Das Überwachen Ihrer Datenbankschemaänderungen in MySQL/MariaDB ist eine große Hilfe, da es Zeit spart, Ihr Datenbankwachstum, Tabellendefinitionsänderungen, Datengröße, Indexgröße oder Zeilengröße zu analysieren. Wenn Sie für MySQL/MariaDB eine Abfrage ausführen, die information_schema zusammen mit performance_schema referenziert, erhalten Sie kollektive Ergebnisse für die weitere Analyse. Das sys-Schema bietet Ihnen Ansichten, die als kollektive Metriken dienen, die sehr nützlich sind, um Datenbankänderungen oder -aktivitäten zu verfolgen.
Wenn Sie viele Datenbankserver haben, wäre es mühsam, ständig eine Abfrage auszuführen. Sie müssen dieses Ergebnis auch besser lesbar und verständlicher machen.
In diesem Blog erstellen wir eine Automatisierung, die als nützliches Hilfsmittel für Ihre vorhandene Datenbank zur Überwachung und zum Sammeln von Metriken zu Datenbankänderungen oder Schemaänderungsvorgängen hilfreich wäre.
Automatisierung für Datenbankschema-Objektprüfung erstellen
In dieser Übung überwachen wir die folgenden Metriken:
-
Keine Primärschlüsseltabellen
-
Doppelte Indizes
-
Generieren Sie ein Diagramm für die Gesamtzahl der Zeilen in unseren Datenbankschemata
-
Generiere ein Diagramm für die Gesamtgröße unserer Datenbankschemata
Diese Übung gibt Ihnen einen Überblick und kann modifiziert werden, um fortgeschrittenere Metriken aus Ihrer MySQL/MariaDB-Datenbank zu sammeln.
Puppet für unsere IaC und Automatisierung verwenden
Diese Übung soll Puppet verwenden, um eine Automatisierung bereitzustellen und die erwarteten Ergebnisse basierend auf den Metriken zu generieren, die wir überwachen möchten. Wir werden die Installation und Einrichtung von Puppet, einschließlich Server und Client, nicht behandeln, daher erwarte ich, dass Sie wissen, wie man Puppet verwendet. Vielleicht möchten Sie unseren alten Blog Automated Deployment of MySQL Galera Cluster to Amazon AWS with Puppet besuchen, der die Einrichtung und Installation von Puppet behandelt.
Wir werden in dieser Übung die neueste Version von Puppet verwenden, aber da unser Code aus grundlegender Syntax besteht, würde er für ältere Versionen von Puppet laufen.
Bevorzugter MySQL-Datenbankserver
In dieser Übung verwenden wir Percona Server 8.0.22-13, da ich Percona Server hauptsächlich zum Testen und für einige kleinere Bereitstellungen für geschäftliche oder private Zwecke bevorzuge.
Grafiktool
Es gibt Unmengen von Optionen, die Sie verwenden können, insbesondere in der Linux-Umgebung. In diesem Blog verwende ich das einfachste, das ich gefunden habe, und ein Open-Source-Tool https://quickchart.io/.
Lass uns mit der Puppe spielen
Die Annahme, die ich hier gemacht habe, ist, dass Sie einen Master-Server mit einem registrierten Client eingerichtet haben, der bereit ist, mit dem Master-Server zu kommunizieren, um automatische Bereitstellungen zu erhalten.
Bevor wir fortfahren, hier die Informationen zu meinem Server:
Masterserver:192.168.40.200
Client/Agent-Server:192.168.40.160
In diesem Blog ist unser Client/Agent-Server der Ort, an dem unser Datenbankserver läuft. In einem realen Szenario muss er nicht speziell für die Überwachung sein. Solange es in der Lage ist, sicher mit dem Zielknoten zu kommunizieren, ist dies auch ein perfektes Setup.
Modul und Code einrichten
-
Gehen Sie zum Masterserver und in den Pfad /etc/puppetlabs/code/environments/production/module, Lassen Sie uns die erforderlichen Verzeichnisse für diese Übung erstellen:
mkdir schema_change_mon/{files,manifests}
-
Erstellen Sie die Dateien, die wir brauchen
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Füllen Sie das init.pp-Skript mit folgendem Inhalt aus:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Füllen Sie die Datei graphing_gen.sh aus. Dieses Skript wird auf dem Zielknoten ausgeführt und generiert Diagramme für die Gesamtzahl der Zeilen in unserer Datenbank und auch für die Gesamtgröße unserer Datenbank. Machen wir es für dieses Skript einfacher und lassen nur Datenbanken vom Typ MyISAM oder InnoDB zu.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Schließlich gehen Sie zum Modulpfadverzeichnis oder /etc/puppetlabs/code/environments /production in meinem Setup. Lassen Sie uns die Datei manifests/schema_change_mon.pp erstellen.
touch manifests/schema_change_mon.pp-
Füllen Sie dann die Datei manifests/schema_change_mon.pp mit folgendem Inhalt,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Wenn Sie fertig sind, sollten Sie die folgende Baumstruktur haben, genau wie meine,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppWas macht unser Modul?
Unser Modul namens schema_change_mon sammelt Folgendes,
exec { "mysql-without-primary-key" :...
Das einen mysql-Befehl ausführt und eine Abfrage zum Abrufen von Tabellen ohne Primärschlüssel ausführt. Dann
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :das doppelte Indizes sammelt, die in den Datenbanktabellen vorhanden sind.
Als Nächstes generieren die Linien Diagramme basierend auf den gesammelten Metriken. Dies sind die folgenden Zeilen,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Sobald die Abfrage erfolgreich ausgeführt wird, generiert sie das Diagramm, das von der von https://quickchart.io/ bereitgestellten API abhängt.
Hier sind die folgenden Ergebnisse der Grafik:
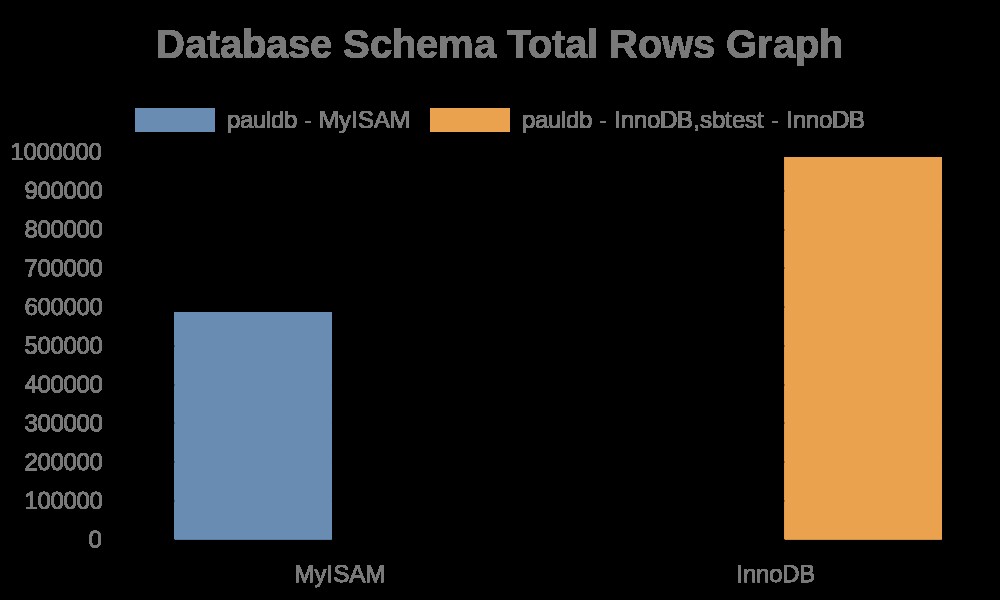
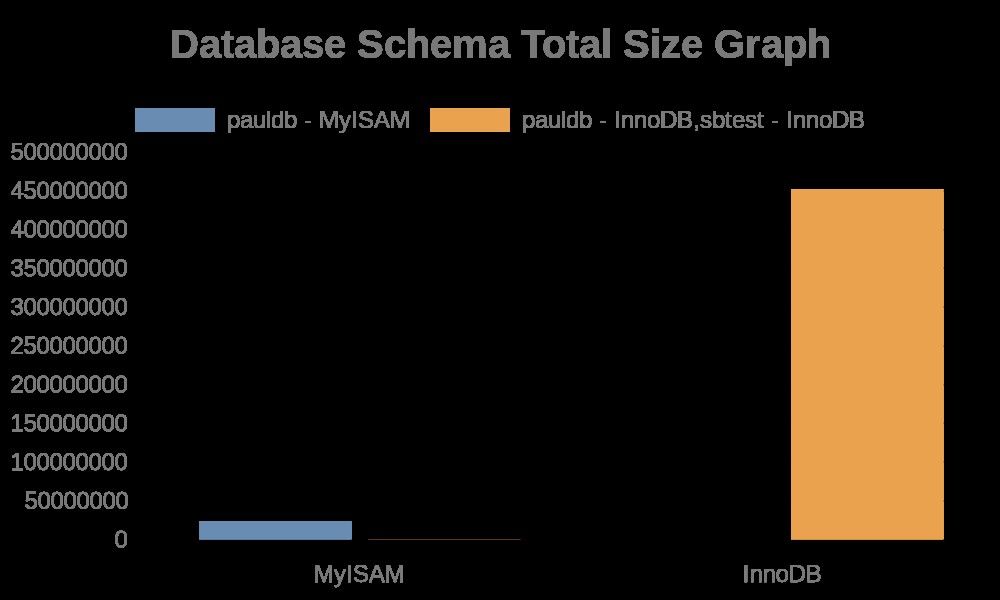
Dagegen enthalten die Dateiprotokolle einfach Zeichenfolgen mit ihren Tabellennamen, Indexnamen. Sehen Sie sich das Ergebnis unten an,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBWarum nicht ClusterControl verwenden?
Da unsere Übung die Automatisierung und das Abrufen der Datenbankschemastatistiken wie Änderungen oder Operationen demonstriert, bietet ClusterControl dies ebenfalls. Abgesehen davon gibt es noch andere Funktionen, und Sie müssen das Rad nicht neu erfinden. ClusterControl kann Transaktionsprotokolle bereitstellen, wie z. B. Deadlocks, wie oben gezeigt, oder lange laufende Abfragen, wie unten gezeigt:
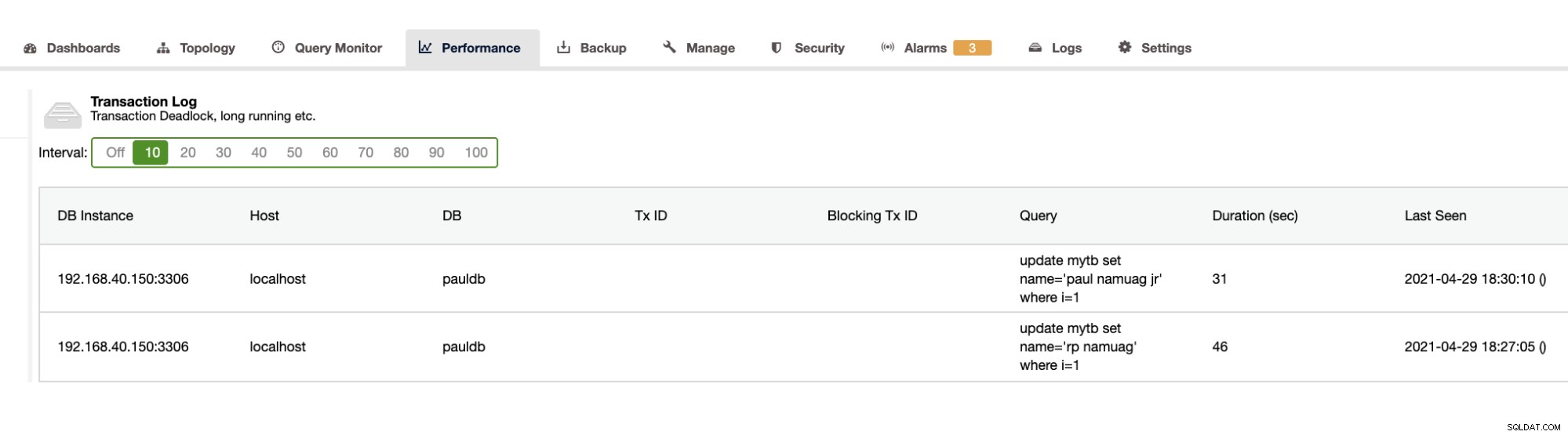
ClusterControl zeigt auch das DB-Wachstum wie unten gezeigt,
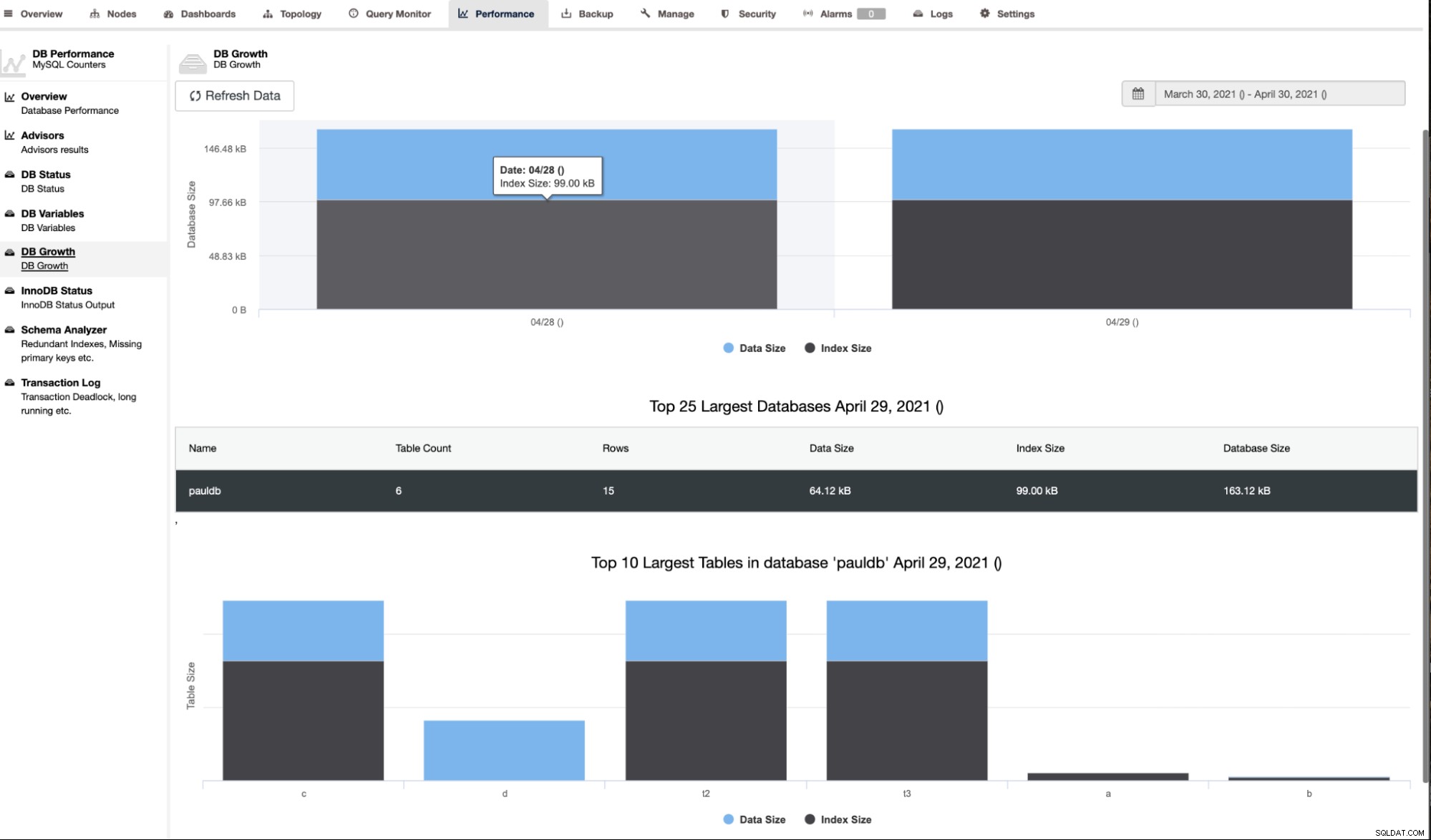
ClusterControl liefert auch zusätzliche Informationen wie Zeilenanzahl, Festplattengröße, Indexgröße und Gesamtgröße.
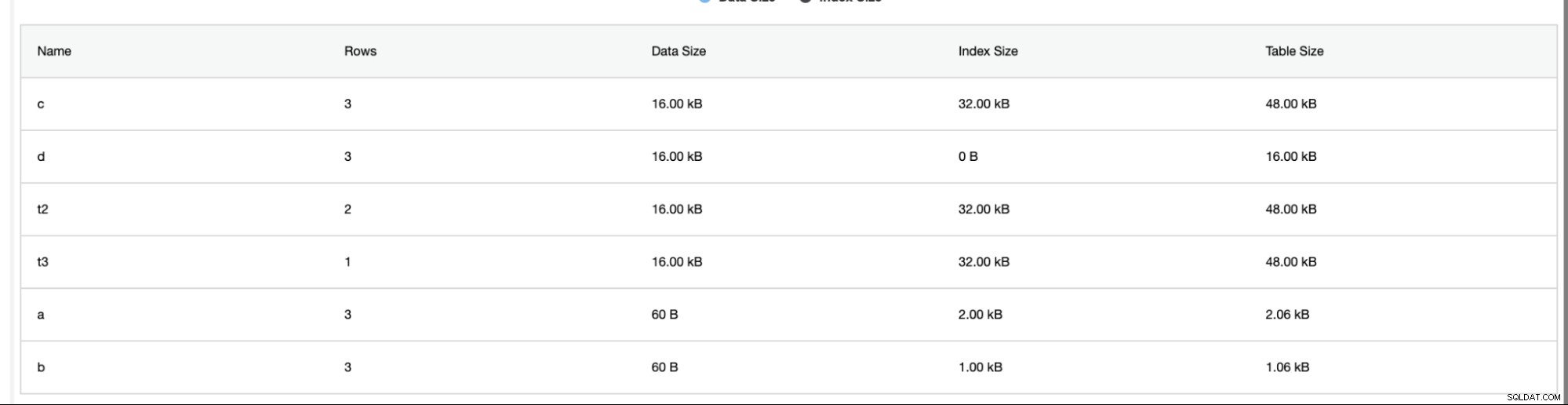
Der Schemaanalysator unter dem Reiter Leistung -> Schemaanalysator ist sehr hilfreich. Es bietet Tabellen ohne Primärschlüssel, MyISAM-Tabellen und doppelte Indizes,

Es bietet auch Alarme, falls doppelte Indizes oder Tabellen ohne primäre gefunden werden Tasten wie unten,

Weitere Informationen zu ClusterControl und seinen anderen Funktionen finden Sie auf unserer Produktseite.
Fazit
Das Bereitstellen einer Automatisierung zum Überwachen Ihrer Datenbankänderungen oder beliebiger Schemastatistiken wie Schreibvorgänge, doppelte Indizes, Vorgangsaktualisierungen wie DDL-Änderungen und viele Datenbankaktivitäten ist für DBAs sehr vorteilhaft. Es hilft, die schwachen Links und problematischen Abfragen schnell zu identifizieren, was Ihnen einen Überblick über eine mögliche Ursache für fehlerhafte Abfragen geben würde, die Ihre Datenbank sperren oder Ihre Datenbank veralten lassen würden.