Einführung
Eine Tabelle ist eine logische Struktur. Wenn Sie eine Tabelle erstellen, ist es Ihnen normalerweise egal, auf welchen Laufwerken sie sich auf der Speicherebene befindet. Wenn Sie jedoch ein Datenbankadministrator sind, kann dieses Wissen unerlässlich werden, wenn Sie bestimmte Datenbankteile auf einen anderen Speicher oder ein anderes Volume verschieben müssen. Dann möchten Sie vielleicht, dass sich bestimmte Tabellen auf einem bestimmten Volume oder Satz von Platten befinden.
Dateigruppen in SQL Server bieten diese Abstraktionsschicht, die es uns ermöglicht, den physischen Speicherort unserer logischen Strukturen – Tabellen, Indizes usw. – zu kontrollieren.
Dateigruppen
Eine Dateigruppe ist eine logische Struktur zum Gruppieren von Datendateien in SQL Server. Wenn wir eine Dateigruppe erstellen und sie mit einem Satz von Datendateien verknüpfen, befindet sich jedes logische Objekt, das in dieser Dateigruppe erstellt wurde, physisch in diesem Satz physischer Dateien.
Der Hauptzweck einer solchen physikalischen Dateigruppierung ist die Datenzuordnung und Datenplatzierung. Beispielsweise möchten wir, dass unsere Transaktionsdaten auf einem Satz schneller Festplatten gespeichert werden. Gleichzeitig benötigen wir die historischen Daten, die auf einem anderen Satz kostengünstigerer Festplatten gespeichert sind. In einem solchen Szenario würden wir den Tran erstellen Tabelle auf der TXN-Dateigruppe und dem TranHist Tabelle in einer anderen HIST-Dateigruppe. Weiter unten in diesem Artikel werden wir sehen, wie dies dazu führt, dass die Daten auf verschiedenen Festplatten gespeichert sind.
Dateigruppen erstellen
Die Syntax zum Erstellen von Dateigruppen ist in Listing 1 dargestellt . Hinweis :Der Datenbankkontext ist der Master Datenbank. Indem wir die Anweisungen ausgeben, ändern wir die DB2-Datenbank, indem wir ihr neue Dateigruppen hinzufügen. Im Wesentlichen sind diese Dateigruppen an dieser Stelle lediglich logische Konstrukte. Sie enthalten keine Daten.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Hinzufügen von Dateien zu Dateigruppen
Im nächsten Schritt fügen Sie jeder Dateigruppe eine Datei hinzu. Wir können mehr als eine Datei hinzufügen, aber wir halten es zu Demonstrationszwecken einfach. Beachten Sie, dass sich jede Datei auf einem anderen Laufwerk befindet und die Syntax es uns ermöglicht, die beabsichtigte Dateigruppe anzugeben.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Tabellen zu Dateigruppen erstellen
Hier stellen wir sicher, dass sich die Tabellen auf den gewünschten Datenträgern befinden. Die Syntax zum Erstellen von Tabellen ermöglicht es uns, die gewünschte Dateigruppe anzugeben.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Wenn wir einen Schritt zurücktreten, stellen wir fest, dass wir jetzt Folgendes erreicht haben:
- Zwei Dateigruppen erstellt.
- Festlegung der Datendateien (und Datenträger), die jeder Dateigruppe zugeordnet sind.
- Ermittelte die jeder Dateigruppe zugeordneten Tabellen.
Im Wesentlichen ist die Dateigruppe die Abstraktionsebene .
Überprüfen, auf welchen Dateigruppen unsere Tabellen sitzen
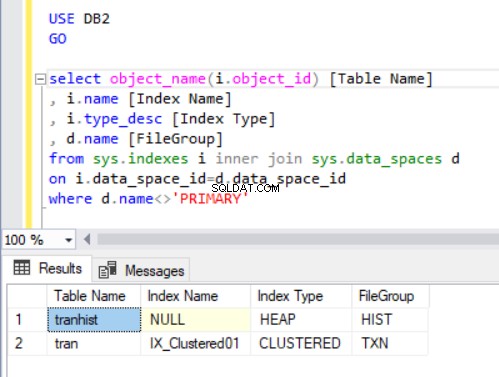
Um zu überprüfen, zu welcher Dateigruppe jede Tabelle gehört, führen wir den Code in Listing 4 aus. Wir verwenden zwei Hauptansichten des Systemkatalogs:sys.indexes und sys.data_spaces . Die sys.data_spaces Katalogansicht enthält Informationen über Dateigruppen und Partitionen sowie die wichtigsten logischen Strukturen, in denen Tabellen und Indizes gespeichert werden.
Hinweis:Wir haben sys.tables nicht verwendet . Der SQL Server ordnet Indizes in einer Tabelle eher Datenräumen als Tabellen zu, wie wir vielleicht intuitiv denken.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
Die Ausgabe der Abfrage in Listing 4 zeigt zwei Tabellen, die wir gerade erstellt haben. Beachten Sie, dass der tranhist Tabelle hat keinen Index. Dennoch erscheint es in der Ergebnismenge und wird als Heap identifiziert .
Ein Haufen ist eine Tabelle, die keinen Clustered-Index hat, der die physisch in einer Tabelle gespeicherten Auftragsdaten bestimmt. Es kann nur einen Clustered-Index in einer Tabelle geben.
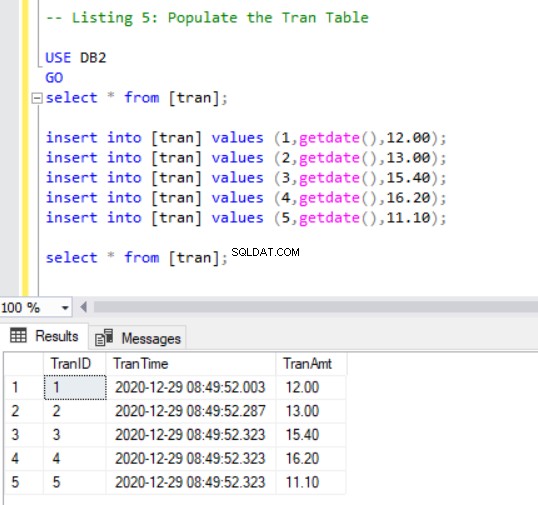
Auffüllen der Tran-Tabelle
Nun müssen wir dem tran einige Datensätze hinzufügen Tabelle mit dem folgenden Code:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Verschieben einer Tabelle in eine andere Dateigruppe
Um den Tran zu bewegen Tabelle in eine andere Dateigruppe, müssen wir nur den gruppierten Index neu erstellen und geben Sie die neue Dateigruppe an, während Sie diese Neuerstellung durchführen. Listing 5 zeigt diesen Ansatz.
Wir führen zwei Schritte aus:Löschen Sie zuerst den Index und erstellen Sie ihn dann neu. Zwischendurch überprüfen wir, ob die Daten und der Speicherort der beiden zuvor erstellten Tabellen intakt sind.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Beim Löschen des gruppierten Index aus dem tran Tabelle haben wir sie in einen Heap umgewandelt :
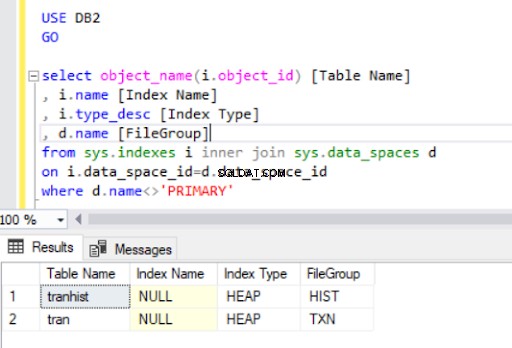
Wenn wir den Clustered-Index neu erstellen, wird er auch in der Ausgabe von Listing 4 angezeigt.
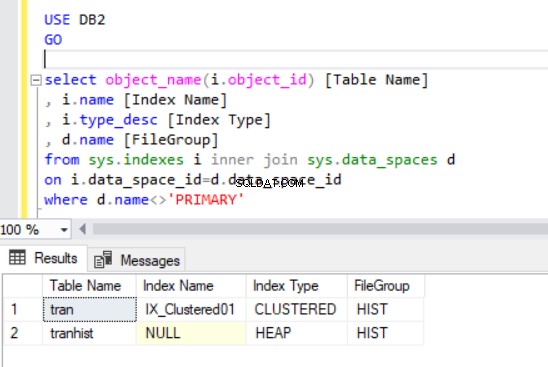
Jetzt haben wir den Tran Tabelle in der HIST-Dateigruppe.
Schlussfolgerung
Dieser Artikel demonstrierte die Beziehung zwischen Tabellen, Indizes, Dateien und Dateigruppen in Bezug auf unsere SQL Server-Datenspeicherung. Wir haben auch erklärt, wie Sie eine Tabelle von einer Dateigruppe in eine andere verschieben, indem Sie den gruppierten Index neu erstellen.
Diese Fähigkeit ist hilfreich, wenn Sie Daten auf einen neuen Speicher migrieren müssen (schnellere Festplatten oder langsamere Festplatten für die Archivierung). In fortgeschritteneren Szenarien können Sie Dateigruppen verwenden, um den Datenlebenszyklus zu verwalten, indem Sie Tabellenpartitionen implementieren.
Referenzen
- Datenbankdateien und Dateigruppen
- Austauschen von Tabellenpartitionen – eine exemplarische Vorgehensweise