Der Betrieb eines Galera-Clusters in einer Hybrid-Cloud sollte aus mindestens zwei verschiedenen geografischen Standorten bestehen, die Hosts in der lokalen oder privaten Cloud mit denen in der öffentlichen Cloud verbinden. Unabhängig davon, ob Sie unbreakable Private Cloud- oder Public Cloud-Plattformen verwenden, Disaster Recovery (DR) ist in der Tat ein Schlüsselthema. Es geht nicht darum, Ihre Daten auf einen Backup-Standort zu kopieren und sie wiederherstellen zu können, sondern um die Geschäftskontinuität und darum, wie schnell Sie Dienste im Katastrophenfall wiederherstellen können.
In diesem Blog-Beitrag werden wir verschiedene Möglichkeiten untersuchen, wie Sie Ihre Galera-Cluster für Fehlertoleranz in einer Hybrid-Cloud-Umgebung entwerfen können.
Aktiv-Aktiv-Setup
Galera-Cluster sollte mit einer ungeraden Anzahl von Knoten in einem Cluster ausgeführt werden und beginnt üblicherweise mit 3 Knoten. Dies liegt daran, dass Galera Cluster das Quorum verwendet, um automatisch die primäre Komponente zu bestimmen, bei der eine Mehrheit der verbundenen Knoten in der Lage sein sollte, den Cluster gleichzeitig zu bedienen, falls eine Cluster-Partitionierung stattgefunden hat.
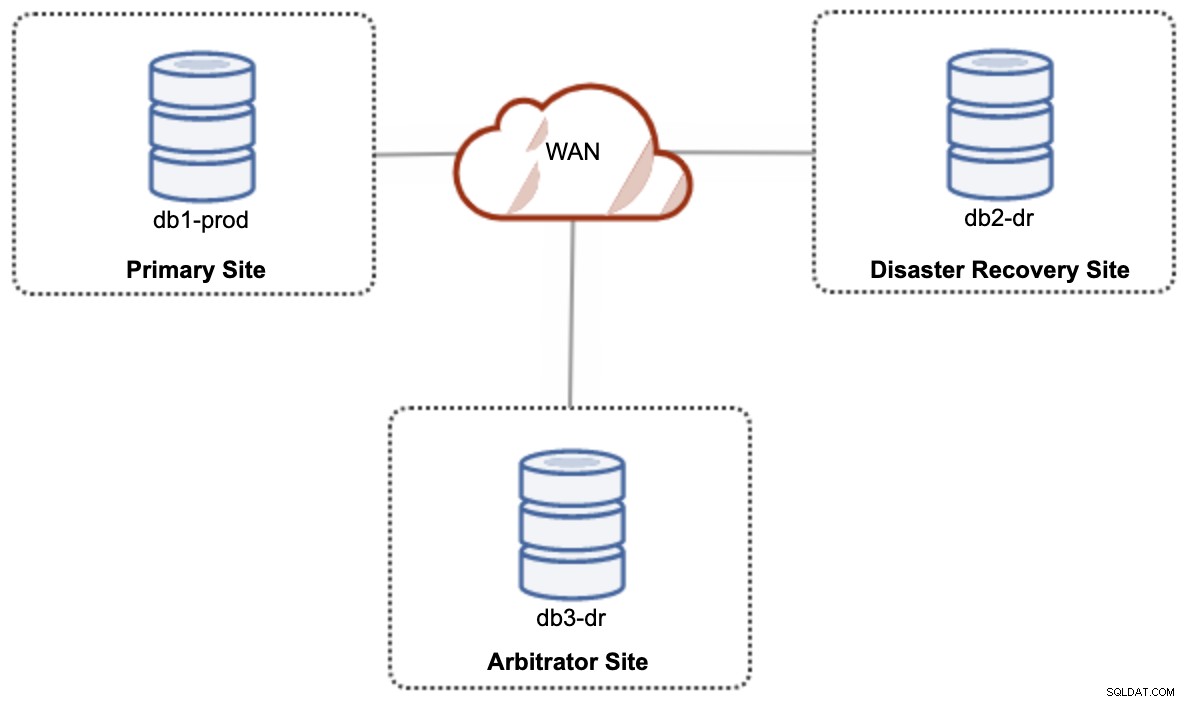
Für ein Aktiv-Aktiv-Hybrid-Cloud-Setup benötigt Galera mindestens 3 verschiedene Standorte, die über das WAN einen Galera-Cluster bilden. Im Allgemeinen benötigen Sie einen dritten Standort, der als Schiedsrichter fungiert, für das Quorum stimmt und die „primäre Komponente“ erhält, wenn einer der Standorte nicht erreichbar ist. Dies kann als mindestens 3-Knoten-Cluster an 3 verschiedenen Standorten (1 Knoten pro Standort) eingerichtet werden, ähnlich wie im folgenden Diagramm:
Aus Leistungs- und Zuverlässigkeitsgründen wird jedoch eine 7 empfohlen -node-Cluster, wie im folgenden Diagramm gezeigt:
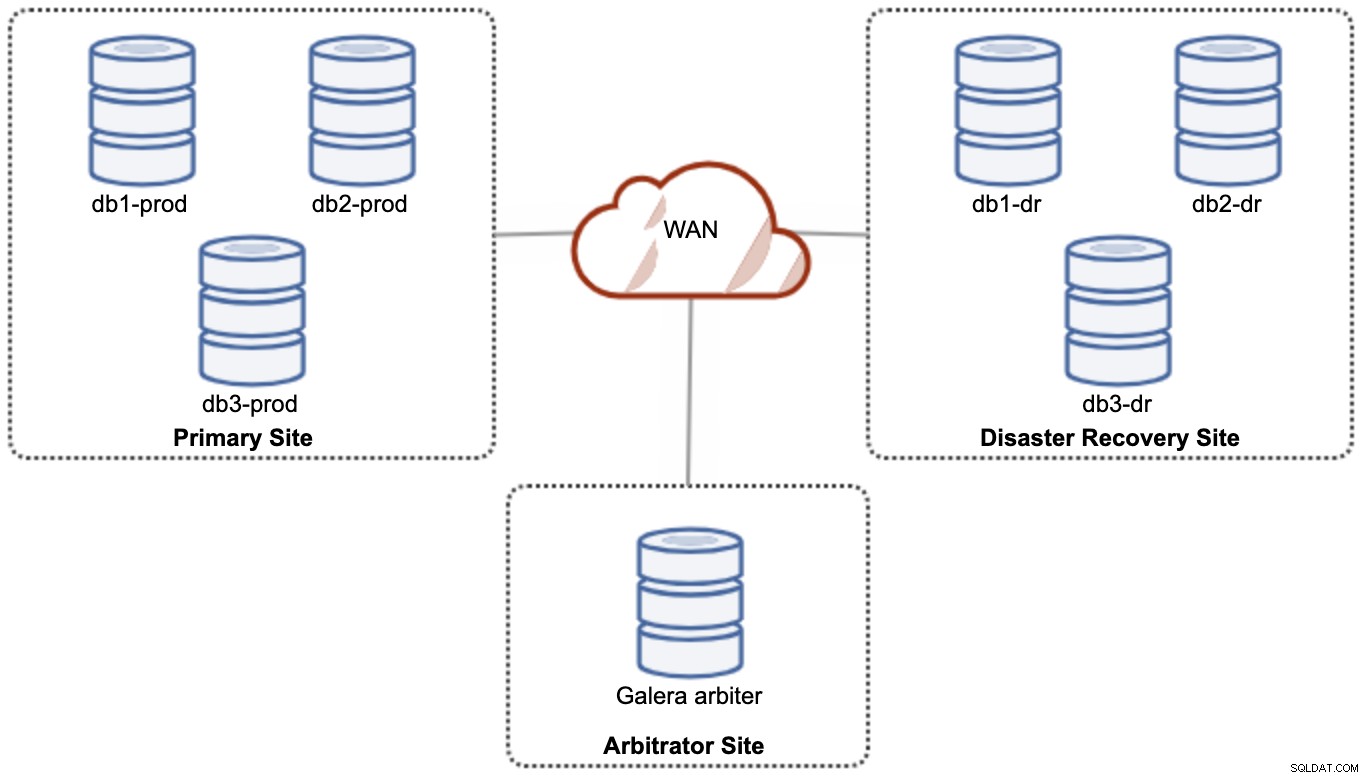
Dies gilt als die beste Topologie zur Unterstützung eines Aktiv-Aktiv-Setups, bei dem die DR-Site fast sofort und ohne Eingriff verfügbar sein sollte. Beide Sites können jederzeit Lese-/Schreibvorgänge empfangen, vorausgesetzt, der Cluster befindet sich im Quorum.
Es ist jedoch sehr kostspielig, 3 Sites und 7 Datenbankknoten zu haben (der 7. Knoten kann durch einen Garbd ersetzt werden, da es sehr unwahrscheinlich ist, dass er verwendet wird, um Daten an die Clients/Anwendungen zu liefern). Dies ist zu Beginn des Projekts aufgrund der enormen Vorabkosten und der Empfindlichkeit der Kommunikation und Replikation der Galera-Gruppe gegenüber Netzwerklatenz häufig keine beliebte Bereitstellung.
Aktiv-Passiv-Setup
In einer Aktiv-Passiv-Konfiguration sind mindestens 2 Sites erforderlich und es ist immer nur eine Site aktiv, die als primäre Site bekannt ist, und die Knoten auf der sekundären Site replizieren nur Daten, die von der primären Site kommen Server/Cluster. Für Galera Cluster können wir entweder die asynchrone MySQL-Replikation (Master-Slave-Replikation) oder auch die virtuell-synchrone Replikation von Galera mit etwas Feinabstimmung verwenden, um die Writeset-Replikation so abzuschwächen, dass sie als asynchrone Replikation fungiert.
Der sekundäre Standort muss vor versehentlichem Schreiben geschützt werden, indem das Nur-Lese-Flag, die Anwendungs-Firewall, der Reverse-Proxy oder andere Mittel verwendet werden, da der Datenfluss immer vom primären zum sekundären Standort erfolgt, sofern dies nicht der Fall ist ein Failover hat den sekundären Standort initiiert und zum primären hochgestuft.
Asynchrone Replikation verwenden
Eine gute Sache bei der asynchronen Replikation ist, dass die Replikation den Quellserver/Cluster nicht beeinträchtigt, aber hinter dem Master zurückbleiben darf. Diese Einrichtung macht den primären Standort und den DR-Standort unabhängig voneinander, lose verbunden mit asynchroner Replikation. Dies kann als mindestens 4-Knoten-Cluster an 2 verschiedenen Standorten eingerichtet werden, ähnlich wie im folgenden Diagramm:
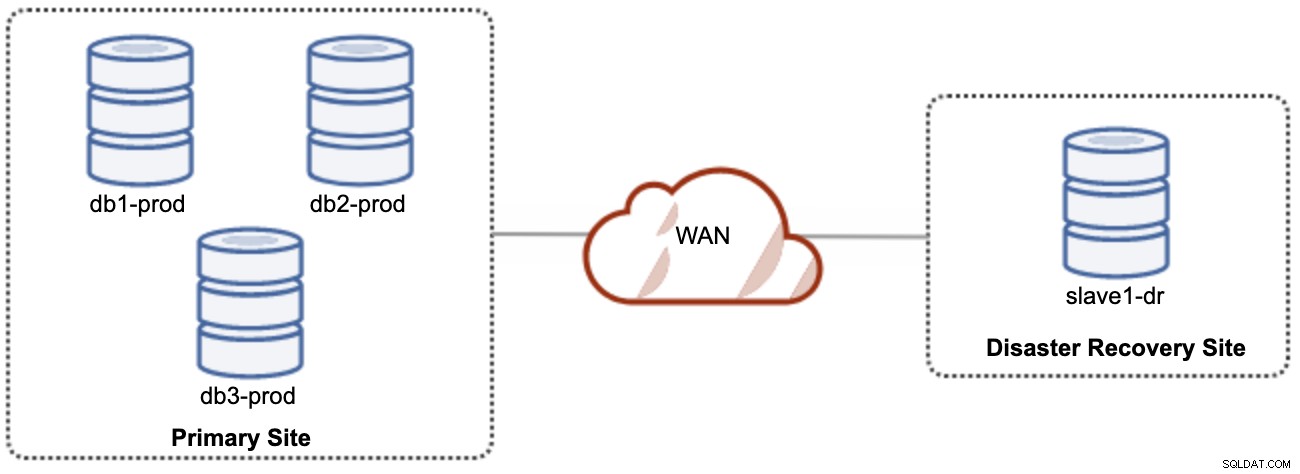
Einer der Galera-Knoten am DR-Standort wird ein Slave sein, der von einem der Galera-Knoten (Master) am primären Standort repliziert. Beide Sites müssen Binärprotokolle mit GTID erstellen und log_slave_updates sind aktiviert – die Updates, die aus dem asynchronen Replikationsstrom stammen, werden auf die anderen Knoten im Cluster angewendet. Für die Produktionsnutzung empfehlen wir jedoch, zwei Gruppen von Clustern auf beiden Sites zu haben, wie im folgenden Diagramm dargestellt:
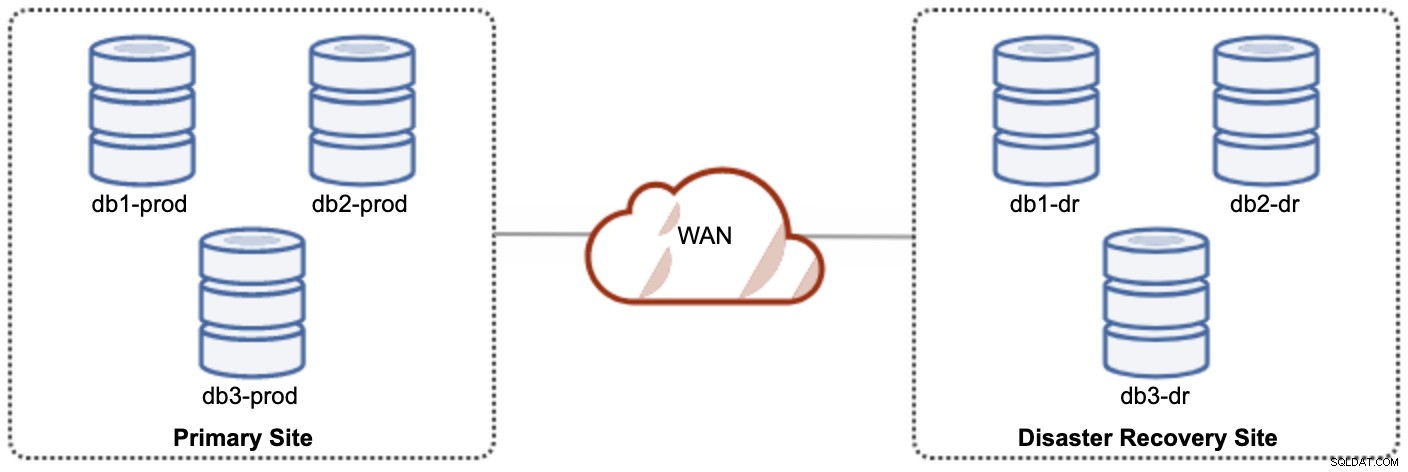
Dadurch, dass zwei getrennte Cluster vorhanden sind, werden sie lose gekoppelt und beeinflussen sich nicht gegenseitig, z. Ein Cluster-Ausfall am primären Standort wirkt sich nicht auf den DR-Standort aus. In Bezug auf die Leistung wirkt sich die WAN-Latenz nicht auf Aktualisierungen im aktiven Cluster aus. Diese werden asynchron an die Backup-Site gesendet. Der DR-Cluster könnte möglicherweise auf kleineren Instanzen in einer öffentlichen Cloud-Umgebung ausgeführt werden, solange sie mit dem primären Cluster mithalten können. Die Instanzen können bei Bedarf aktualisiert werden. Anwendungen sollten Schreibvorgänge an den primären Standort senden, und der sekundäre Standort muss so eingestellt sein, dass er im schreibgeschützten Modus ausgeführt wird. Die Disaster-Recovery-Site kann für andere Zwecke wie Datenbanksicherung, Sicherung von Binärprotokollen und Berichterstellung oder Verarbeitung analytischer Abfragen (OLAP) verwendet werden.
Auf der anderen Seite besteht die Möglichkeit eines Datenverlusts während eines Failovers/Fallbacks, wenn der Slave verzögert war. Daher wird empfohlen, die halbsynchrone Replikation zu aktivieren, um das Risiko von Datenverlusten zu verringern. Beachten Sie, dass die Verwendung der halbsynchronen Replikation im Vergleich zur praktisch synchronen Replikation von Galera immer noch keine starken Garantien gegen Datenverlust bietet. Lesen Sie dieses MySQL-Handbuch sorgfältig durch, zum Beispiel diese Sätze:
"Wenn bei halbsynchroner Replikation die Quelle abstürzt und ein Failover auf ein Replikat durchgeführt wird, sollte die ausgefallene Quelle nicht als Replikationsquelle wiederverwendet und verworfen werden. Sie könnte Transaktionen enthalten, die abgestürzt sind von keinem Replikat bestätigt, die daher vor dem Failover nicht festgeschrieben wurden."
Der Failover-Prozess ist ziemlich einfach. Um die Disaster-Recovery-Site hochzustufen, deaktivieren Sie einfach das Nur-Lesen-Flag und leiten Sie die Anwendung an die Datenbankknoten in der DR-Site weiter. Die Fallback-Strategie ist jedoch etwas knifflig und erfordert einige Erfahrung beim Staging der Daten auf beiden Sites, beim Wechseln der Master-/Slave-Rolle eines Clusters und beim Umleiten des Slave-Replikationsflusses in die entgegengesetzte Richtung.
Galera-Replikation verwenden
Für eine Aktiv-Passiv-Einrichtung können wir die Mehrheit der Knoten am primären Standort platzieren, während sich die Minderheit der Knoten am Standort für die Notfallwiederherstellung befindet, wie im folgenden Screenshot für ein 3- Knoten Galera-Cluster:
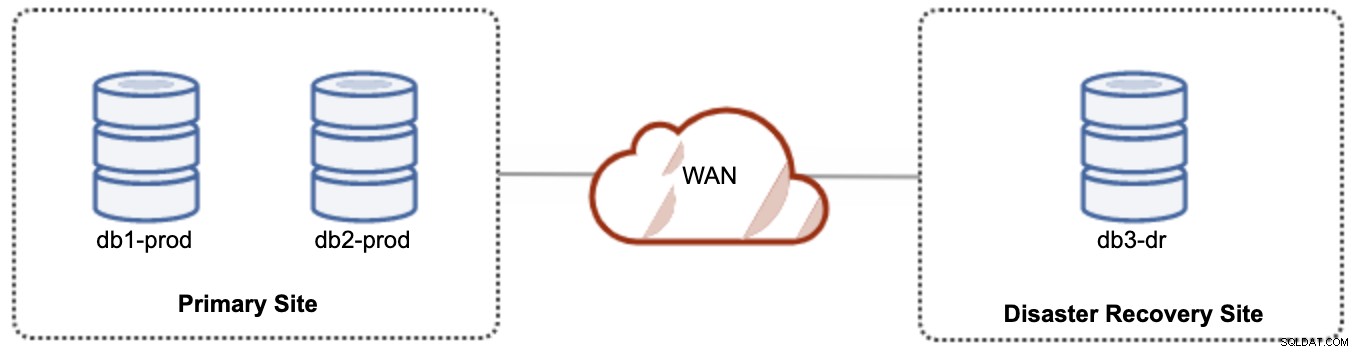
Wenn der primäre Standort ausgefallen ist, schlägt der Cluster fehl, da er kein Quorum mehr hat. Der Galera-Knoten auf der Disaster-Recovery-Site (db3-dr) muss manuell als Primärkomponente mit einem einzelnen Knoten gebootstrapped werden. Sobald die primäre Site wieder verfügbar ist, müssen beide Knoten auf der primären Site (db1-prod und db2-prod) wieder galera3 beitreten, um synchronisiert zu werden. Ein ziemlich großer gcache sollte dazu beitragen, das Risiko von SST über WAN zu verringern. Diese Architektur ist einfach einzurichten und zu verwalten und sehr kostengünstig.
Failover ist manuell, da der Administrator den einzelnen Knoten als primäre Komponente heraufstufen muss (bootstrap db3-dr oder set pc.bootstrap=1 im Parameter wsrep_provider_options verwenden. In der Zwischenzeit würde es zu Ausfallzeiten kommen . Die Leistung kann ein Problem darstellen, da der DR-Standort mit einer geringeren Anzahl von Knoten ausgeführt wird (da der DR-Standort immer die Minderheit ist), um die gesamte Last auszuführen. Es ist möglicherweise möglich, nach dem Wechsel zu mehr Knoten aufzuskalieren DR-Site, aber achten Sie auf die zusätzliche Belastung.
Beachten Sie, dass Galera Cluster aufgrund seiner praktisch synchronen Natur empfindlich auf das Netzwerk reagiert. Je weiter die Galera-Knoten in einem bestimmten Cluster sind, desto höher sind die Latenz und die Schreibfähigkeit, um die Writesets zu verteilen und zu zertifizieren. Wenn die Konnektivität nicht stabil ist, kann es außerdem leicht zu einer Clusterpartitionierung kommen, die eine Clustersynchronisierung auf den Joiner-Knoten auslösen könnte. In einigen Fällen kann dies zu einer Instabilität des Clusters führen. Dies erfordert ein wenig Feinabstimmung der Galera-Parameter, wie in diesem Blogbeitrag Deploying a Hybrid Infrastructure Environment for Percona XtraDB Cluster gezeigt.
Abschließende Gedanken
Galera Cluster ist eine großartige Technologie, die auf unterschiedliche Weise bereitgestellt werden kann – ein Cluster erstreckt sich über mehrere Standorte, mehrere Cluster werden über asynchrone Replikation synchron gehalten, eine Mischung aus synchroner und asynchroner Replikation und so weiter. Die tatsächliche Lösung wird von Faktoren wie WAN-Latenz, letztendlicher versus starker Datenkonsistenz und Budget bestimmt.