Dies ist der erste Artikel einer Reihe von Artikeln über In-Memory-OLTP. Es hilft Ihnen zu verstehen, wie die neue Hekaton-Engine intern funktioniert. Wir werden uns auf Details von In-Memory-optimierten Tabellen und Indizes konzentrieren. Dies ist der Einstiegsartikel, was bedeutet, dass Sie kein SQL Server-Experte sein müssen, jedoch einige grundlegende Kenntnisse über die traditionelle SQL Server-Engine haben müssen.
Einführung
Die In-Memory-OLTP-Engine von SQL Server 2014 (Hekaton-Projekt) wurde von Grund auf neu entwickelt, um Terabytes an verfügbarem Arbeitsspeicher und eine große Anzahl von Verarbeitungskernen zu nutzen. In-Memory OLTP ermöglicht es Benutzern, mit speicheroptimierten Tabellen und Indizes sowie nativ kompilierten gespeicherten Prozeduren zu arbeiten. Sie können es zusammen mit den festplattenbasierten Tabellen und Indizes sowie den gespeicherten T-SQL-Prozeduren verwenden, die SQL Server schon immer bereitgestellt hat.
Die Interna und Funktionen der In-Memory-OLTP-Engine unterscheiden sich erheblich von der standardmäßigen relationalen Engine. Sie müssen fast alles überarbeiten, was Sie darüber wussten, wie mehrere gleichzeitige Prozesse gehandhabt werden.
Die SQL Server-Engine ist für datenträgerbasierten Speicher optimiert. Es liest 8-KB-Datenseiten zur Verarbeitung in den Speicher und schreibt 8-KB-Datenseiten nach Änderungen zurück auf die Festplatte. Natürlich korrigiert SQL Server in erster Linie die Änderungen auf der Festplatte im Transaktionsprotokoll. Das Lesen von 8-KB-Datenseiten von der Festplatte und das Zurückschreiben kann eine Menge I/O generieren und führt zu höheren Latenzkosten. Selbst wenn sich die Daten im Puffer-Cache befinden, nimmt der SQL-Server an, dass dies nicht der Fall ist, was zu einer ineffizienten CPU-Auslastung führt.
In Anbetracht der Einschränkungen herkömmlicher plattenbasierter Speicherstrukturen begann das SQL Server-Team mit dem Aufbau einer Datenbank-Engine, die für großen Hauptspeicher und CPUs mit mehreren Kernen optimiert ist. Das Team hat sich folgende Ziele gesetzt:
- Optimiert für Daten, die vollständig im Arbeitsspeicher gespeichert wurden, aber auch bei Neustarts von SQL Server dauerhaft waren
- Vollständig in die vorhandene SQL Server-Engine integriert
- Sehr hohe Leistung für OLTP-Operationen
- Entwickelt für moderne CPUs
SQL Server In-Memory OLTP erfüllt all diese Ziele.
Über In-Memory-OLTP
SQL Server 2014 In-Memory OLTP bietet eine Reihe von Technologien zum Arbeiten mit speicheroptimierten Tabellen zusammen mit den datenträgerbasierten Tabellen. So können Sie beispielsweise über Standardschnittstellen wie T-SQL und SSMS auf In-Memory-Daten zugreifen. Die folgende Abbildung zeigt speicheroptimierte Tabellen und Indizes als Teil von In-Memory OLTP (links) und die festplattenbasierten Tabellen (links), die 8-KB-Datenseiten lesen und schreiben müssen. In-Memory-OLTP unterstützt auch nativ kompilierte gespeicherte Prozeduren und bietet einen neuen In-Memory-OLTP-Compiler.
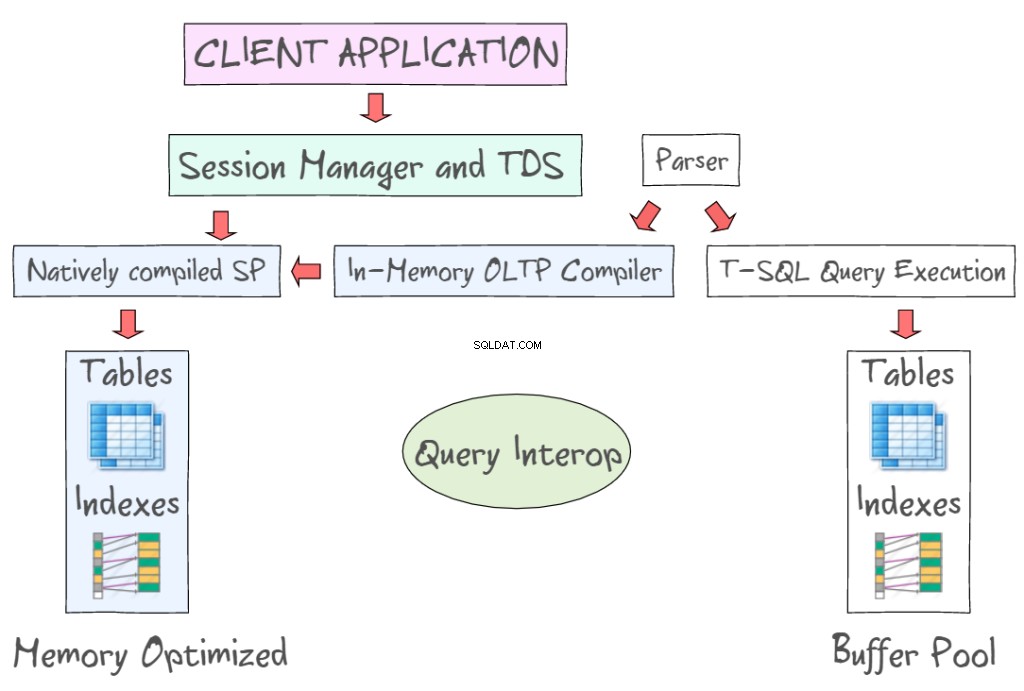
Query Interop ermöglicht das Interpretieren von T-SQL, um auf speicheroptimierte Tabellen zu verweisen. Wenn eine Transaktion sowohl auf speicheroptimierte als auch auf datenträgerbasierte Tabellen verweist, kann sie als containerübergreifende Transaktion bezeichnet werden. Die Client-App verwendet Tabular Data Stream – ein Protokoll der Anwendungsschicht, das zum Übertragen von Daten zwischen einem Datenbankserver und einem Client verwendet wird. Es wurde ursprünglich 1984 von Sybase Inc. für ihre relationale Datenbank-Engine Sybase SQL Server und später von Microsoft in Microsoft SQL Server entworfen und entwickelt.
Speicheroptimierte Tabellen
Beim Zugriff auf plattenbasierte Tabellen können sich die erforderlichen Daten bereits im Arbeitsspeicher befinden, obwohl dies möglicherweise nicht der Fall ist. Wenn sich Daten nicht im Arbeitsspeicher befinden, muss SQL Server sie von der Festplatte lesen. Der grundlegendste Unterschied bei der Verwendung von speicheroptimierten Tabellen besteht darin, dass die gesamte Tabelle und ihre Indizes ständig im Speicher gespeichert werden . Gleichzeitige Datenoperationen erfordern kein Sperren oder Zwischenspeichern.
Während ein Benutzer In-Memory-Daten ändert, führt SQL Server einige Festplatten-I/Os für jede Tabelle aus, die dauerhaft sein muss, anders gesagt, wo wir eine Tabelle benötigen, um In-Memory-Daten zum Zeitpunkt eines Serverabsturzes oder -neustarts beizubehalten.
Zeilenbasierte Speicherstruktur
Ein weiterer wesentlicher Unterschied ist die zugrunde liegende Speicherstruktur. Die festplattenbasierten Tabellen sind für blockadressierbar optimiert Festplattenspeicher, wohingegen In-Memory-optimierte Tabellen für Byte-adressierbar optimiert sind Speicher.
SQL Server speichert Datenzeilen in 8-KByte-Datenseiten mit Speicherplatzzuweisung von Extents für datenträgerbasierte Tabellen. Die Datenseite ist die grundlegende Einheit der Festplatten- und Speicherspeicherung. Beim Lesen und Schreiben von Daten vom Datenträger liest und schreibt SQL Server nur die relevanten Datenseiten. Eine Datenseite enthält nur Daten aus einer Tabelle oder einem Index. Anwendungsprozesse ändern nach Bedarf Zeilen auf verschiedenen Datenseiten. Später, während des CHECKPOINT-Vorgangs, korrigiert SQL Server zunächst die Protokolldatensätze auf dem Datenträger und schreibt dann alle fehlerhaften Seiten auf den Datenträger. Diese Operation verursacht oft viele zufällige physische E/A.
Für speicheroptimierte Tabellen gibt es weder Datenseiten noch Extents. Es werden nur Datenzeilen sequentiell in den Speicher geschrieben, in der Reihenfolge, in der die Transaktionen aufgetreten sind. Jede Zeile enthält einen Indexzeiger auf die nächste Zeile. Alle I/O-Vorgänge sind In-Memory-Scanning dieser Strukturen. Es gibt keine Vorstellung davon, dass Datenzeilen an eine bestimmte Stelle geschrieben werden, die zu einem bestimmten Objekt gehört. Sie müssen jedoch nicht glauben, dass speicheroptimierte Tabellen als unorganisierter Satz von Datenzeilen gespeichert werden (ähnlich wie festplattenbasierte Heaps). Jede CREATE TABLE-Anweisung für eine speicheroptimierte Tabelle erstellt mindestens einen Index, den SQL Server verwendet, um alle Datenzeilen in dieser Tabelle miteinander zu verknüpfen.
Jede einzelne Datenzeile besteht aus dem Zeilenkopf und der Nutzlast, also den eigentlichen Spaltendaten. Der Header speichert Informationen über die Anweisung, die die Zeile erstellt hat, Zeiger für jeden Index in der Zieltabelle und Zeitstempelwerte. Der Zeitstempel gibt die Zeit an, zu der eine Transaktion eine Zeile eingefügt und gelöscht hat. SQL Server-Datensätze wurden aktualisiert, indem eine neue Zeilenversion eingefügt und die alte Version als gelöscht markiert wurde. Es können jederzeit mehrere Versionen derselben Zeile vorhanden sein. Dies ermöglicht den gleichzeitigen Zugriff auf dieselbe Zeile während der Datenänderung. SQL Server zeigt die für jede Transaktion relevante Zeilenversion gemäß dem Zeitpunkt an, zu dem die Transaktion gestartet wurde, relativ zu den Zeitstempeln der Zeilenversion. Dies ist der Kern der neuen Multi-Versions-Parallelitätssteuerung Mechanismus für In-Memory-Tabellen.
Übrigens hat Oracle ein hervorragendes Multiversionskontrollsystem. Grundsätzlich funktioniert es wie folgt:
- Benutzer A startet eine Transaktion und aktualisiert 1000 Zeilen mit einem Wert zum Zeitpunkt T1.
- Benutzer B liest dieselben 1000 Zeilen zum Zeitpunkt T2.
- Benutzer A aktualisiert Zeile 565 mit Wert Y (ursprünglicher Wert war X).
- Benutzer B erreicht Zeile 565 und stellt fest, dass eine Transaktion seit dem Zeitpunkt T1 in Betrieb ist.
- Die Datenbank gibt den unveränderten Datensatz aus den Protokollen zurück. Der zurückgegebene Wert ist der Wert, der zum Zeitpunkt kleiner oder gleich T2 übergeben wurde.
- Wenn der Datensatz nicht aus den Redo-Protokollen abgerufen werden konnte, bedeutet dies, dass die Datenbank nicht richtig eingerichtet ist. Den Protokollen muss mehr Speicherplatz zugewiesen werden.
- Die zurückgegebenen Ergebnisse sind in Bezug auf die Startzeit der Transaktion immer gleich. Innerhalb der Transaktion wird also die Lesekonsistenz erreicht.
Nativ kompilierte Tabellen
Der letzte große Unterschied besteht darin, dass die In-Memory-optimierten Tabellen nativ kompiliert werden . Wenn ein Benutzer eine speicheroptimierte Tabelle oder einen Index erstellt, speichert SQL Server die Struktur jeder Tabelle (zusammen mit allen Indizes) in den Metadaten. Später verwendet SQL Server diese Metadaten, um eine Reihe von systemeigenen Sprachroutinen für den Zugriff auf die Tabelle in DDL zu kompilieren. Solche DDL sind mit der Datenbank verbunden, aber nicht wirklich Teil davon.
Mit anderen Worten, SQL Server speichert nicht nur Tabellen und Indizes, sondern auch DDL für den Zugriff auf und die Änderung dieser Strukturen. Sobald eine Tabelle geändert wurde, muss SQL Server alle DDL für Tabellenoperationen neu erstellen. Aus diesem Grund können Sie eine einmal erstellte Tabelle nicht mehr ändern. Diese Vorgänge sind für Benutzer unsichtbar.
Nativ kompilierte gespeicherte Prozeduren
Die beste Leistung wird erzielt, wenn nativ kompilierte gespeicherte Prozeduren verwendet werden, um auf nativ kompilierte Tabellen zuzugreifen. Solche Prozeduren enthalten Prozessoranweisungen und können ohne weitere Kompilierung direkt von der CPU ausgeführt werden. Es gibt jedoch einige Einschränkungen bei den T-SQL-Konstruktionen für die nativ kompilierten gespeicherten Prozeduren (im Vergleich zu herkömmlich interpretiertem Code). Ein weiterer wichtiger Punkt ist, dass nativ kompilierte gespeicherte Prozeduren nur auf speicheroptimierte Tabellen zugreifen können.
Keine Sperren
In-Memory OLTP ist ein System ohne Sperren. Dies ist möglich, da SQL Server niemals eine vorhandene Zeile ändert. Die UPDATE-Operation erstellt die neue Version und markiert die vorherige Version als gelöscht. Dann fügt sie eine neue Zeilenversion mit neuen Daten darin ein.
Indizes
Wie Sie vielleicht erraten haben, unterscheiden sich Indizes stark von den traditionellen. In-Memory-optimierte Tabellen haben keine Seiten. SQL Server verwendet Indizes, um alle Zeilen, die zu einer Tabelle gehören, in einer einzigen Struktur zu verknüpfen. Wir können die CREATE INDEX-Anweisung nicht verwenden, um einen Index für die im Arbeitsspeicher optimierte Tabelle zu erstellen. Nachdem Sie den PRIMARY KEY für eine Spalte erstellt haben, erstellt SQL Server automatisch einen eindeutigen Index für diese Spalte. Tatsächlich ist dies der einzige zulässige eindeutige Index. Sie können maximal acht Indizes für eine speicheroptimierte Tabelle erstellen.
Analog zu Tabellen hält SQL Server speicheroptimierte Indizes im Arbeitsspeicher. SQL Server protokolliert jedoch niemals Vorgänge für Indizes. SQL Server verwaltet Indizes automatisch während Tabellenänderungen.
Speicheroptimierte Tabellen unterstützen zwei Arten von Indizes:Hash-Index und Bereichsindex . Beides sind nicht geclusterte Strukturen.
Der Hash-Index ist ein neuer Indextyp, der speziell für speicheroptimierte Tabellen entwickelt wurde. Es ist äußerst nützlich, um Suchen nach bestimmten Werten durchzuführen. Der Index selbst wird als Hash-Tabelle gespeichert. Es ist ein Array von Hash-Buckets, wobei jeder Bucket ein Zeiger auf eine einzelne Zeile ist.
Der Bereichsindex (non-clustered) ist nützlich, um Wertebereiche abzurufen.
Wiederherstellung
Der grundlegende Wiederherstellungsmechanismus für eine Datenbank mit speicheroptimierten Tabellen ist derselbe wie der Wiederherstellungsmechanismus von Datenbanken mit datenträgerbasierten Tabellen. Die Wiederherstellung von speicheroptimierten Tabellen umfasst jedoch den Schritt des Ladens der speicheroptimierten Tabellen in den Speicher, bevor die Datenbank für den Benutzerzugriff verfügbar ist.
Wenn SQL Server neu gestartet wird, durchläuft jede Datenbank die folgenden Phasen des Wiederherstellungsprozesses:Analyse , Wiederholen , und rückgängig machen .
In der Analysephase identifiziert die In-Memory-OLTP-Engine das zu ladende Checkpoint-Inventar und lädt seine Systemtabellen-Protokolleinträge vorab. Es verarbeitet auch einige Dateizuordnungsprotokolleinträge.
In der Redo-Phase werden Daten aus den Daten- und Deltadateipaaren in den Speicher geladen. Dann werden die Daten aus dem aktiven Transaktionsprotokoll basierend auf dem letzten dauerhaften Prüfpunkt aktualisiert, und die In-Memory-Tabellen werden gefüllt und die Indizes neu erstellt. Während dieser Phase werden die festplattenbasierte und die speicheroptimierte Tabellenwiederherstellung gleichzeitig ausgeführt.
Die Undo-Phase ist für speicheroptimierte Tabellen nicht erforderlich, da In-Memory OLTP keine nicht festgeschriebenen Transaktionen für speicheroptimierte Tabellen aufzeichnet.
Wenn alle Operationen abgeschlossen sind, steht die Datenbank für den Zugriff zur Verfügung.
Zusammenfassung
In diesem Artikel haben wir einen kurzen Blick auf die In-Memory-OLTP-Engine von SQL Server geworfen. Wir haben gelernt, dass speicheroptimierte Strukturen im Speicher gespeichert werden. Anwendungsprozesse können die erforderlichen Daten finden, indem sie auf diese Strukturen im Speicher zugreifen, ohne dass Platten-I/O erforderlich sind. In den folgenden Artikeln sehen wir uns an, wie Sie In-Memory-OLTP-Datenbanken und -Tabellen erstellen und darauf zugreifen.
Weiterführende Literatur
In-Memory-OLTP:Was ist neu in SQL Server 2016
Verwenden von Indizes in speicheroptimierten SQL Server-Tabellen