Im Kommentarbereich eines unserer Blogs fragte ein Leser nach den Auswirkungen von wsrep_slave_threads auf die E/A-Leistung und Skalierbarkeit von Galera Cluster. Damals konnten wir diese Frage nicht einfach beantworten und mit weiteren Daten untermauern, aber schließlich haben wir es geschafft, die Umgebung einzurichten und einige Tests durchzuführen.
Unser Leser wies auf Benchmarks hin, die zeigten, dass die Erhöhung von wsrep_slave_threads keinen Einfluss auf die Leistung des Galera-Clusters hatte.
Um zu erklären, welche Auswirkungen diese Einstellung hat, haben wir einen kleinen Cluster aus drei Knoten (m5d.xlarge) eingerichtet. Dadurch konnten wir direkt angeschlossene nvme-SSDs für das MySQL-Datenverzeichnis verwenden. Auf diese Weise haben wir die Wahrscheinlichkeit minimiert, dass Speicher zum Engpass in unserem Setup wird.
Wir richten den InnoDB-Pufferpool auf 8 GB und Redo-Protokolle auf zwei Dateien mit jeweils 1 GB ein. Wir haben auch innodb_io_capacity auf 2000 und innodb_io_capacity_max auf 10000 erhöht. Dies sollte auch sicherstellen, dass keine dieser Einstellungen unsere Leistung beeinträchtigt.
Das ganze Problem bei solchen Benchmarks ist, dass es so viele Engpässe gibt, dass man sie einen nach dem anderen beseitigen muss. Erst nachdem einige Konfigurationsabstimmungen vorgenommen und sichergestellt wurden, dass die Hardware kein Problem darstellt, kann man hoffen, dass einige subtilere Grenzen auftauchen.
Wir haben ~90 GB an Daten mit Sysbench generiert:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareDann wurde der Benchmark ausgeführt. Wir haben zwei Einstellungen getestet:wsrep_slave_threads=1 und wsrep_slave_threads=16. Die Hardware war nicht leistungsfähig genug, um von einer weiteren Erhöhung dieser Variable zu profitieren. Bitte beachten Sie auch, dass wir kein detailliertes Benchmarking durchgeführt haben, um festzustellen, ob wsrep_slave_threads für die beste Leistung auf 16, 8 oder vielleicht 4 gesetzt werden sollte. Uns interessierte, ob wir einen Einfluss auf den Cluster zeigen können. Und ja, die Auswirkungen waren deutlich sichtbar. Für den Anfang einige Diagramme zur Flusskontrolle.
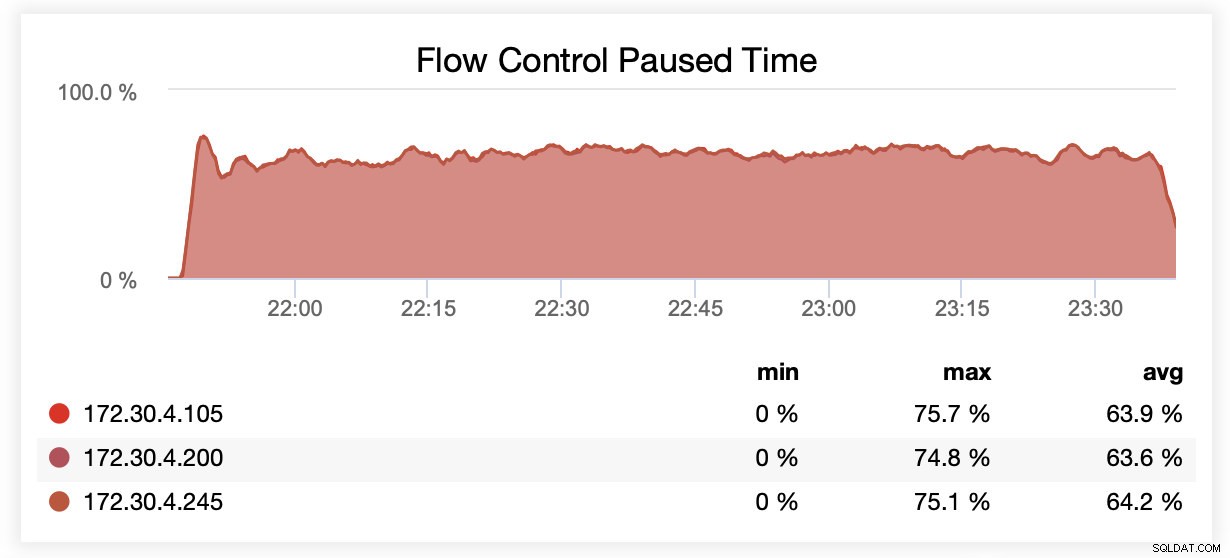
Während der Ausführung mit wsrep_slave_threads=1 wurden Knoten aufgrund von Flusskontrolle im Durchschnitt in etwa 64 % der Fälle angehalten.
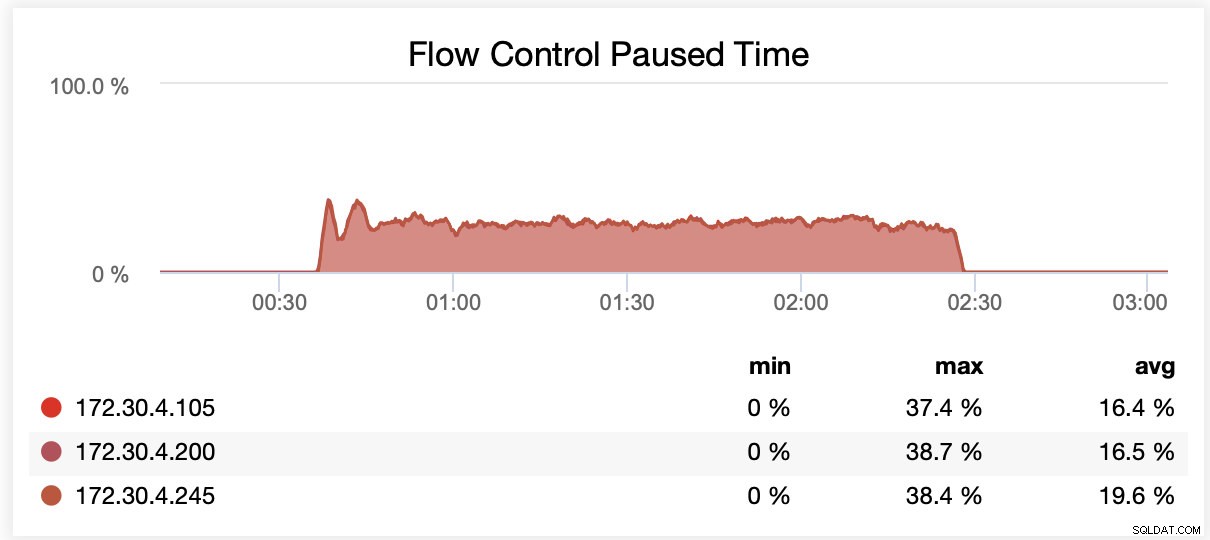
Während der Ausführung mit wsrep_slave_threads=16 wurden Knoten aufgrund von Flusskontrolle im Durchschnitt in etwa 20 % der Fälle angehalten.
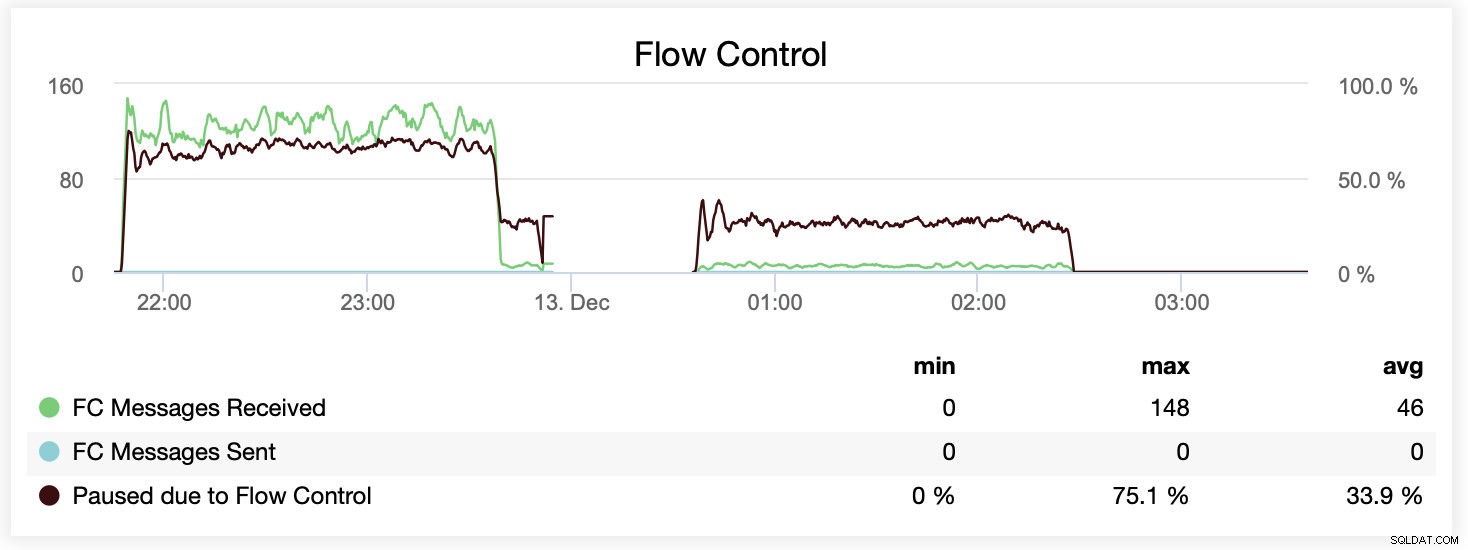
Sie können den Unterschied auch in einem einzelnen Diagramm vergleichen. Der Drop am Ende des ersten Teils ist der erste Versuch, mit wsrep_slave_threads=16 zu laufen. Den Servern ging der Speicherplatz für Binärprotokolle aus und wir mussten diesen Benchmark zu einem späteren Zeitpunkt noch einmal ausführen.
Wie hat sich das in Bezug auf die Leistung niedergeschlagen? Der Unterschied ist sichtbar, wenn auch definitiv nicht so spektakulär.
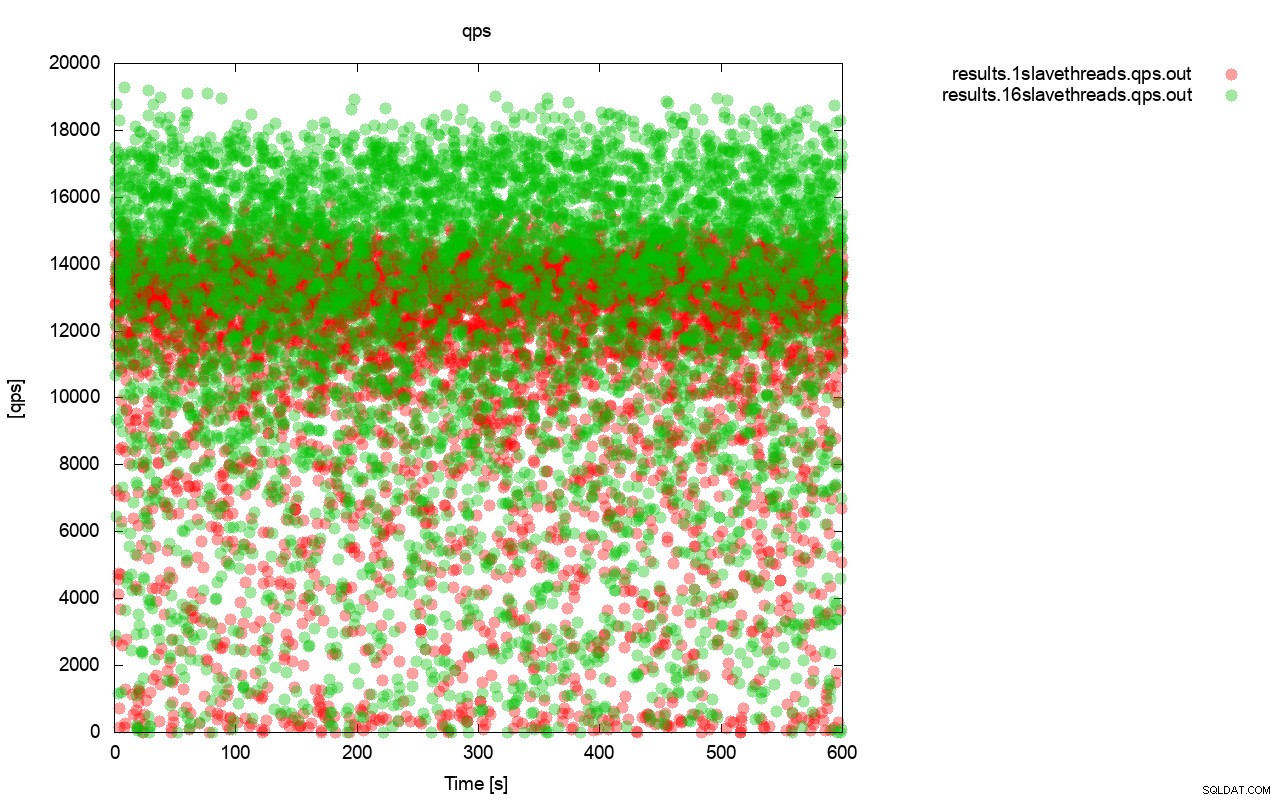
Zuerst das Diagramm der Abfrage pro Sekunde. Zunächst einmal können Sie feststellen, dass in beiden Fällen die Ergebnisse überall liegen. Dies hängt hauptsächlich mit der instabilen Leistung des E/A-Speichers und der zufällig eingreifenden Flusskontrolle zusammen. Sie können immer noch sehen, dass die Leistung des „roten“ Ergebnisses (wsrep_slave_threads=1) deutlich niedriger ist als die des „grünen“ ( wsrep_slave_threads=16).
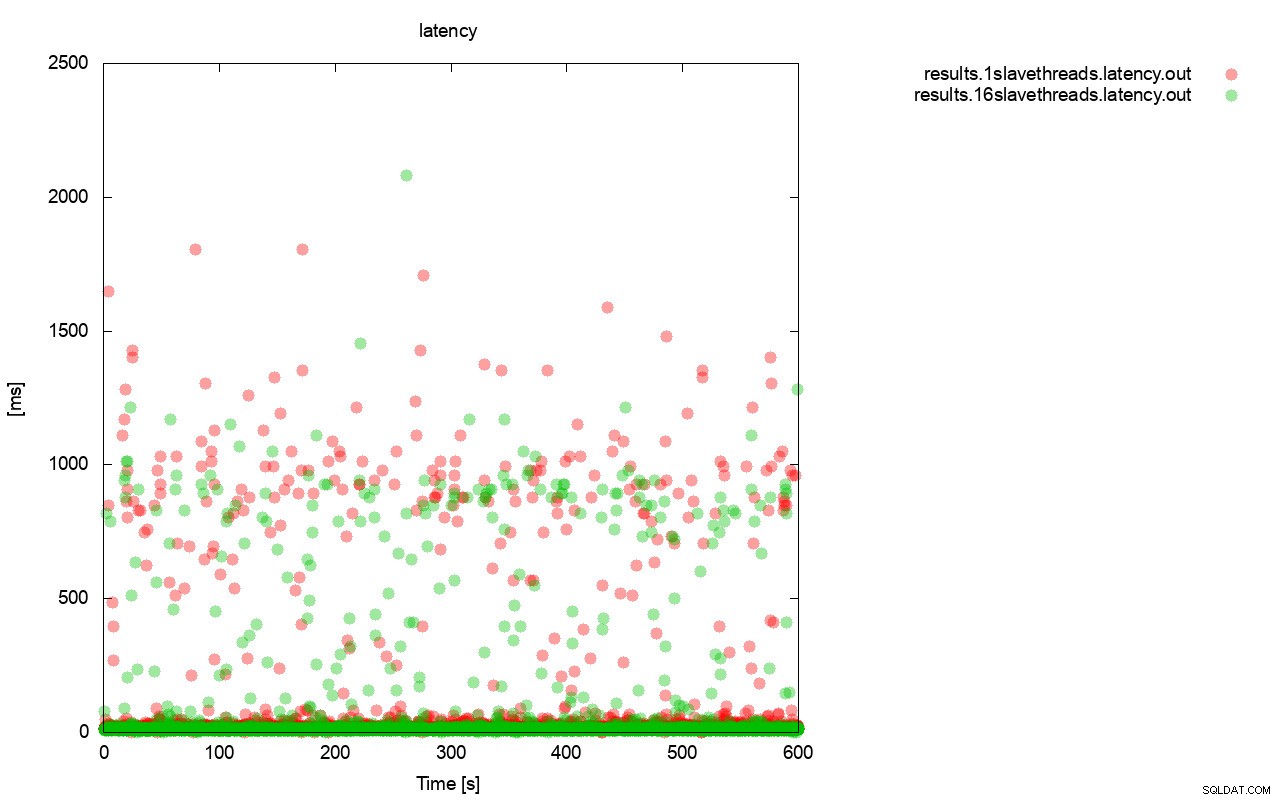
Ein ganz ähnliches Bild ergibt sich, wenn wir uns die Latenz ansehen. Mit wsrep_slave_thread=1 können Sie mehr (und typischerweise tiefere) Stalls für den Lauf sehen.
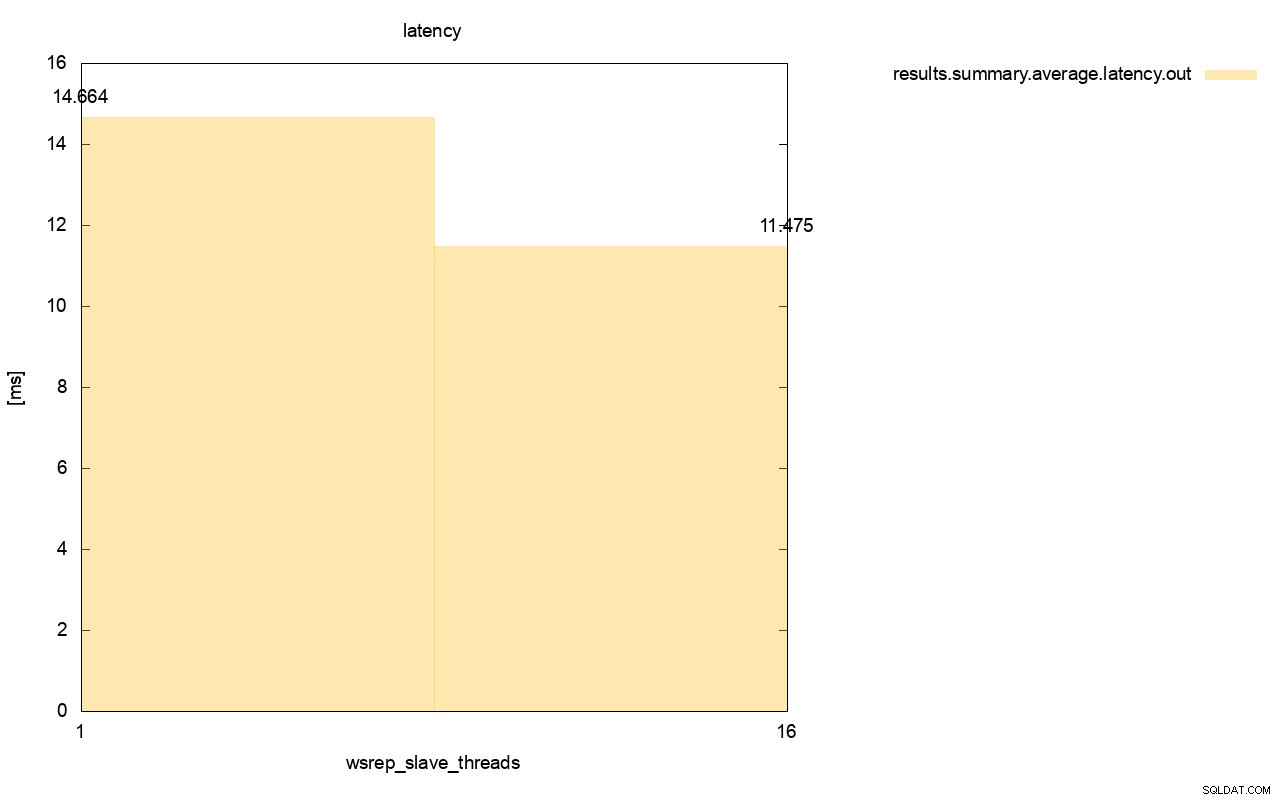
Der Unterschied wird noch deutlicher, wenn wir die durchschnittliche Latenz über alle Läufe hinweg berechnet haben und Sie können sehen, dass die Latenz von wsrep_slave_thread=1 27 % höher ist als die Latenz mit 16 Slave-Threads, was offensichtlich nicht gut ist, da wir eine niedrigere Latenz wünschen , nicht höher.
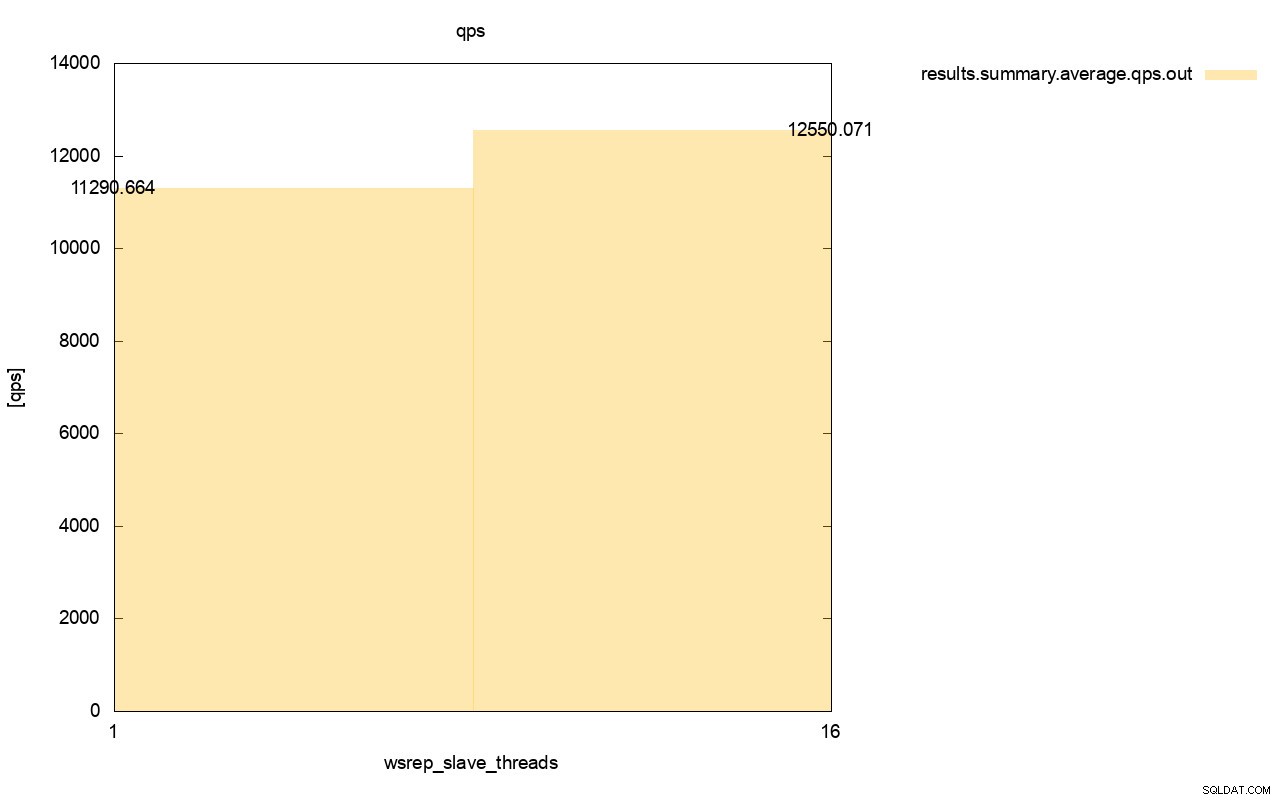
Der Unterschied im Durchsatz ist ebenfalls sichtbar, etwa 11 % der Verbesserung, wenn wir mehr wsrep_slave_threads hinzugefügt haben.
Wie Sie sehen können, ist die Wirkung da. Es ist keineswegs 16x (auch wenn wir dadurch die Anzahl der Slave-Threads in Galera erhöht haben), aber es ist definitiv prominent genug, dass wir es nicht nur als statistische Anomalie klassifizieren können.
Bitte beachten Sie, dass wir in unserem Fall recht kleine Knoten verwendet haben. Der Unterschied sollte sogar noch größer sein, wenn wir über große Instanzen sprechen, die auf EBS-Volumes mit Tausenden von bereitgestellten IOPS ausgeführt werden.
Dann könnten wir Sysbench noch aggressiver ausführen, mit einer höheren Anzahl gleichzeitiger Operationen. Dies sollte die Parallelisierung der Writesets verbessern und den Gewinn aus dem Multithreading noch weiter verbessern. Außerdem bedeutet schnellere Hardware, dass Galera diese 16 Threads effizienter nutzen kann.
Wenn Sie solche Tests durchführen, müssen Sie bedenken, dass Sie Ihr Setup fast an seine Grenzen bringen müssen. Die Singlethread-Replikation kann eine ziemlich große Last bewältigen, und Sie müssen einen hohen Datenverkehr ausführen, damit sie tatsächlich nicht leistungsfähig genug ist, um die Aufgabe zu bewältigen.
Wir hoffen, dass Ihnen dieser Blog-Beitrag mehr Einblick in die Fähigkeiten von Galera Cluster zur parallelen Anwendung von Writesets und die damit verbundenen einschränkenden Faktoren gibt.