Einführung
Egal wie sehr wir uns bemühen, Anwendungen zu entwerfen und zu entwickeln, Fehler werden immer auftreten. Es gibt zwei allgemeine Kategorien – Syntax- oder logische Fehler können entweder Programmfehler oder Folgen eines falschen Datenbankdesigns sein. Andernfalls erhalten Sie möglicherweise eine Fehlermeldung aufgrund falscher Benutzereingaben.
T-SQL (die Programmiersprache von SQL Server) ermöglicht die Behandlung beider Fehlertypen. Sie können die Anwendung debuggen und entscheiden, was Sie tun müssen, um Fehler in Zukunft zu vermeiden.
Die meisten Anwendungen erfordern, dass Sie Fehler protokollieren, benutzerfreundliche Fehlerberichte implementieren und, wenn möglich, Fehler behandeln und die Anwendungsausführung fortsetzen.
Benutzer behandeln Fehler auf Anweisungsebene. Das bedeutet, wenn Sie eine Reihe von SQL-Befehlen ausführen und das Problem in der letzten Anweisung auftritt, wird alles, was diesem Problem vorausgeht, als implizite Transaktionen an die Datenbank übertragen. Dies ist möglicherweise nicht das, was Sie wünschen.
Relationale Datenbanken sind für die Ausführung von Stapelanweisungen optimiert. Daher müssen Sie einen Stapel von Anweisungen als eine Einheit ausführen und alle Anweisungen fehlschlagen lassen, wenn eine Anweisung fehlschlägt. Sie können dies erreichen, indem Sie Transaktionen verwenden. Dieser Artikel konzentriert sich sowohl auf die Fehlerbehandlung als auch auf Transaktionen, da diese Themen eng miteinander verbunden sind.
SQL-Fehlerbehandlung
Um Ausnahmen zu simulieren, müssen wir sie auf wiederholbare Weise erzeugen. Beginnen wir mit dem einfachsten Beispiel – Division durch Null:
SELECT 1/0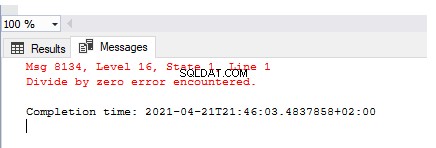
Die Ausgabe beschreibt den ausgelösten Fehler – Fehler bei Division durch Null . Aber dieser Fehler wurde nicht behandelt, protokolliert oder angepasst, um eine benutzerfreundliche Nachricht zu erzeugen.
Die Ausnahmebehandlung beginnt damit, dass Sie Anweisungen, die Sie ausführen möchten, in den Block BEGIN TRY…END TRY einfügen.
SQL Server verarbeitet (fängt) Fehler im Block BEGIN CATCH…END CATCH, wo Sie benutzerdefinierte Logik für die Fehlerprotokollierung oder -verarbeitung eingeben können.
Die BEGIN CATCH-Anweisung muss unmittelbar nach der END TRY-Anweisung folgen. Die Ausführung wird dann beim ersten Auftreten eines Fehlers vom TRY-Block an den CATCH-Block übergeben.
Hier können Sie entscheiden, wie mit den Fehlern umgegangen werden soll, ob Sie die Daten über ausgelöste Ausnahmen protokollieren oder eine benutzerfreundliche Nachricht erstellen möchten.
SQL Server verfügt über integrierte Funktionen, die Ihnen beim Extrahieren von Fehlerdetails helfen können:
- ERROR_NUMBER():Gibt die Anzahl der SQL-Fehler zurück.
- ERROR_SEVERITY():Gibt den Schweregrad zurück, der die Art des aufgetretenen Problems und dessen Schweregrad angibt. Die Ebenen 11 bis 16 können vom Benutzer bedient werden.
- ERROR_STATE():Gibt die Fehlerzustandsnummer zurück und liefert weitere Details über die ausgelöste Ausnahme. Sie verwenden die Fehlernummer, um die Microsoft-Wissensdatenbank nach bestimmten Fehlerdetails zu durchsuchen.
- ERROR_PROCEDURE():Gibt den Namen der Prozedur oder des Triggers zurück, in dem der Fehler ausgelöst wurde, oder NULL, wenn der Fehler nicht in der Prozedur oder dem Trigger aufgetreten ist.
- ERROR_LINE():Gibt die Zeilennummer zurück, bei der der Fehler aufgetreten ist. Dies kann die Zeilennummer von Prozeduren oder Triggern oder die Zeilennummer im Batch sein.
- ERROR_MESSAGE():Gibt den Text der Fehlermeldung zurück.
Das folgende Beispiel zeigt, wie Fehler behandelt werden. Das erste Beispiel enthält die Division durch Null Fehler, während die zweite Aussage richtig ist.
BEGIN TRY
PRINT 1/0
SELECT 'Correct text'
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH

Wenn die zweite Anweisung ohne Fehlerbehandlung ausgeführt wird (SELECT ‘Korrekter Text’), würde sie erfolgreich sein.
Da wir die benutzerdefinierte Fehlerbehandlung im TRY-CATCH-Block implementieren, wird die Programmausführung nach dem Fehler in der ersten Anweisung an den CATCH-Block übergeben, und die zweite Anweisung wurde nie ausgeführt.
Auf diese Weise können Sie den Text ändern, der dem Benutzer gegeben wird, und besser steuern, was passiert, wenn ein Fehler auftritt. Beispielsweise protokollieren wir Fehler zur weiteren Analyse in einer Protokolltabelle.
Transaktionen verwenden
Die Geschäftslogik bestimmt möglicherweise, dass das Einfügen der ersten Anweisung fehlschlägt, wenn die zweite Anweisung fehlschlägt, oder dass Sie möglicherweise Änderungen an der ersten Anweisung wiederholen müssen, wenn die zweite Anweisung fehlschlägt. Durch die Verwendung von Transaktionen können Sie einen Stapel von Anweisungen als eine Einheit ausführen, die entweder fehlschlägt oder erfolgreich ist.
Das folgende Beispiel demonstriert die Verwendung von Transaktionen.
Zuerst erstellen wir eine Tabelle, um die gespeicherten Daten zu testen. Dann verwenden wir zwei Transaktionen innerhalb des TRY-CATCH-Blocks, um zu simulieren, was passiert, wenn ein Teil der Transaktion fehlschlägt.
Wir werden die CATCH-Anweisung mit der XACT_STATE()-Anweisung verwenden. Die Funktion XACT_STATE() wird verwendet, um zu prüfen, ob die Transaktion noch existiert. Falls die Transaktion automatisch zurückgesetzt wird, würde die ROLLBACK TRANSACTION eine neue Ausnahme erzeugen.
Machen Sie eine Beute mit dem folgenden Code:
-- CREATE TABLE TEST_TRAN(VALS INT)
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(1);
COMMIT TRANSACTION
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(2);
INSERT INTO TEST_TRAN(VALS) VALUES('A');
INSERT INTO TEST_TRAN(VALS) VALUES(3);
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() > 0 ROLLBACK TRANSACTION
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
SELECT * FROM TEST_TRAN
-- DROP TABLE TEST_TRAN
Das Bild zeigt die Werte in der Tabelle TEST_TRAN und Fehlermeldungen:
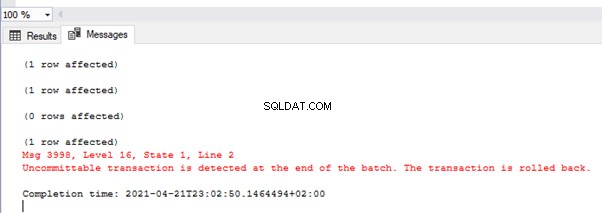
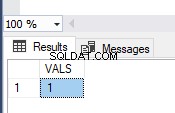
Wie Sie sehen, wurde nur der erste Wert festgeschrieben. Bei der zweiten Transaktion hatten wir einen Typumwandlungsfehler in der zweiten Zeile. Somit wurde der gesamte Batch zurückgesetzt.
Auf diese Weise können Sie steuern, welche Daten in die Datenbank gelangen und wie Stapel verarbeitet werden.
Generieren einer benutzerdefinierten Fehlermeldung in SQL
Manchmal möchten wir benutzerdefinierte Fehlermeldungen erstellen. Normalerweise sind sie für Szenarien gedacht, in denen wir wissen, dass ein Problem auftreten könnte. Wir können unsere eigenen benutzerdefinierten Nachrichten erstellen, die besagen, dass etwas schief gelaufen ist, ohne technische Details anzuzeigen. Dafür verwenden wir das Schlüsselwort THROW.
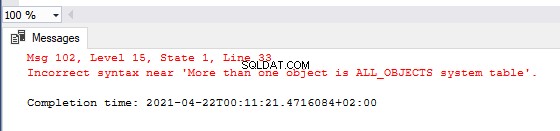
BEGIN TRY
IF ( SELECT COUNT(sys.all_objects) > 1 )
THROW ‘More than one object is ALL_OBJECTS system table’
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
Oder wir hätten gerne einen Katalog benutzerdefinierter Fehlermeldungen zur Kategorisierung und Konsistenz der Fehlerüberwachung und -berichterstattung. SQL Server ermöglicht es uns, den Code, den Schweregrad und den Zustand der Fehlermeldung vorzudefinieren.
Eine gespeicherte Prozedur namens „sys.sp_addmessage“ wird verwendet, um benutzerdefinierte Fehlermeldungen hinzuzufügen. Wir können damit die Fehlermeldung an mehreren Stellen aufrufen.
Wir können RAISERROR aufrufen und die Nachrichtennummer als Parameter senden, anstatt die gleichen Fehlerdetails an mehreren Stellen im Code fest zu codieren.
Durch Ausführen des unten ausgewählten Codes fügen wir den benutzerdefinierten Fehler in SQL Server hinzu, lösen ihn aus und verwenden dann sys.sp_dropmessage um die angegebene benutzerdefinierte Fehlermeldung zu löschen:
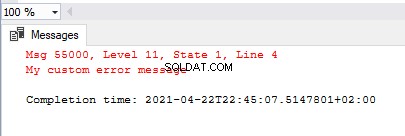
exec sys.sp_addmessage @msgnum=55000, @severity = 11,
@msgtext = 'My custom error message'
GO
RAISERROR(55000,11,1)
GO
exec sys.sp_dropmessage @msgnum=55000
GO
Außerdem können wir alle Nachrichten in SQL Server anzeigen, indem wir das folgende Abfrageformular ausführen. Unsere benutzerdefinierte Fehlermeldung ist als erstes Element in der Ergebnismenge sichtbar:
SELECT * FROM master.dbo.sysmessages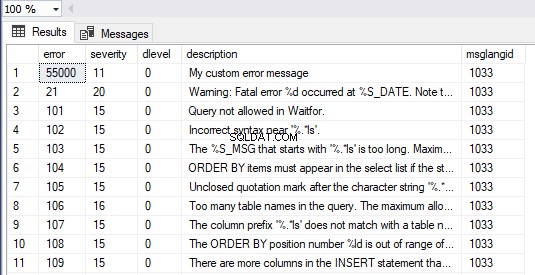
Erstellen Sie ein System zum Protokollieren von Fehlern
Es ist immer sinnvoll, Fehler für die spätere Fehlerbehebung und Verarbeitung zu protokollieren. Sie können diesen protokollierten Tabellen auch Trigger hinzufügen und sogar ein E-Mail-Konto einrichten und ein wenig kreativ werden, wenn es darum geht, Personen zu benachrichtigen, wenn ein Fehler auftritt.
Um Fehler zu protokollieren, erstellen wir eine Tabelle namens DBError_Log , die zum Speichern der Protokolldetaildaten verwendet werden kann:
CREATE TABLE DBError_Log
(
DBError_Log_ID INT IDENTITY(1, 1) PRIMARY KEY,
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME
);
Um den Protokollierungsmechanismus zu simulieren, erstellen wir den GenError gespeicherte Prozedur, die die Division durch Null generiert error und protokolliert den Fehler im DBError_Log Tabelle:
CREATE PROCEDURE dbo.GenError
AS
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT INTO dbo.DBError_Log
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE()
);
END CATCH
GO
EXEC dbo.GenError
SELECT * FROM dbo.DBError_Log
Das DBError_Log Tabelle enthält alle Informationen, die wir zum Debuggen des Fehlers benötigen. Außerdem enthält es zusätzliche Informationen zu dem Verfahren, das den Fehler verursacht hat. Obwohl dies wie ein triviales Beispiel erscheinen mag, können Sie diese Tabelle um zusätzliche Felder erweitern oder sie verwenden, um sie mit benutzerdefinierten Ausnahmen zu füllen.
Schlussfolgerung
Wenn wir Anwendungen warten und debuggen wollen, wollen wir zumindest melden, dass etwas schief gelaufen ist, und es auch unter der Haube protokollieren. Wenn wir eine Anwendung auf Produktionsebene haben, die von Millionen von Benutzern verwendet wird, ist eine konsistente und meldepflichtige Fehlerbehandlung der Schlüssel zum Debuggen von Problemen zur Laufzeit.
Obwohl wir den ursprünglichen Fehler im Datenbankfehlerprotokoll protokollieren könnten, sollten Benutzer eine freundlichere Nachricht sehen. Daher wäre es eine gute Idee, benutzerdefinierte Fehlermeldungen zu implementieren, die an aufrufende Anwendungen geworfen werden.
Unabhängig davon, welches Design Sie implementieren, müssen Sie Benutzer- und Systemausnahmen protokollieren und behandeln. Diese Aufgabe ist mit SQL Server nicht schwierig, aber Sie müssen sie von Anfang an planen.
Das Hinzufügen der Fehlerbehandlungsoperationen zu Datenbanken, die bereits in der Produktion ausgeführt werden, kann ernsthafte Codeumgestaltungen und schwer zu findende Leistungsprobleme nach sich ziehen.