Das beste Szenario ist, dass Sie im Falle eines Datenbankausfalls einen guten Notfallwiederherstellungsplan (DRP) und eine hochverfügbare Umgebung mit einem automatischen Failover-Prozess haben, aber ... was passiert, wenn es fehlschlägt? irgendein unerwarteter Grund? Was ist, wenn Sie ein manuelles Failover durchführen müssen? In diesem Blog geben wir einige Empfehlungen weiter, die Sie befolgen sollten, falls Sie ein Failover für Ihre Datenbank durchführen müssen.
Verifizierungsprüfungen
Bevor Sie Änderungen vornehmen, müssen Sie einige grundlegende Dinge überprüfen, um neue Probleme nach dem Failover-Prozess zu vermeiden.
Replikationsstatus
Es könnte möglich sein, dass der Slave-Knoten zum Zeitpunkt des Ausfalls aufgrund eines Netzwerkausfalls, einer hohen Last oder eines anderen Problems nicht auf dem neuesten Stand ist, daher müssen Sie sicherstellen, dass Ihre Sklave hat alle (oder fast alle) Informationen. Wenn Sie mehr als einen Slave-Knoten haben, sollten Sie auch prüfen, welcher der fortschrittlichste Knoten ist, und ihn für das Failover auswählen.
Beispiel:Lassen Sie uns den Replikationsstatus in einem MariaDB-Server überprüfen.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)Bei PostgreSQL ist es etwas anders, da Sie den Status der WALs überprüfen und die angewendeten mit den abgerufenen vergleichen müssen.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Anmeldeinformationen
Bevor Sie das Failover ausführen, müssen Sie überprüfen, ob Ihre Anwendung/Benutzer mit den aktuellen Anmeldeinformationen auf Ihren neuen Master zugreifen können. Wenn Sie Ihre Datenbankbenutzer nicht replizieren, wurden möglicherweise die Anmeldeinformationen geändert, sodass Sie sie in den Slave-Knoten aktualisieren müssen, bevor Sie Änderungen vornehmen.
Beispiel:Sie können die Benutzertabelle in der MySQL-Datenbank abfragen, um die Benutzeranmeldeinformationen in einem MariaDB/MySQL-Server zu überprüfen:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)Im Fall von PostgreSQL können Sie den Befehl „\du“ verwenden, um die Rollen zu kennen, und Sie müssen auch die Konfigurationsdatei pg_hba.conf überprüfen, um den Benutzerzugriff (nicht die Anmeldeinformationen) zu verwalten. Also:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}Und pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustNetzwerk-/Firewallzugriff
Die Anmeldeinformationen sind nicht das einzig mögliche Problem beim Zugriff auf Ihren neuen Master. Wenn sich der Knoten in einem anderen Rechenzentrum befindet oder Sie eine lokale Firewall zum Filtern des Datenverkehrs haben, müssen Sie prüfen, ob Sie darauf zugreifen dürfen oder ob Sie sogar die Netzwerkroute haben, um den neuen Master-Knoten zu erreichen.
zB:iptables. Lassen Sie uns den Datenverkehr aus dem Netzwerk 167.124.57.0/24 zulassen und überprüfen Sie die aktuellen Regeln, nachdem Sie ihn hinzugefügt haben:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationzB:Routen. Angenommen, Ihr neuer Master-Knoten befindet sich im Netzwerk 10.0.0.0/24, Ihr Anwendungsserver befindet sich unter 192.168.100.0/24 und Sie können das Remote-Netzwerk über 192.168.100.100 erreichen. Fügen Sie also in Ihrem Anwendungsserver die entsprechende Route hinzu:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Aktionspunkte
Nachdem Sie alle genannten Punkte überprüft haben, sollten Sie bereit sein, die Aktionen zum Failover Ihrer Datenbank durchzuführen.
Neue IP-Adresse
Wenn Sie einen Slave-Knoten heraufstufen, ändert sich die Master-IP-Adresse, also müssen Sie sie in Ihrer Anwendung oder im Client-Zugriff ändern.
Die Verwendung eines Load Balancers ist eine ausgezeichnete Möglichkeit, dieses Problem/diese Änderung zu vermeiden. Nach dem Failover-Prozess erkennt der Load Balancer den alten Master als offline und sendet (abhängig von der Konfiguration) den Datenverkehr an den neuen, um darauf zu schreiben, sodass Sie nichts an Ihrer Anwendung ändern müssen.
Beispiel:Sehen wir uns ein Beispiel für eine HAProxy-Konfiguration an:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkWenn in diesem Fall ein Knoten ausgefallen ist, sendet HAProxy keinen Datenverkehr dorthin und sendet den Datenverkehr nur an den verfügbaren Knoten.
Rekonfiguriere die Slave-Knoten
Wenn Sie mehr als einen Slave-Knoten haben, müssen Sie nach dem Hochstufen eines von ihnen die restlichen Slaves neu konfigurieren, um sich mit dem neuen Master zu verbinden. Dies kann je nach Anzahl der Knoten eine zeitaufwändige Aufgabe sein.
Sicherungen überprüfen und konfigurieren
Nachdem Sie alles eingerichtet haben (neuer Master hochgestuft, Slaves neu konfiguriert, Anwendung im neuen Master schreiben), ist es wichtig, die notwendigen Maßnahmen zu ergreifen, um ein neues Problem zu verhindern, daher sind Backups ein Muss dieser Schritt. Höchstwahrscheinlich hatten Sie vor dem Vorfall eine Backup-Richtlinie ausgeführt (wenn nicht, müssen Sie sie auf jeden Fall haben), also müssen Sie überprüfen, ob die Backups noch ausgeführt werden oder in der neuen Topologie ausreichen. Es ist möglich, dass Sie die Backups auf dem alten Master ausgeführt haben oder den Slave-Knoten verwenden, der jetzt Master ist, also müssen Sie ihn überprüfen, um sicherzustellen, dass Ihre Backup-Richtlinie nach den Änderungen noch funktioniert.
Datenbanküberwachung
Wenn Sie einen Failover-Prozess durchführen, ist die Überwachung vor, während und nach dem Prozess ein Muss. Auf diese Weise können Sie ein Problem verhindern, bevor es sich verschlimmert, ein unerwartetes Problem während des Failovers erkennen oder sogar wissen, ob danach etwas schief geht. Beispielsweise müssen Sie überwachen, ob Ihre Anwendung auf Ihren neuen Master zugreifen kann, indem Sie die Anzahl der aktiven Verbindungen überprüfen.
Zu überwachende Schlüsselmetriken
Sehen wir uns einige der wichtigsten Metriken an, die es zu berücksichtigen gilt:
- Replikationsverzögerung
- Replikationsstatus
- Anzahl der Verbindungen
- Netzwerknutzung/Fehler
- Serverlast (CPU, Arbeitsspeicher, Festplatte)
- Datenbank- und Systemprotokolle
Zurücksetzen
Wenn etwas schief gelaufen ist, müssen Sie natürlich ein Rollback durchführen können. Datenverkehr zum alten Knoten zu blockieren und so isoliert wie möglich zu halten, könnte dafür eine gute Strategie sein, sodass Sie für den Fall, dass Sie ein Rollback durchführen müssen, den alten Knoten zur Verfügung haben. Wenn das Rollback nach einigen Minuten erfolgt, müssen Sie je nach Datenverkehr wahrscheinlich die Daten dieser Minuten in den alten Master einfügen. Stellen Sie also sicher, dass Sie auch Ihren temporären Master-Knoten verfügbar und isoliert haben, um diese Informationen zu übernehmen und wieder anzuwenden .
Failover-Prozess mit ClusterControl automatisieren
Wenn Sie all diese notwendigen Aufgaben sehen, um ein Failover durchzuführen, möchten Sie es höchstwahrscheinlich automatisieren und all diese manuelle Arbeit vermeiden. Dafür können Sie einige der Funktionen nutzen, die ClusterControl Ihnen für verschiedene Datenbanktechnologien anbieten kann, wie automatische Wiederherstellung, Backups, Benutzerverwaltung, Überwachung und andere Funktionen, alles vom selben System aus.
Mit ClusterControl können Sie den Replikationsstatus und seine Verzögerung überprüfen, Anmeldeinformationen erstellen oder ändern, den Netzwerk- und Hoststatus kennen und noch mehr Überprüfungen durchführen.
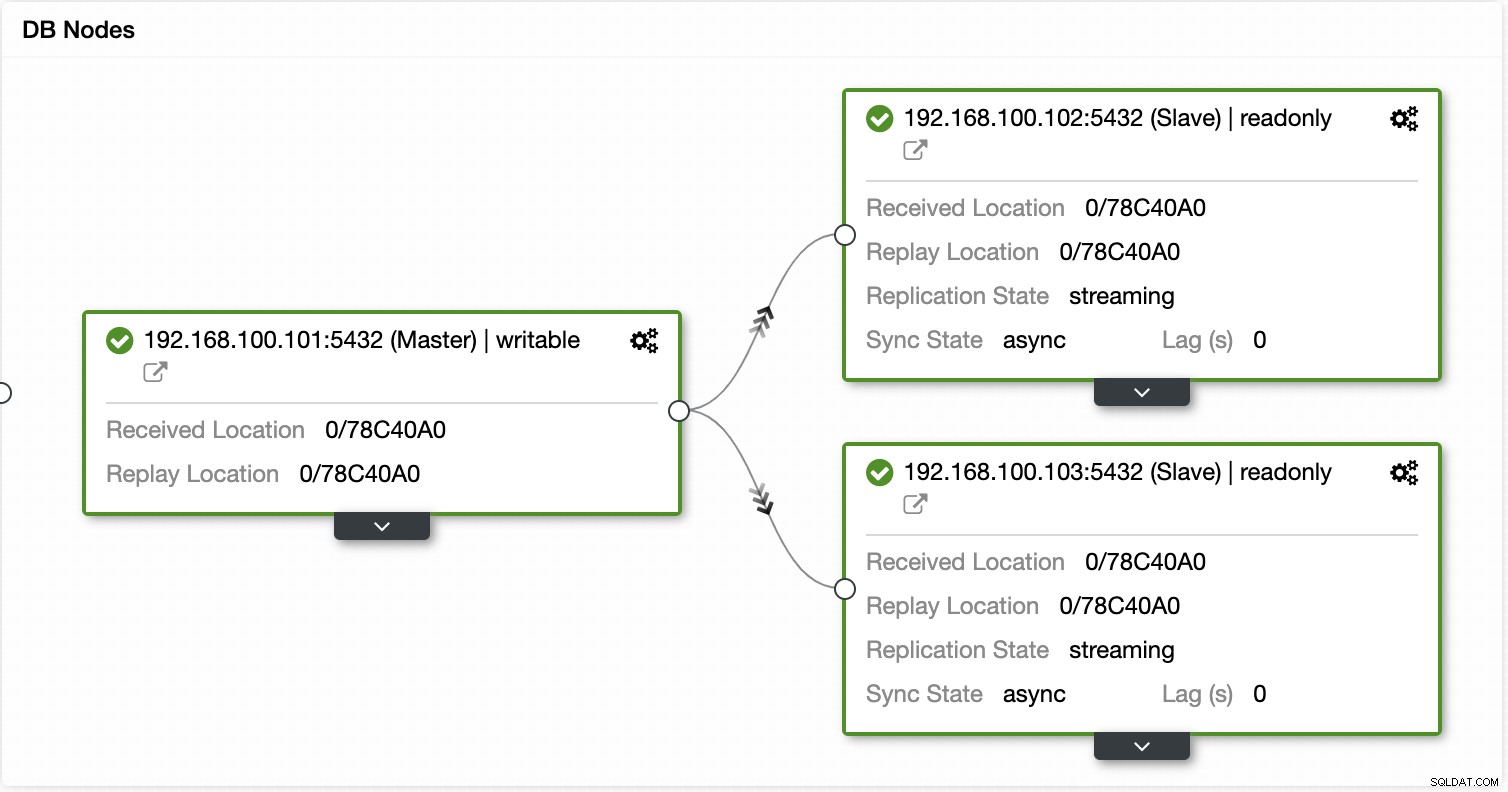
Mit ClusterControl können Sie auch verschiedene Cluster- und Knotenaktionen durchführen, wie z , Datenbank und Server neu starten, Datenbankknoten hinzufügen oder entfernen, Load-Balancer-Knoten hinzufügen oder entfernen, einen Replikations-Slave neu aufbauen und mehr.
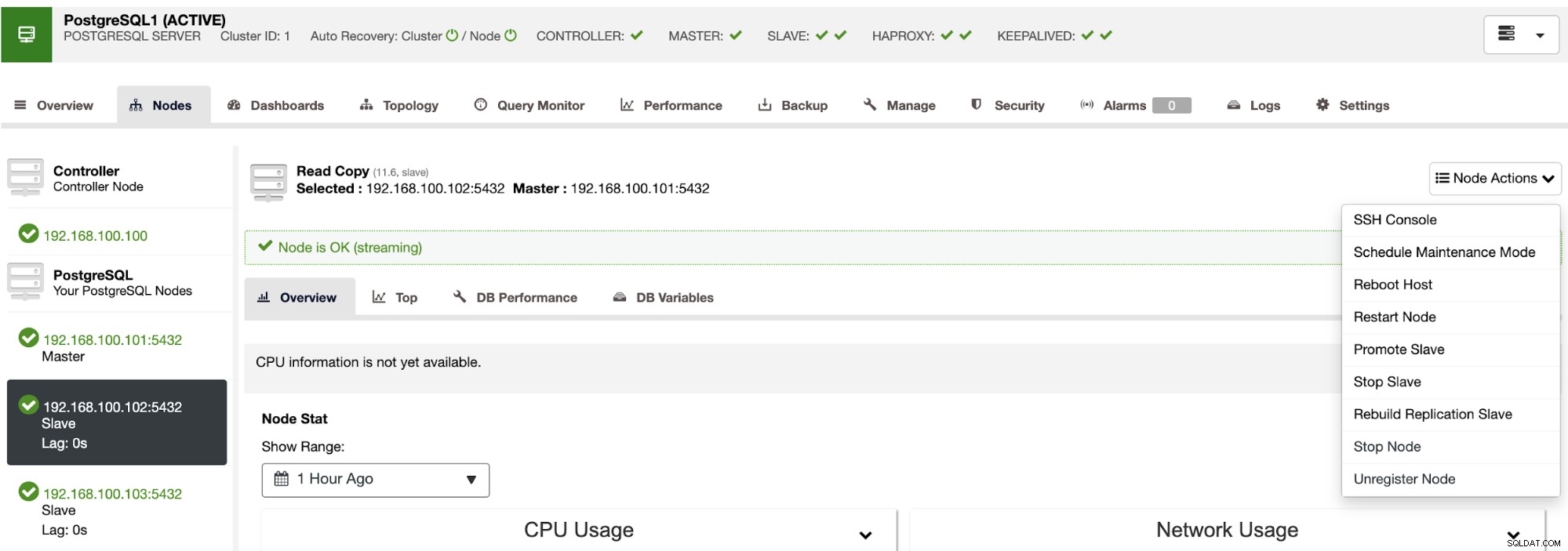
Mit diesen Aktionen können Sie bei Bedarf auch Ihr Failover zurücksetzen, indem Sie es neu erstellen und heraufstufen der vorherige Meister.
ClusterControl verfügt über Überwachungs- und Warndienste, die Ihnen dabei helfen, zu wissen, was passiert oder ob etwas zuvor passiert ist.
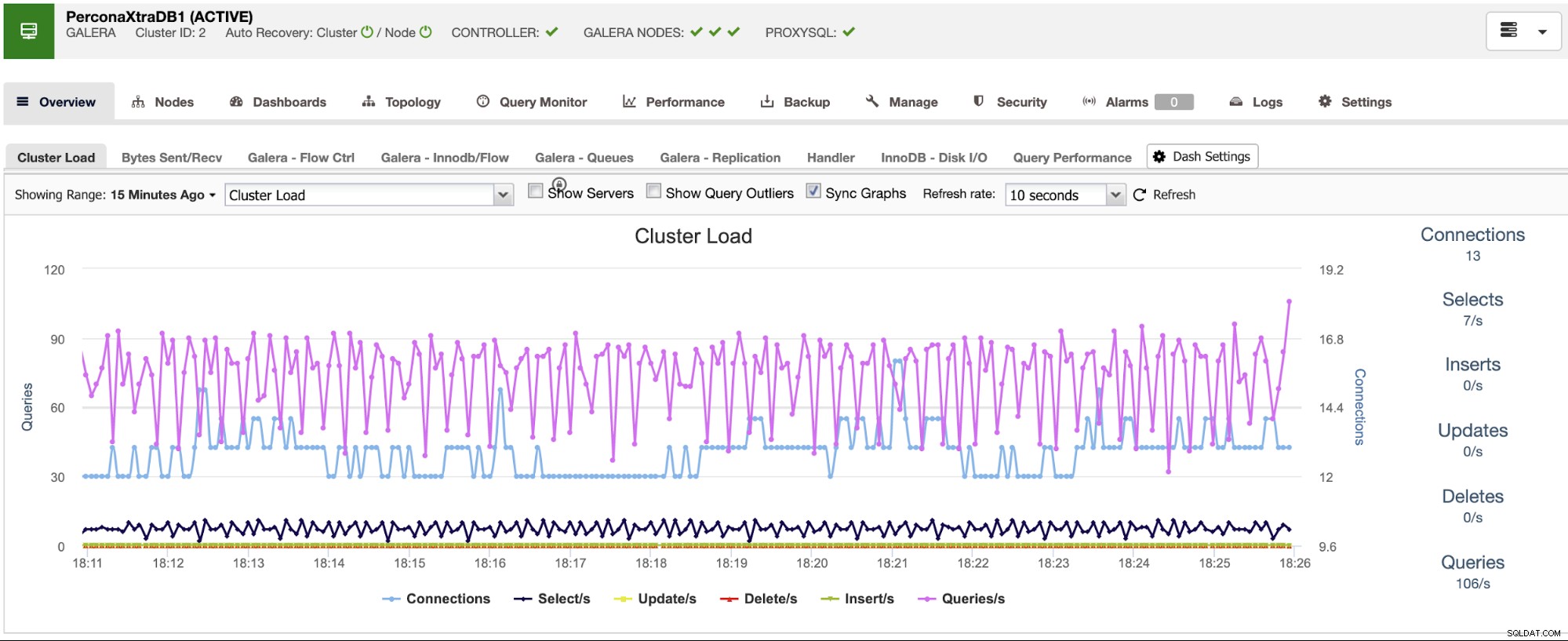
Sie können auch den Dashboard-Bereich verwenden, um eine benutzerfreundlichere Ansicht zu erhalten über den Status Ihrer Systeme.
Fazit
Im Falle eines Ausfalls der Master-Datenbank sollten Sie alle Informationen zur Hand haben, um so schnell wie möglich die erforderlichen Maßnahmen ergreifen zu können. Ein guter DRP ist der Schlüssel, um Ihr System die ganze Zeit (oder fast die ganze Zeit) am Laufen zu halten. Dieses DRP sollte einen gut dokumentierten Failover-Prozess beinhalten, um ein akzeptables RTO (Recovery Time Objective) für das Unternehmen zu haben.