Wenn Sie die Funktionalität Ihrer Anwendung oder die Leistung einer bestimmten gespeicherten Prozedur oder einer Ad-hoc-Abfrage in der Entwicklungsumgebung testen, müssen Sie in Ihren Entwicklungsdatenbanken gespeicherte Daten haben, die den in den Produktionsdatenbanken gespeicherten Daten typisch oder ähnlich sind. Dies liegt daran, dass sich die Leistung einer Abfrage, die 50 Datensätze verarbeitet, von der Leistung derselben Abfrage unterscheidet, die 50 Millionen Zeilen verarbeitet. Das Wiederherstellen einer Kopie der Produktionsdatenbank auf dem Entwicklungsdatenbankserver zu Testzwecken ist aufgrund der kritischen Daten, die in diesen Datenbanken gespeichert sind, nicht immer eine gültige Option und sollte nicht für alle Mitarbeiter sichtbar sein, es sei denn, Sie entwickeln eine neue Anwendung und es gibt noch keine Produktionsdatenbank.
Die beste und sicherste Alternative besteht darin, die Entwicklungsdatenbanktabellen mit Testdaten zu füllen. Die Generierung von Testdaten ist nützlich, um die Leistung der Anwendung oder eine neue Funktionalität zu testen, ohne die Produktionsdaten zu ändern. Es gibt keinen einfachen Weg, um Testdaten zu generieren, die für alle Szenarien geeignet sind, insbesondere wenn Sie große Datenmengen generieren müssen, um die Leistung komplexer Abfragen und Transaktionen zu testen, bei denen Sie alle möglichen Kombinationen von Testfällen abdecken sollten.
Um eine Tabelle mit einer großen Datenmenge zu füllen, ist es am einfachsten, ein einfaches Skript zu schreiben, das identische Datensätze mit der erforderlichen Anzahl von Duplikaten in die Datenbanktabelle einfügt. Das Problem besteht jedoch darin, dass der SQL Server-Abfrageoptimierer aufgrund der unterschiedlichen Datenverteilung auf der Entwicklungsdatenbank einen anderen Plan erstellt als auf der Produktionsdatenbank. Das folgende Skript füllt beispielsweise die Tabelle „Schüler“ mit 100.000 redundanten Testdatensätzen unter Verwendung der GO-Nummer Aussage:
INSERT INTO Students (FirstName, LastName, BirthDate, STDAddress) VALUES ('John','Horold','2005-10-01','London, St15')
GO 25000
INSERT INTO Students (FirstName, LastName, BirthDate, STDAddress) VALUES ('Mike','Zikle','2005-06-08','London, St18')
GO 25000
INSERT INTO Students (FirstName, LastName, BirthDate, STDAddress) VALUES ('Faruk','Cedrik','2005-03-15','London, St24')
GO 25000
INSERT INTO Students (FirstName, LastName, BirthDate, STDAddress) VALUES ('Faisal','Ali','2005-12-05','London, St41')
GO 25000 Eine weitere Option besteht darin, Zufallsdaten abhängig vom Datentyp jeder Spalte zu generieren. Die ID-Spalte mit IDENTITY-Eigenschaft generiert automatisch Sequenznummern, ohne dass von Ihrer Seite ein Codierungsaufwand erforderlich ist. Wenn Sie jedoch vorhaben, zufällige Noten für die Schüler zu generieren, können Sie von RAND() profitieren T-SQL-Funktion und wandeln Sie das Ergebnis in den erforderlichen numerischen Datentyp um. Das folgende Skript generiert beispielsweise 100.000 zufällige Noten für den Schüler zwischen 1 und 100 mit drei verschiedenen Datentypen:INTEGER-Noten, REAL-Noten und DEZIMAL-Noten, mit der Möglichkeit, die Bereiche dieser Werte abhängig von Ihren mathematischen und Programmierkenntnissen zu steuern , wie unten gezeigt:
INSERT INTO StudentsGrades (STDGrade) VALUES (CAST(RAND(CHECKSUM(NEWID()))*100 as int)) AS INT_Grage GO 100000 INSERT INTO StudentsGrades (STDGrade) VALUES (CAST(RAND(CHECKSUM(NEWID()))*100 as real)) AS Real_Grage GO 100000 INSERT INTO StudentsGrades (STDGrade) VALUES (CAST(RAND(CHECKSUM(NEWID()))*100 as decimal(6,2))) AS Decimal_Grage GO 100000
Das Generieren zufälliger Namen kann auch mit den Microsoft-Testdatenbanken von AdventureWorks und Northwind erreicht werden . Sie müssen diese Datenbanken von der Microsoft-Website herunterladen, diese Datenbanken an Ihre SQL Server-Instanz anhängen und die in diesen Datenbanken gespeicherten Daten nutzen, um zufällige Namen in Ihrer Entwicklungsdatenbank zu generieren. Beispielsweise enthält die DimCustomer-Tabelle aus der AdventureworksDW2016CTP3-Datenbank etwa 18.000 Vornamen, zweite Vornamen und Nachnamen, die Sie verwenden können. Sie können auch eine CROSS JOIN-Anweisung verwenden, um eine große Anzahl von Kombinationen dieser Namen zu generieren, um den Wert von 18 KB zu überschreiten. Das folgende Skript kann verwendet werden, um 100.000 Vornamen und Nachnamen zu generieren:
INSERT INTO StudentsGrades (First_Name, Last_Name) SELECT TOP 100000 N.[FirstName],cN.[LastName] FROM AdventureworksDW2016CTP3.[dbo].[DimCustomer] N CROSS JOIN AdventureworksDW2016CTP3.[dbo].[DimCustomer] cN
Aus den Microsoft-Testdatenbanken können auch zufällige E-Mail-Adressen und Daten generiert werden. Die Spalte „BirthDate“ und die Spalte „EmailAddress“ aus derselben DimCustomer-Tabelle können uns beispielsweise zufällige Daten und E-Mail-Adressen liefern. Das folgende Skript kann verwendet werden, um eine 100.000-Kombination aus Geburtsdaten und E-Mail-Adressen zu generieren:
INSERT INTO StudentsGrades (BirthDate, EmailAddress) SELECT TOP 100000 N.BirthDate,cN.EmailAddress FROM AdventureworksDW2016CTP3.[dbo].[DimCustomer] N CROSS JOIN AdventureworksDW2016CTP3.[dbo].[DimCustomer] c
Zufallswerte der Country-Spalte können auch mithilfe der Person.CountryRegion-Tabelle aus der AdventureWorks2016CTP3-Testdatenbank generiert werden. Es kann Ihnen mehr als 200 Ländernamen und -codes liefern, die Sie in Ihrer Entwicklungsdatenbank nutzen können. Sie können es beispielsweise als Nachschlagetabelle verwenden, um den Ländernamen und den Code wie im folgenden Skript zuzuordnen:
INSERT INTO MappedConutries (CountryRegionCode, Name) SELECT [CountryRegionCode],[Name] FROM [AdventureWorks2016CTP3].[Person].[CountryRegion] Then insert a random name or country code from these countries that has ID equal to a random ID generated between 1 and 238, as the script below: INSERT INTO StudentsGrades (Country_Name) values ( (SELECT NAME FROM MappedConutries WHERE ID=CAST(RAND(CHECKSUM(NEWID()))*238 as int))) GO 10000
Um zufällige Adresswerte zu generieren, können Sie von den in der Person gespeicherten Daten profitieren. Adresstabelle aus der AdventureWorks2016CTP3-Testdatenbank. Es enthält mehr als 19.000 verschiedene Adressen mit ihrer räumlichen Position, die Sie problemlos in Ihrer Entwicklungsdatenbank verwenden und aus diesen Werten zufällig kombinieren können, so wie wir es im vorherigen Beispiel getan haben. Das folgende Skript kann einfach verwendet werden, um zufällige 100.000 Adressen aus der Person.Address-Tabelle zu generieren:
INSERT INTO StudentsGrades (STD_Address) values ( (SELECT NAME FROM [AdventureWorks2016CTP3].[Person].[Address] WHERE [AddressID]=CAST(RAND(CHECKSUM(NEWID()))*19614 as int))) GO 100000
Um zufällige Passwörter für bestimmte Systembenutzer zu generieren, können wir die Vorteile von CRYPT_GEN_RANDOM nutzen T-SQL-Funktion. Diese Funktion gibt eine kryptografische, zufällig generierte Hexadezimalzahl mit einer Länge einer bestimmten Anzahl von Bytes zurück, die von der Crypto-API (CAPI) generiert wurde. Der von dieser Funktion zurückgegebene Wert kann in einen VARCHAR-Datentyp konvertiert werden, um aussagekräftigere Passwörter zu haben, wie im folgenden Skript, das ein zufälliges 100-KB-Passwort generiert:
INSERT INTO SystemUsers (User_Password) SELECT CONVERT(varchar(20), CRYPT_GEN_RANDOM(20)) GO 100000
Das Generieren von Testdaten zum Füllen der Entwicklungsdatenbanktabellen kann ebenfalls einfach und ohne Zeitverschwendung für das Schreiben von Skripten für jeden Datentyp oder die Verwendung von Tools von Drittanbietern durchgeführt werden. Auf dem Markt finden Sie verschiedene Tools, mit denen Testdaten generiert werden können. Eines dieser wunderbaren Tools ist der dbForge Data Generator für SQL Server . Es ist ein leistungsstarkes GUI-Tool zur schnellen Generierung aussagekräftiger Testdaten für die Entwicklungsdatenbanken. Das dbForge-Datengenerierungstool enthält über 200 vordefinierte Datengeneratoren mit sinnvollen Konfigurationsoptionen, mit denen Sie spaltenintelligente Zufallsdaten emulieren können. Das Tool ermöglicht auch das Generieren von Demodaten für bereits mit Daten gefüllte SQL Server-Datenbanken und das Erstellen eigener benutzerdefinierter Testdatengeneratoren. dbForge Data Generator for SQL Server kann Ihre Zeit und Mühe sparen, die Sie für die Generierung von Demodaten aufgewendet haben, indem Sie SQL Server-Tabellen mit Millionen von Zeilen mit Beispieldaten füllen, die genau wie echte Daten aussehen. dbForge Data Generator for SQL Server hilft beim Füllen von Tabellen mit den am häufigsten verwendeten Datentypen wie Basis-, Geschäfts-, Gesundheits-, IT-, Standort-, Zahlungs- und Personendatentypen. Die folgende Abbildung zeigt, wie einfach dieses Tool funktioniert:

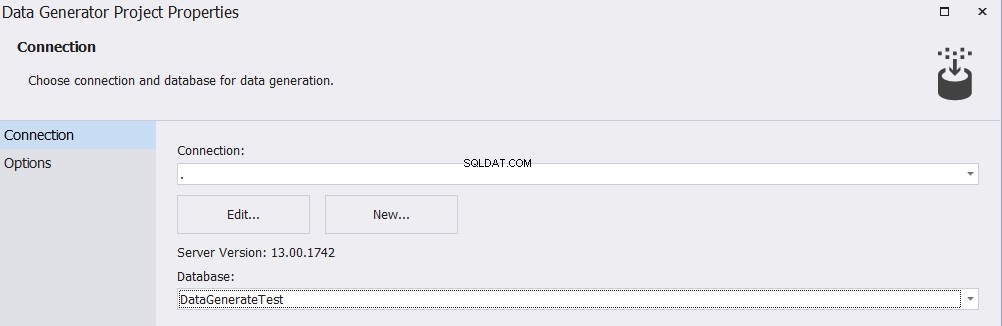
Nachdem Sie das Tool dbForge Data Generator for SQL Server installiert und ausgeführt haben, müssen Sie den Namen des Zielservers und der Datenbank im Verbindungsfenster wie unten gezeigt angeben:
Im Fenster Optionen können Sie die Anzahl der Zeilen angeben, die in Ihre Tabelle eingefügt werden sollen, und andere verschiedene Optionen, die die Kriterien für die generierten Testdaten steuern, wie unten gezeigt:
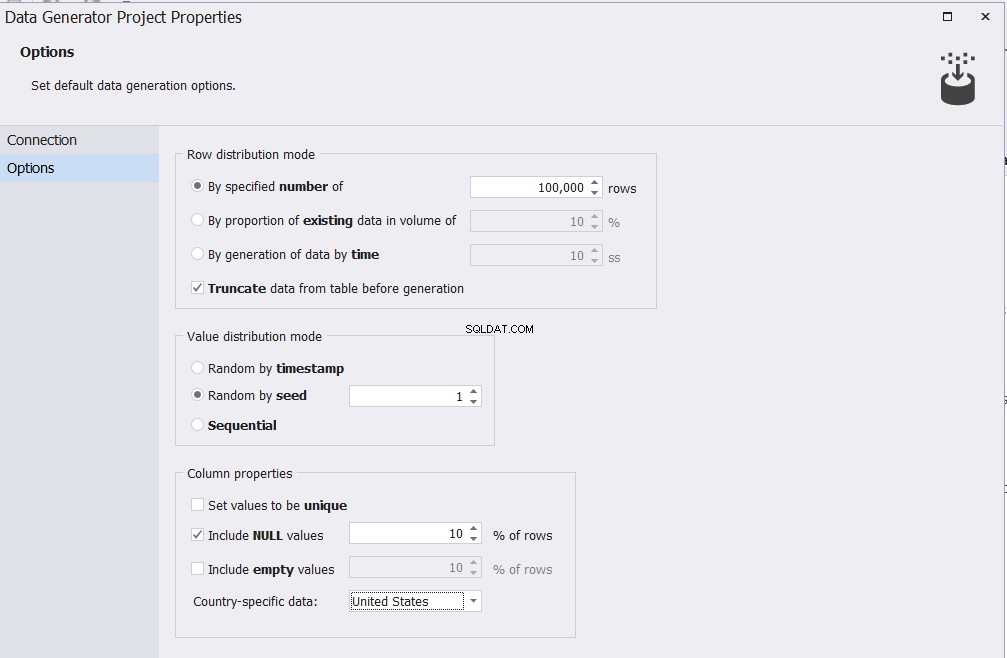
Nachdem Sie die Optionen an Ihre Testdatenanforderungen angepasst haben, klicken Sie auf  , und ein neues Fenster mit einer Liste aller Tabellen und Spalten unter der ausgewählten Datenbank wird angezeigt und Sie werden gefragt Sie können auswählen, welche Tabelle mit Testdaten gefüllt werden soll, wie unten gezeigt:
, und ein neues Fenster mit einer Liste aller Tabellen und Spalten unter der ausgewählten Datenbank wird angezeigt und Sie werden gefragt Sie können auswählen, welche Tabelle mit Testdaten gefüllt werden soll, wie unten gezeigt:
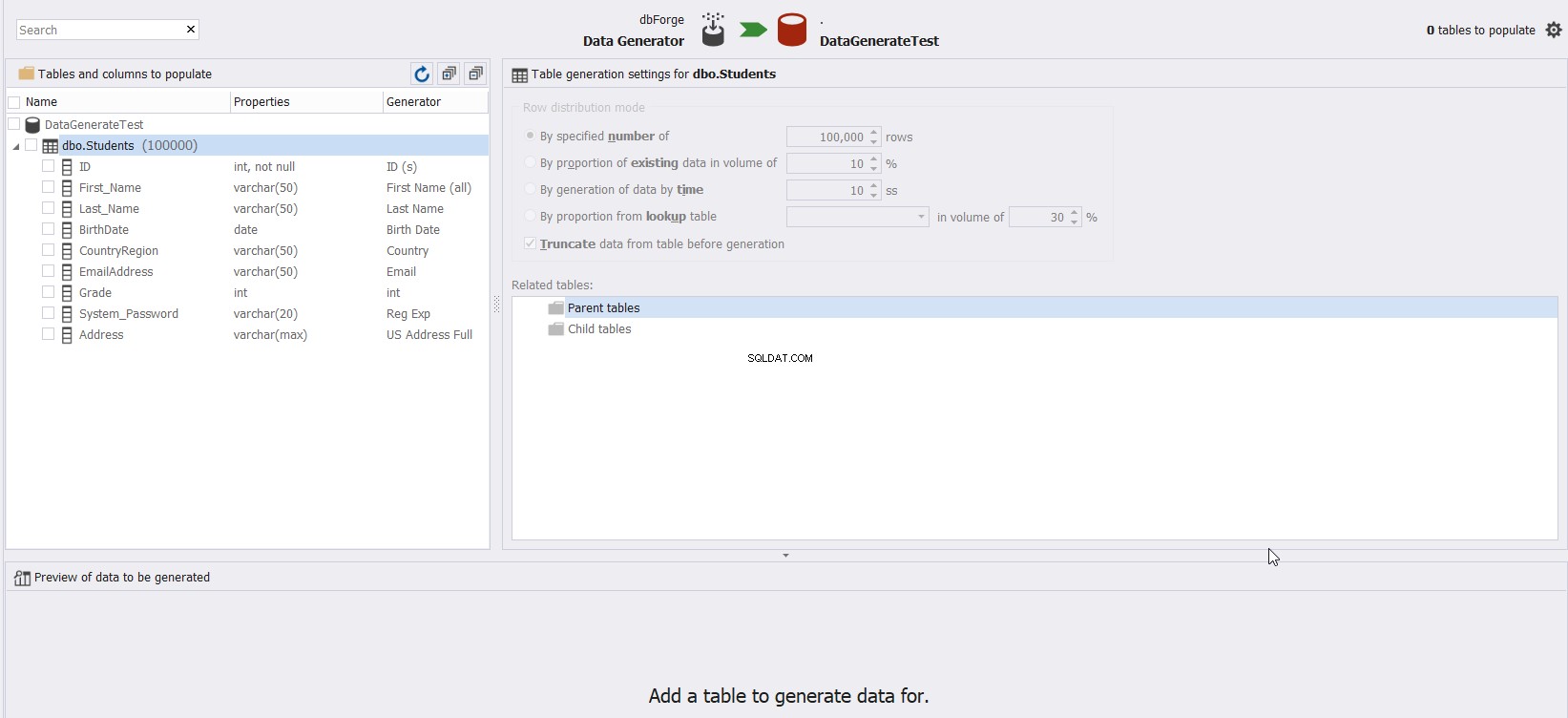
Wählen Sie einfach die Tabelle aus, die Sie mit Daten füllen müssen, und das Tool stellt Ihnen automatisch die vorgeschlagenen Daten im Vorschaubereich unten im Fenster und anpassbare Optionen für jede Spalte in dieser Tabelle zur Verfügung, die Sie wie gezeigt leicht anpassen können unten:
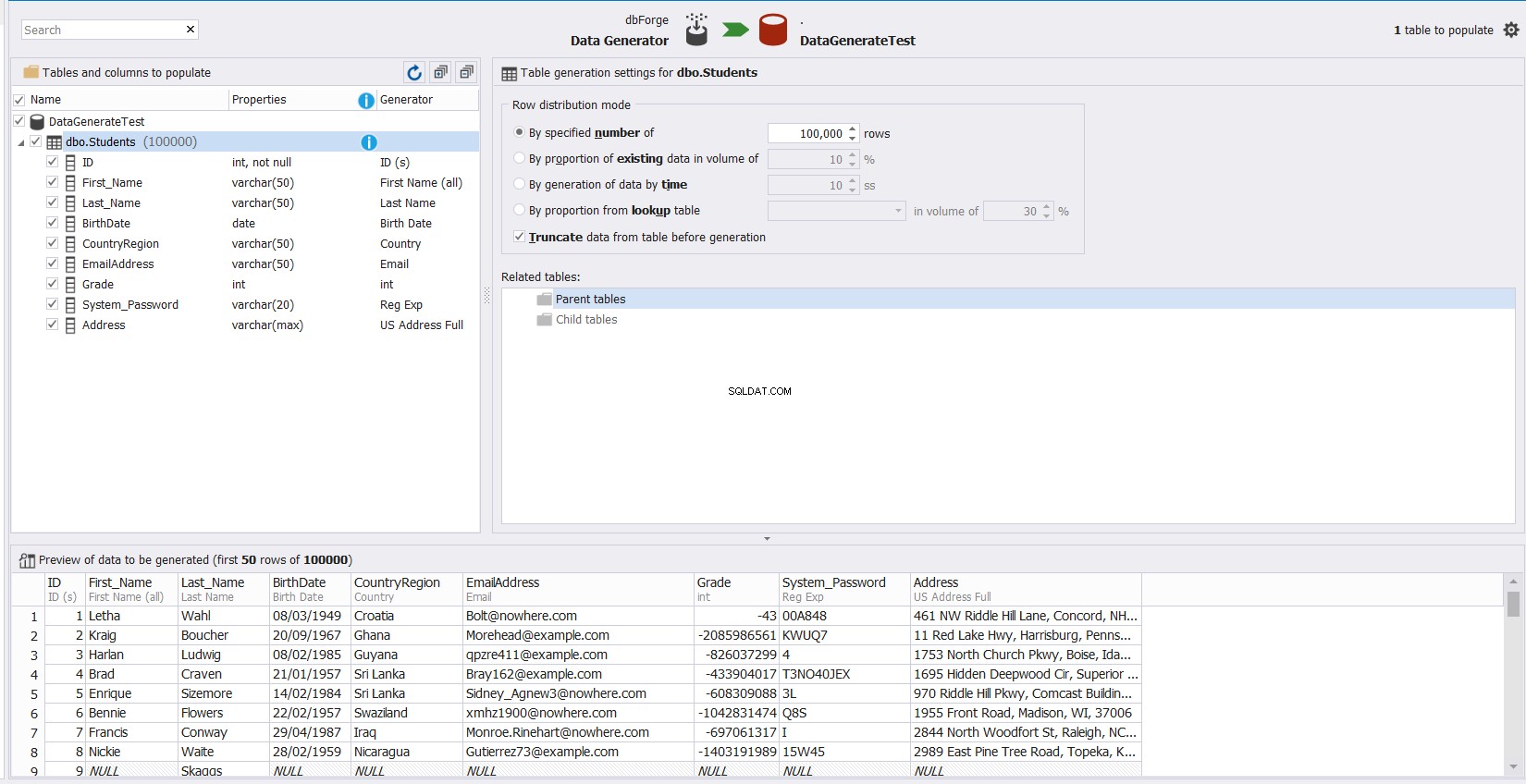
Beispielsweise können Sie aus den integrierten Generatordatentypen auswählen, die verwendet werden können, um die ID-Spaltenwerte wie zuvor beschrieben zu generieren:
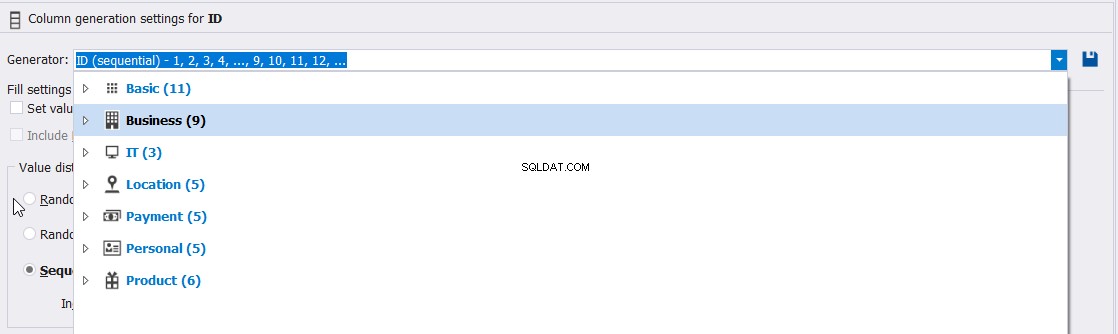
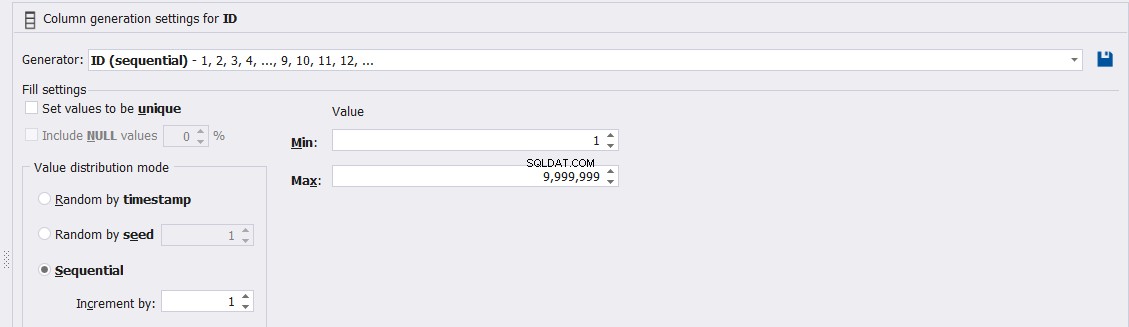
Oder passen Sie die Eigenschaften dieser ID-Spaltenwerte wie Eindeutigkeit, Min, Max und das Inkrement der generierten Werte wie folgt an:
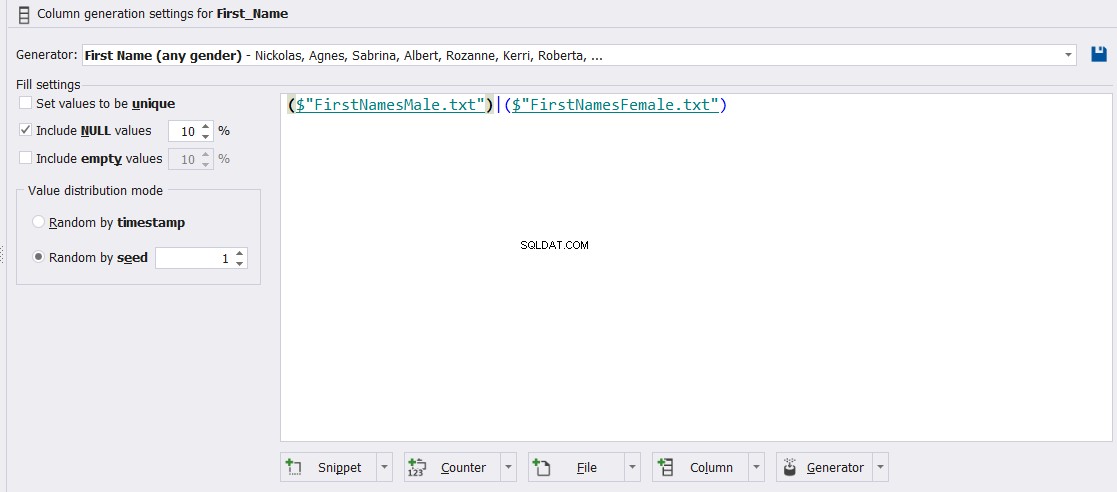
Darüber hinaus kann die Spalte First_Name auf männlich oder weiblich oder eine Kombination dieser beiden Typen beschränkt werden. Außerdem können Sie den Prozentsatz von NULL- oder leeren Werten innerhalb dieser Spalte steuern, wie unten gezeigt:
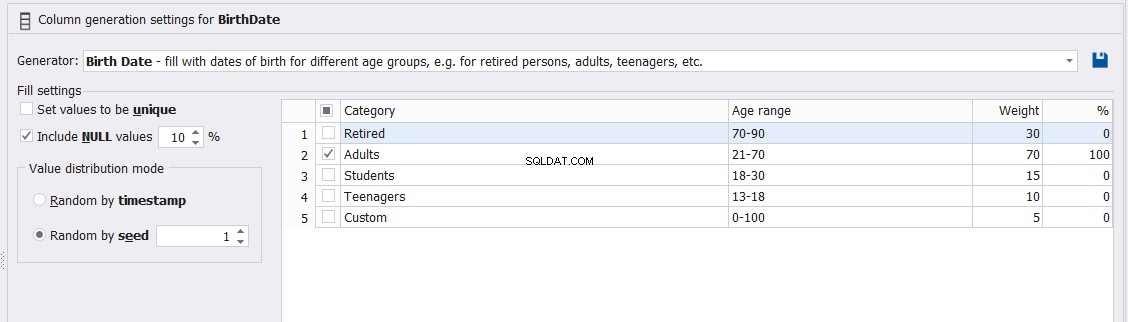
Die Spalte „Geburtsdatum“ kann auch gesteuert werden, indem Sie die Kategorie angeben, unter die diese Schüler fallen, wie z. B. „Studenten“, „Jugendliche“, „Erwachsene“ oder „Rentner“, wie unten gezeigt:
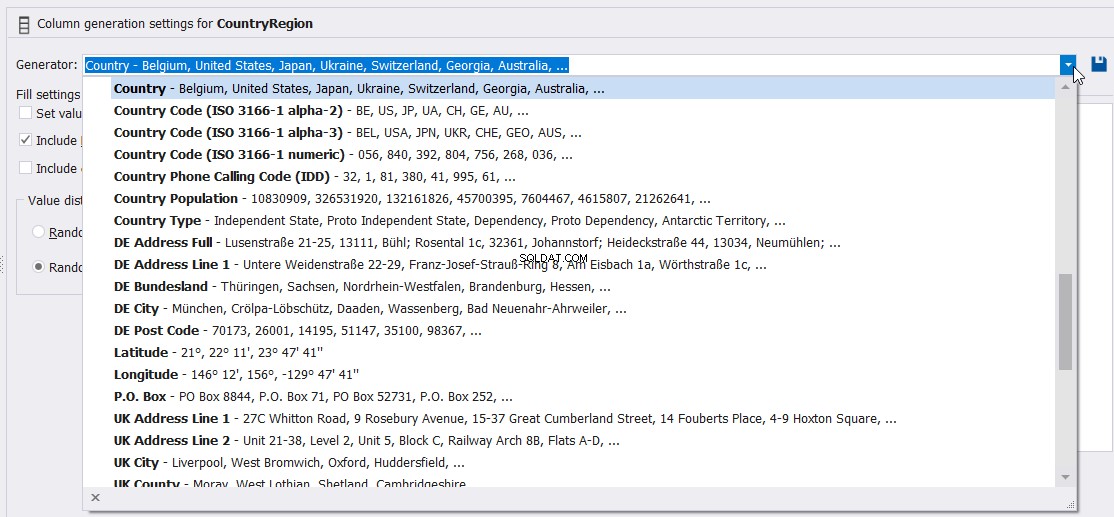
Sie können auch den vollständig beschriebenen Generator angeben, der zum Generieren der Country-Spaltenwerte wie unten gezeigt verwendet werden kann:
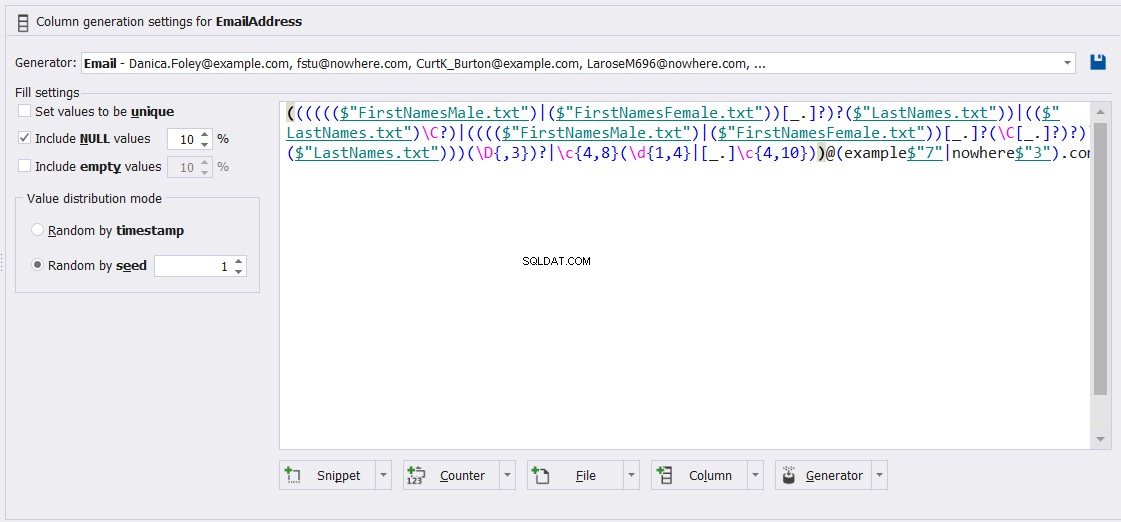
Und passen Sie die Gleichung, die verwendet wird, um die Werte der E-Mail-Adresse-Spalte zu generieren, wie folgt an:
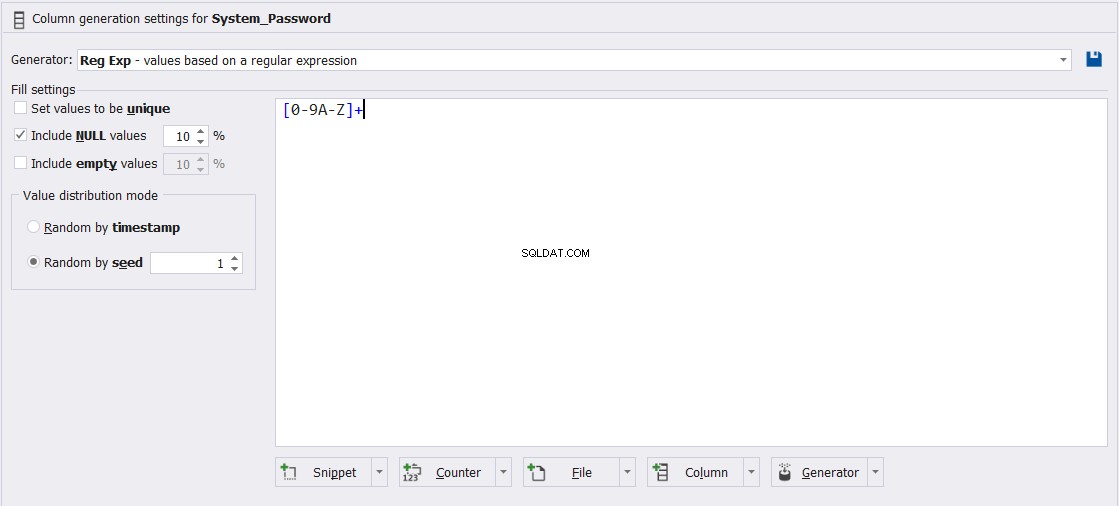
Zusätzlich zur Komplexität der anpassbaren Gleichung generieren wir die Passwort-Spaltenwerte, wie unten gezeigt:
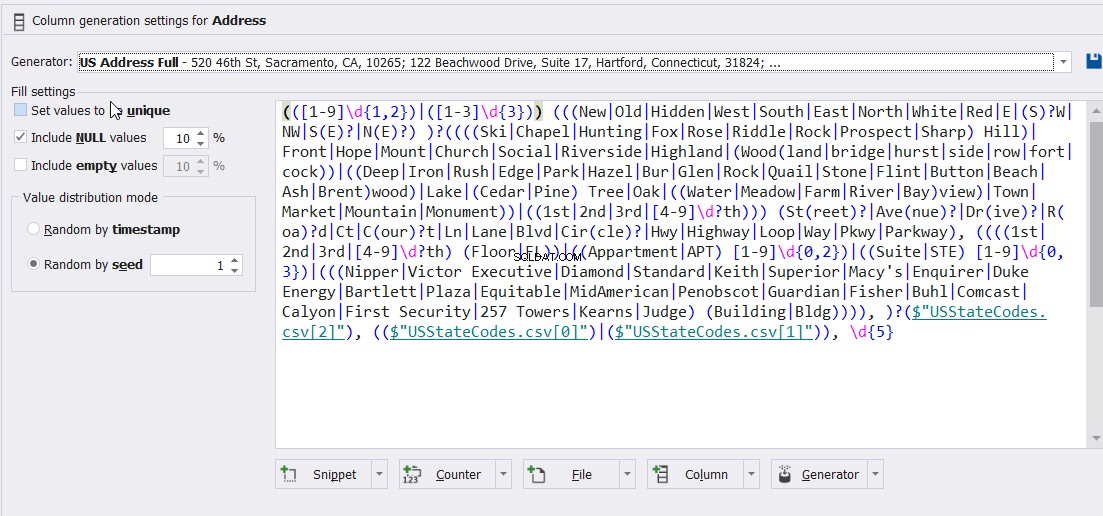
Und schließlich, für mein Beispiel und nicht für dieses magische Werkzeug, die Generatoren und Gleichungen, die verwendet werden, um die folgenden Adressspaltenwerte zu generieren:
Nach dieser Tour können Sie sich vorstellen, wie dieses magische Tool Ihnen helfen wird, Daten zu generieren und Echtzeitszenarien zu simulieren, um die Funktionalität Ihrer Anwendung zu testen. Installieren Sie es und profitieren Sie von allen verfügbaren Funktionen und Optionen.
Nützliches Tool:
dbForge Data Generator for SQL Server – leistungsstarkes GUI-Tool zur schnellen Generierung aussagekräftiger Testdaten für SQL Server-Datenbanken.