Was führt dazu, dass die Cross-Apply-Abfrage bei diesem einfachen XML-Dokument so schlecht abschneidet und exponentiell langsamer wird, wenn der Datensatz wächst?
Es ist die Verwendung der übergeordneten Achse, um die Attribut-ID vom Elementknoten zu erhalten.
Dieser Teil des Abfrageplans ist problematisch.

Beachten Sie die 423 Zeilen, die aus der unteren Tabellenwertfunktion kommen.
Wenn Sie nur einen weiteren Elementknoten mit drei Feldknoten hinzufügen, erhalten Sie dies.
732 Zeilen zurückgegeben.
Was wäre, wenn wir die Knoten von der ersten Abfrage auf insgesamt 6 Elementknoten verdoppeln?
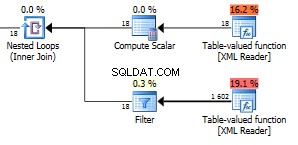
Wir haben satte 1602 Zeilen zurückgegeben.
Die Zahl 18 in der obersten Funktion sind alle Feldknoten in Ihrem XML. Wir haben hier 6 Artikel mit drei Feldern in jedem Artikel. Diese 18 Knoten werden in einem Join mit verschachtelten Schleifen gegen die andere Funktion verwendet, sodass 18 Ausführungen, die 1602 Zeilen zurückgeben, ergeben, dass 89 Zeilen pro Iteration zurückgegeben werden. Das ist zufällig die genaue Anzahl der Knoten im gesamten XML. Nun, es ist tatsächlich einer mehr als alle sichtbaren Knoten. Ich weiß nicht warum. Sie können diese Abfrage verwenden, um die Gesamtzahl der Knoten in Ihrem XML zu überprüfen.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Also der Algorithmus, der von SQL Server verwendet wird, um den Wert zu erhalten, wenn Sie die übergeordnete Achse .. verwenden in einer Wertefunktion ist, dass sie zuerst alle Knoten findet, auf denen Sie schreddern, im letzten Fall 18. Für jeden dieser Knoten wird das gesamte XML-Dokument geschreddert und zurückgegeben und der Filteroperator für den tatsächlich gewünschten Knoten überprüft. Dort haben Sie Ihr exponentielles Wachstum. Anstatt die übergeordnete Achse zu verwenden, sollten Sie ein zusätzliches Kreuz anwenden. Zuerst auf dem Gegenstand und dann auf dem Feld zerkleinern.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Ich habe auch geändert, wie Sie auf den Textwert des Felds zugreifen. Mit . bewirkt, dass SQL Server nach untergeordneten Knoten in field sucht und verketten Sie diese Werte im Ergebnis. Sie haben keine untergeordneten Werte, daher ist das Ergebnis dasselbe, aber es ist eine gute Sache, diesen Teil im Abfrageplan (den UDX-Operator) zu vermeiden.
Der Abfrageplan hat kein Problem mit der übergeordneten Achse, wenn Sie einen XML-Index verwenden, aber Sie profitieren dennoch davon, die Art und Weise zu ändern, wie Sie den Feldwert abrufen.