Aus dem Kopf heraus habe ich eine 50 %-Lösung für Sie.
Das Problem
SSIS wirklich kümmert sich um Metadaten, sodass Variationen darin tendenziell zu Ausnahmen führen. DTS war in diesem Sinne weitaus nachsichtiger. Dieser starke Bedarf an konsistenten Metadaten macht die Verwendung der Flat File Source mühsam.
Abfragebasierte Lösung
Wenn das Problem die Komponente ist, verwenden wir sie nicht. Was mir an diesem Ansatz gefällt, ist, dass es konzeptionell dasselbe ist wie das Abfragen einer Tabelle – die Reihenfolge der Spalten spielt keine Rolle, noch spielt das Vorhandensein zusätzlicher Spalten eine Rolle.
Variablen
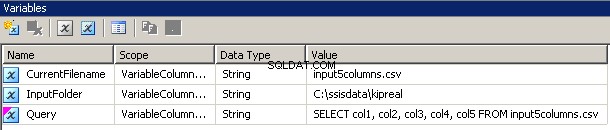
Ich habe 3 Variablen erstellt, alle vom Typ String:CurrentFileName, InputFolder und Query.
- InputFolder ist fest mit dem Quellordner verbunden. In meinem Beispiel ist es
C:\ssisdata\Kipreal - CurrentFileName ist der Name einer Datei. Während der Entwurfszeit war es
input5columns.csvaber das wird sich zur Laufzeit ändern. - Abfrage ist ein Ausdruck
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Verbindungsmanager
Richten Sie mit dem JET OLEDB-Treiber eine Verbindung zur Eingabedatei ein. Nachdem ich es wie im verlinkten Artikel beschrieben erstellt habe, habe ich es in FileOLEDB umbenannt und einen Ausdruck für den ConnectionManager von "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Kontrollfluss
Meine Ablaufsteuerung sieht aus wie eine Datenflussaufgabe, die in einem Foreach-Dateienumerator
verschachtelt ist
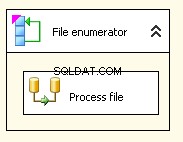
Foreach-Datei-Enumerator
Mein Foreach File-Enumerator ist so konfiguriert, dass er mit Dateien arbeitet. Ich habe einen Ausdruck in das Verzeichnis für @[User::InputFolder] eingefügt Beachten Sie, dass an diesem Punkt, wenn der Wert dieses Ordners geändert werden muss, er sowohl im Verbindungsmanager als auch im Dateienumerator korrekt aktualisiert wird. Wählen Sie bei „Dateinamen abrufen“ anstelle des standardmäßigen „Vollqualifiziert“ „Name und Erweiterung“
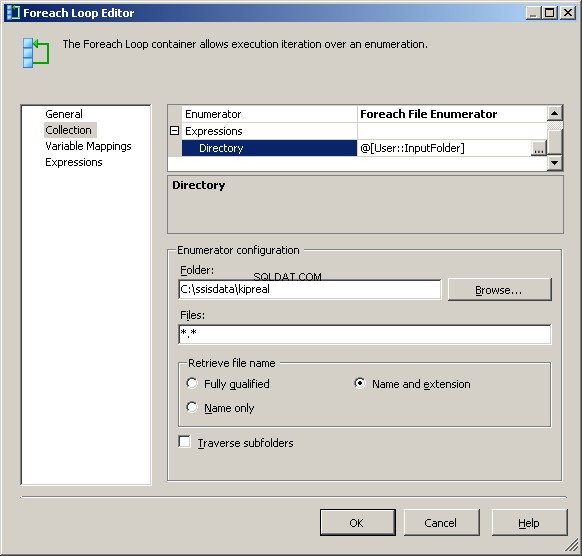
Weisen Sie auf der Registerkarte Variablenzuordnungen den Wert unserem @[User::CurrentFileName] zu Variable
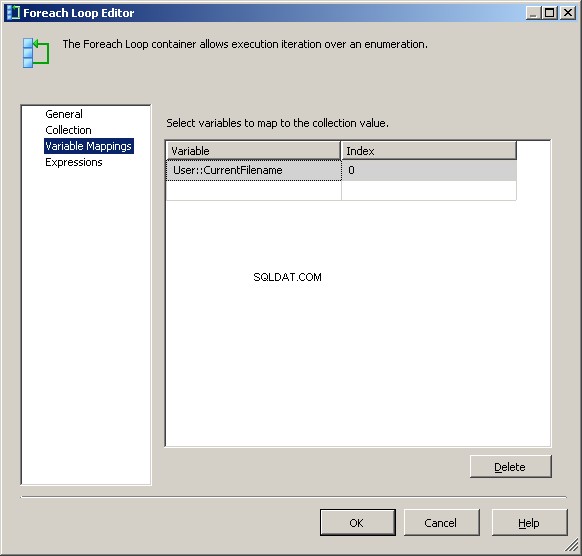
An diesem Punkt ändert jede Iteration der Schleife den Wert von @[User::Query um den aktuellen Dateinamen widerzuspiegeln.
Datenfluss
Dies ist eigentlich das einfachste Stück. Verwenden Sie eine OLE DB-Quelle und verbinden Sie sie wie angegeben.
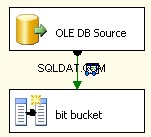
Verwenden Sie den FileOLEDB-Verbindungsmanager und ändern Sie den Datenzugriffsmodus in „SQL-Befehl aus Variable“. Verwenden Sie den @[User::Query] Variable darin, klicken Sie auf OK und Sie können mit der Arbeit beginnen. 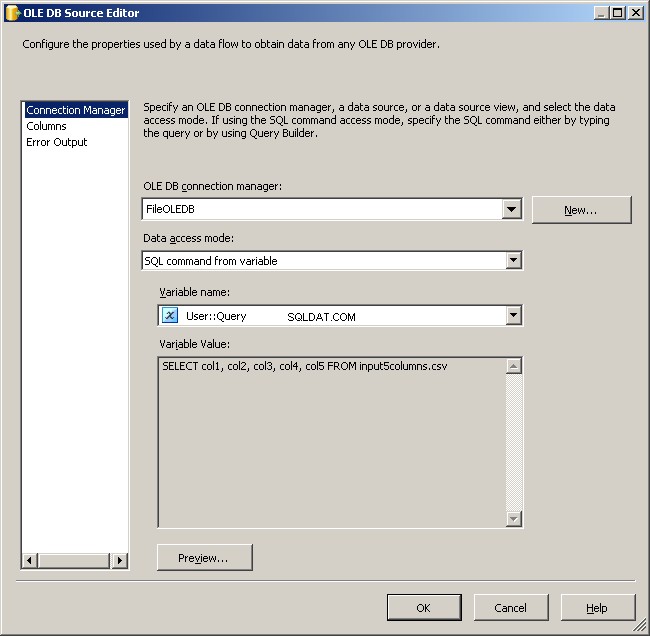
Beispieldaten
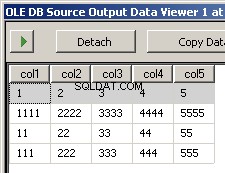
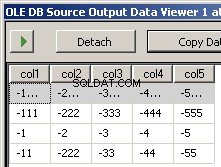
Ich habe zwei Beispieldateien input5columns.csv und input7columns.csv erstellt. Alle Spalten von 5 befinden sich in 7, aber 7 hat sie in einer anderen Reihenfolge (col2 ist die Ordnungsposition 2 und 6). Ich habe alle Werte in 7 negiert, um deutlich zu machen, welche Datei bearbeitet wird.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
und
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
Das Ausführen des Pakets führt zu diesen beiden Screenshots
Was fehlt
Ich kenne keine Möglichkeit, dem abfragebasierten Ansatz mitzuteilen, dass es in Ordnung ist, wenn eine Spalte nicht vorhanden ist. Wenn es einen eindeutigen Schlüssel gibt, könnten Sie Ihre Abfrage wahrscheinlich so definieren, dass sie nur die Spalten enthält, die müssen Seien Sie dort und führen Sie dann Suchen in der Datei durch, um zu versuchen, die Spalten zu erhalten, die sollten um dort zu sein und die Suche nicht fehlschlagen zu lassen, wenn die Spalte nicht existiert. Ziemlich klobig.