Die Antwort wird natürlich "es kommt darauf an" lauten, aber basierend auf Tests zu diesem Zweck ...
Angenommen
- 1 Million Produkte
producthat einen gruppierten Index fürproduct_id- Die meisten (wenn nicht alle) Produkte haben entsprechende Informationen im
product_codeTabelle - Ideale Indizes vorhanden auf
product_codefür beide Abfragen.
Der PIVOT version benötigt idealerweise einen Index product_code(product_id, type) INCLUDE (code) wohingegen der JOIN Version benötigt idealerweise einen Index product_code(type,product_id) INCLUDE (code)
Wenn diese vorhanden sind, geben Sie die folgenden Pläne an
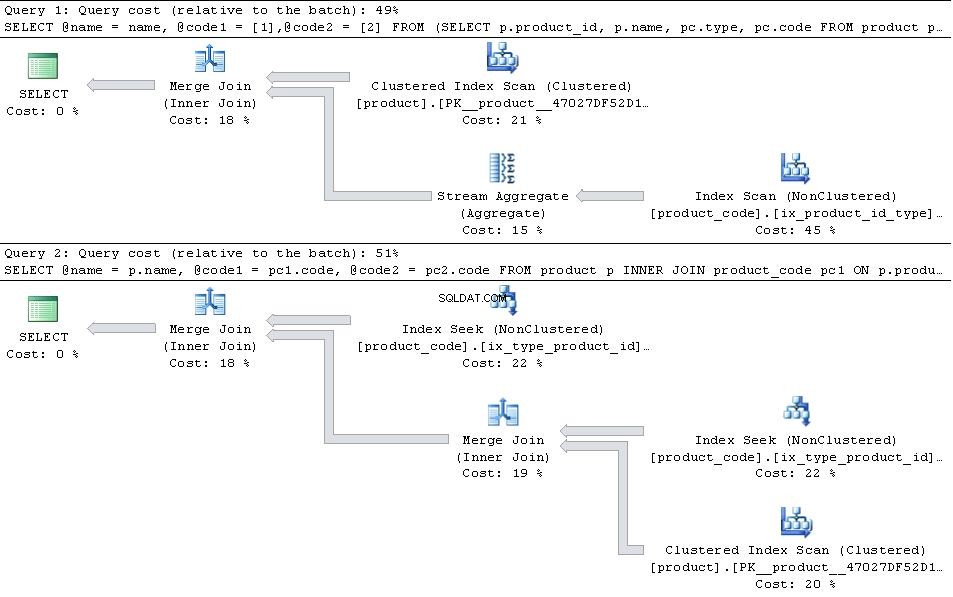
dann JOIN Version ist effizienter.
Für den Fall, dass type 1 und type 2 sind die einzigen types in der Tabelle dann den PIVOT Version hat einen leichten Vorteil in Bezug auf die Anzahl der Lesevorgänge, da sie nicht in product_code suchen muss zweimal, aber das wird durch den zusätzlichen Overhead des Stream-Aggregat-Operators mehr als aufgewogen
PIVOT
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
MITGLIED
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Wenn es zusätzliche type gibt andere Datensätze als 1 und 2 das JOIN -Version erhöht ihren Vorteil, da sie nur Joins in den relevanten Abschnitten von type,product_id zusammenführt Index, wohingegen der PIVOT plan verwendet product_id, type und müsste daher über den zusätzlichen type scannen Zeilen, die mit 1 vermischt sind und 2 Zeilen.