplan mit zwei Einfügungen in dieselbe Basistabelle:

Der Trigger-Ausführungsplan
Der Ausführungsplan für den Abzugskörper hat auch einige interessante Features:
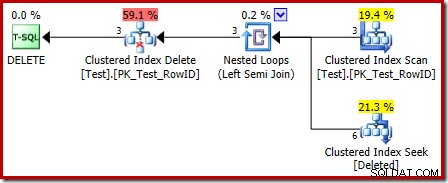
Als Erstes fällt auf, dass das für die gelöschte Tabelle verwendete grafische Symbol nicht dasselbe ist wie das Symbol, das in AFTER-Trigger-Plänen verwendet wird:
Die Darstellung im INSTEAD OF-Triggerplan ist eine Clustered-Index-Suche. Das zugrunde liegende Objekt ist dieselbe interne Arbeitstabelle, die wir zuvor gesehen haben, obwohl sie hier gelöscht heißt anstatt den Basistabellennamen zu erhalten, vermutlich für eine gewisse Konsistenz mit AFTER-Triggern.
Der Suchvorgang auf dem gelöschten table ist möglicherweise nicht das, was Sie erwartet haben (wenn Sie eine Suche auf RowID erwartet haben):
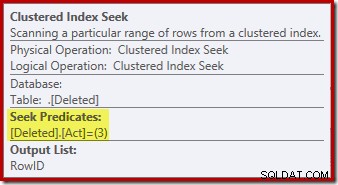
Diese „Suche“ gibt alle Zeilen aus der Arbeitstabelle zurück, die einen Aktionscode von 3 (Löschen) haben, wodurch sie genau dem Gelöschten Scan entspricht Operator, der in AFTER-Trigger-Plänen zu sehen ist. Dieselbe interne Arbeitstabelle wird verwendet, um Zeilen für beide eingefügte zu halten und gelöscht Pseudotabellen in INSTEAD OF-Triggern. Das Äquivalent eines eingefügten Scans ist eine Suche nach Aktionscode 4 (was in einem Löschen möglich ist auslösen, aber das Ergebnis ist immer leer). Es gibt keine Indizes auf der internen Arbeitstabelle außer dem nicht eindeutigen gruppierten Index auf der Aktion Spalte allein. Außerdem sind diesem internen Index keine Statistiken zugeordnet.
Bei der bisherigen Analyse fragen Sie sich möglicherweise, wo die Verknüpfung zwischen den RowID-Spalten durchgeführt wird. Dieser Vergleich tritt beim Nested Loops Left Semi Join-Operator als Restprädikat auf:
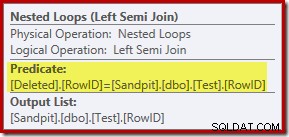
Nun, da wir wissen, dass die „Suche“ effektiv ein vollständiger Scan der gelöschten ist Tabelle scheint der vom Abfrageoptimierer gewählte Ausführungsplan ziemlich ineffizient zu sein. Der Gesamtfluss des Ausführungsplans besteht darin, dass jede Zeile aus der Testtabelle möglicherweise mit dem gesamten Satz von gelöschten verglichen wird Zeilen, was sehr nach einem kartesischen Produkt klingt.
Die Rettung besteht darin, dass der Join ein Semi-Join ist, was bedeutet, dass der Vergleichsprozess für eine bestimmte Testzeile stoppt, sobald die erste gelöscht wird Zeile erfüllt das Restprädikat. Dennoch erscheint die Strategie merkwürdig. Vielleicht wäre der Ausführungsplan besser, wenn die Testtabelle mehr Zeilen enthalten würde?
Test mit 1.000 Zeilen auslösen
Das folgende Skript kann verwendet werden, um den Trigger mit einer größeren Anzahl von Zeilen zu testen. Wir beginnen mit 1.000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Der Ausführungsplan für den Trigger-Body lautet jetzt:
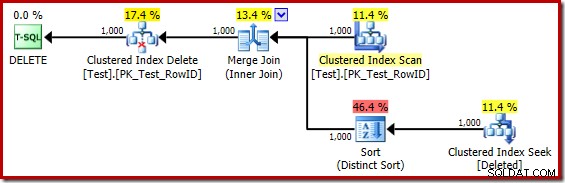
Wenn man den (irreführenden) Clustered Index Seek gedanklich durch einen gelöschten Scan ersetzt, sieht der Plan im Allgemeinen ziemlich gut aus. Der Optimierer hat einen Eins-zu-Vielen-Merge-Join anstelle eines Nested-Loops-Semi-Joins gewählt, was vernünftig erscheint. The Distinct Sort ist jedoch eine merkwürdige Ergänzung:
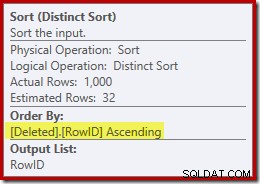
Diese Sortierung erfüllt zwei Funktionen. Erstens versorgt es den Merge-Join mit der sortierten Eingabe, die es benötigt, was fair genug ist, da es keinen Index in der internen Arbeitstabelle gibt, um die erforderliche Reihenfolge bereitzustellen. Das zweite, was die Sortierung tut, ist die Unterscheidung nach RowID. Dies mag seltsam erscheinen, da RowID der Primärschlüssel der Basistabelle ist.
Das Problem ist, dass Zeilen in der gelöschten Tabelle sind einfach Kandidatenzeilen, die von der ursprünglichen DELETE-Abfrage identifiziert wurden. Im Gegensatz zu einem AFTER-Trigger wurden diese Zeilen noch nicht auf Einschränkungen oder Schlüsselverletzungen überprüft, sodass der Abfrageprozessor keine Garantie dafür hat, dass sie tatsächlich eindeutig sind.
Im Allgemeinen ist dies ein sehr wichtiger Punkt, den Sie bei INSTEAD OF-Triggern beachten sollten:Es gibt keine Garantie dafür, dass die bereitgestellten Zeilen eine der Einschränkungen der Basistabelle erfüllen (einschließlich NOT NULL). Dies ist nicht nur wichtig, damit sich der Trigger-Autor daran erinnert; es schränkt auch die Vereinfachungen und Transformationen ein, die der Abfrageoptimierer durchführen kann.
Ein zweites Problem, das oben in den Sort-Eigenschaften gezeigt, aber nicht hervorgehoben wird, ist, dass die Ausgabeschätzung nur 32 Zeilen beträgt. Der internen Arbeitstabelle sind keine Statistiken zugeordnet, daher schätzt der Optimierer bei der Wirkung der Distinct-Operation. Wir „wissen“, dass die RowID-Werte eindeutig sind, aber ohne konkrete Informationen zum Fortfahren macht der Optimierer eine schlechte Schätzung. Dieses Problem wird uns im nächsten Test erneut verfolgen.
Trigger-Test mit 5.000 Zeilen
Ändern Sie nun das Testskript, um 5.000 Zeilen zu generieren:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Der Trigger-Ausführungsplan ist:
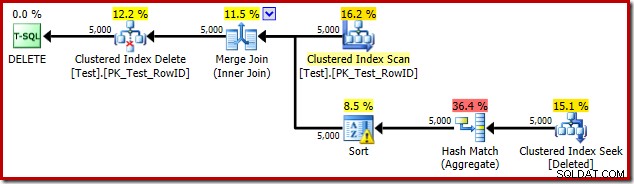
Diesmal hat der Optimierer entschieden, die Distinct- und Sort-Operationen aufzuteilen. Der Distinct auf RowID wird durch den Operator Hash Match (Aggregate) durchgeführt:
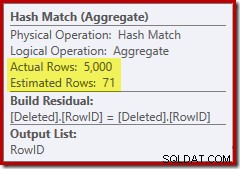
Beachten Sie, dass die Schätzung des Optimierers für die Ausgabe 71 Zeilen beträgt. Tatsächlich überleben alle 5.000 Zeilen die Unterscheidung, da RowID eindeutig ist. Die ungenaue Schätzung bedeutet, dass der Sortierung ein unangemessener Bruchteil der Abfragespeicherzuteilung zugewiesen wird, was letztendlich zu tempdb führt :
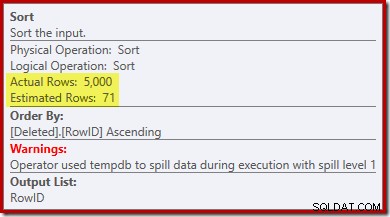
Dieser Test muss auf SQL Server 2012 oder höher durchgeführt werden, um die Sortierwarnung im Ausführungsplan zu sehen. In früheren Versionen enthält der Plan keine Informationen über Verschüttungen – ein Profiler-Trace für das Sort Warnings-Ereignis wäre erforderlich, um es aufzudecken (und Sie müssten das irgendwie mit der Quellabfrage korrelieren).
Trigger-Test mit 5.000 Zeilen auf SQL Server 2014
Wenn der vorherige Test auf SQL Server 2014 wiederholt wird, in einer Datenbank, die auf Kompatibilitätsgrad 120 eingestellt ist, sodass der neue Kardinalitätsschätzer (CE) verwendet wird, ist der Trigger-Ausführungsplan wieder anders:
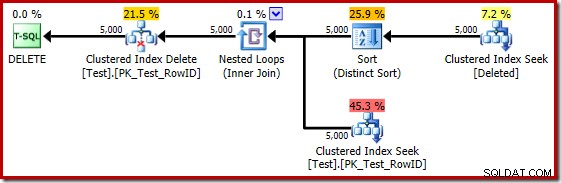
In gewisser Weise scheint dieser Ausführungsplan eine Verbesserung zu sein. Die (unnötige) eindeutige Sortierung ist immer noch vorhanden, aber die Gesamtstrategie scheint natürlicher zu sein:für jeden eindeutigen Kandidaten RowID in der gelöschten Tabelle, verknüpfen Sie sie mit der Basistabelle (um zu überprüfen, ob die Kandidatenzeile tatsächlich existiert) und löschen Sie sie dann.
Leider basiert der Plan 2014 auf schlechteren Kardinalitätsschätzungen als in SQL Server 2012. Umstellen des SQL Sentry-Plan-Explorers zur Anzeige der geschätzten Zeilenanzahl zeigt das Problem deutlich:
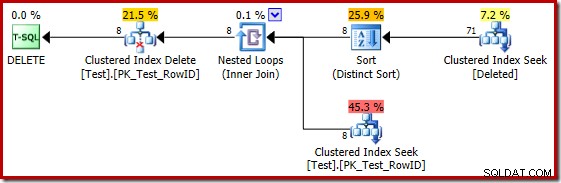
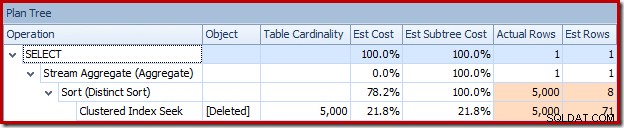
Der Optimierer wählte eine Nested-Loops-Strategie für den Join, weil er eine sehr kleine Anzahl von Zeilen in seiner obersten Eingabe erwartete. Das erste Problem tritt beim Clustered Index Seek auf. Der Optimierer weiß, dass die gelöschte Tabelle zu diesem Zeitpunkt 5.000 Zeilen enthält, wie wir sehen können, wenn wir zur Planbaumansicht wechseln und die optionale Tabellenkardinalitätsspalte hinzufügen (die standardmäßig enthalten sein soll):
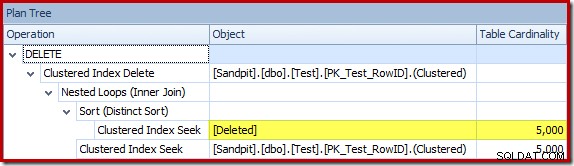
Der „alte“ Kardinalitätsschätzer in SQL Server 2012 und früher ist intelligent genug, um zu wissen, dass die „Suche“ in der internen Arbeitstabelle alle 5.000 Zeilen zurückgeben würde (also wählte er einen Merge-Join). Das neue CE ist nicht so schlau. Es sieht die Arbeitstabelle als 'Black Box' und schätzt die Auswirkung der Suche auf Aktionscode =3:
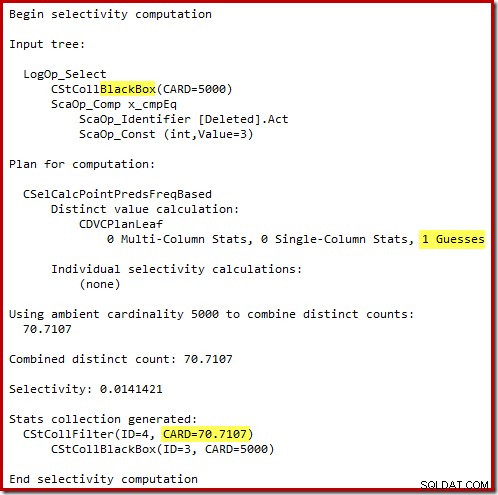
Die Schätzung von 71 Zeilen (aufgerundet) ist ein ziemlich miserables Ergebnis, aber der Fehler wird noch verstärkt, wenn das neue CE die Zeilen für die eindeutige Operation auf diesen 71 Zeilen schätzt:
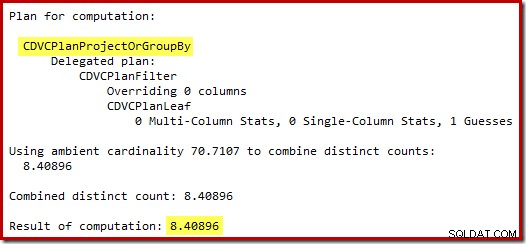
Basierend auf den erwarteten 8 Zeilen wählt der Optimierer die Nested-Loops-Strategie. Eine andere Möglichkeit, diese Schätzfehler zu sehen, besteht darin, die folgende Anweisung zum Trigger-Hauptteil hinzuzufügen (nur zu Testzwecken):
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Der Schätzplan zeigt die Schätzfehler deutlich:
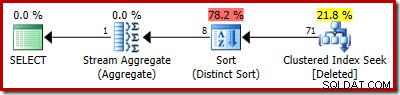
Der eigentliche Plan zeigt natürlich immer noch 5.000 Zeilen:
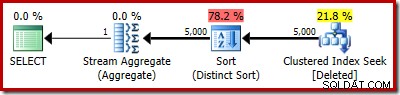
Oder Sie können Schätzung und Ist gleichzeitig in der Planbaumansicht vergleichen:
Eine Million Zeilen…
Die schlechten Schätzwerte bei Verwendung des Kardinalitätsschätzers von 2014 führen dazu, dass der Optimierer eine Nested-Loops-Strategie auswählt, selbst wenn die Testtabelle eine Million Zeilen enthält. Der neue CE 2014 geschätzt Plan für diesen Test ist:
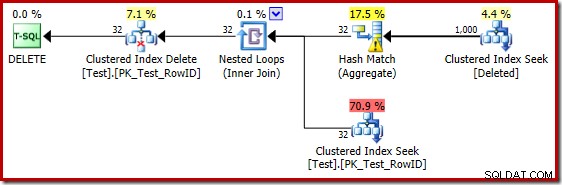
Die „Suche“ schätzt 1.000 Zeilen aus der bekannten Kardinalität von 1.000.000 und die eindeutige Schätzung beträgt 32 Zeilen. Der Plan nach der Ausführung zeigt die Auswirkung auf den für das Hash-Match reservierten Speicher:
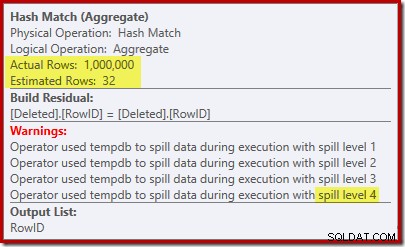
Da nur 32 Zeilen erwartet werden, gerät das Hash-Match in echte Schwierigkeiten, indem es seine Hash-Tabelle rekursiv verschüttet, bevor es schließlich abgeschlossen wird.
Abschließende Gedanken
Es stimmt zwar, dass ein Trigger niemals geschrieben werden sollte, um etwas zu tun, was mit deklarativer referenzieller Integrität erreicht werden kann, aber es ist auch wahr, dass ein gut geschriebener Trigger, der ein effizientes verwendet Ausführungsplan kann in der Leistung mit den Kosten für die Pflege eines zusätzlichen Nonclustered-Index vergleichbar sein.
Es gibt zwei praktische Probleme mit der obigen Aussage. Erstens (und beim besten Willen der Welt) schreiben die Leute nicht immer guten Triggercode. Zweitens kann es schwierig sein, unter allen Umständen einen guten Ausführungsplan vom Abfrageoptimierer zu erhalten. Die Natur von Triggern ist, dass sie mit einer breiten Palette von Eingabekardinalitäten und Datenverteilungen aufgerufen werden.
Sogar für AFTER-Trigger, das Fehlen von Indizes und Statistiken über die gelöschten und eingefügt Pseudotabellen bedeuten, dass die Planauswahl oft auf Vermutungen oder Fehlinformationen basiert. Selbst wenn anfänglich ein guter Plan ausgewählt wird, können spätere Ausführungen denselben Plan wiederverwenden, wenn eine Neukompilierung eine bessere Wahl gewesen wäre. Es gibt Möglichkeiten, die Einschränkungen zu umgehen, hauptsächlich durch die Verwendung von temporären Tabellen und expliziten Indizes/Statistiken, aber selbst dort ist große Sorgfalt erforderlich (da Trigger eine Form von gespeicherten Prozeduren sind).
Bei INSTEAD OF-Triggern können die Risiken sogar noch größer sein, da der Inhalt der eingefügten und gelöscht Tabellen sind nicht verifizierte Kandidaten – der Abfrageoptimierer kann keine Einschränkungen für die Basistabelle verwenden, um seinen Ausführungsplan zu vereinfachen und zu verfeinern. Auch der neue Kardinalitätsschätzer in SQL Server 2014 stellt einen echten Rückschritt dar, wenn es um INSTEAD OF Trigger-Pläne geht. Die Wirkung einer Suchoperation zu erraten, die die Engine selbst eingeführt hat, ist ein überraschendes und unerwünschtes Versehen.