Es gibt - ab v2016 - eine Lösung über FROM OPENJSON() :
DECLARE @str VARCHAR(100) = 'val1,val2,val3';
SELECT *
FROM OPENJSON('["' + REPLACE(@str,',','","') + '"]');
Das Ergebnis
key value type
0 val1 1
1 val2 1
2 val3 1
Die Dokumentation sagt deutlich:
Wenn OPENJSON ein JSON-Array analysiert, gibt die Funktion die Indizes der Elemente im JSON-Text als Schlüssel zurück.
Für Ihren Fall war dies:
SELECT 'z_y_x' AS splitIt
INTO #split UNION
SELECT 'a_b_c'
DECLARE @delimiter CHAR(1)='_';
SELECT *
FROM #split
CROSS APPLY OPENJSON('["' + REPLACE(splitIt,@delimiter,'","') + '"]') s
WHERE s.[key]=1; --zero based
Hoffen wir, dass zukünftige Versionen von STRING_SPLIT() enthält diese Informationen
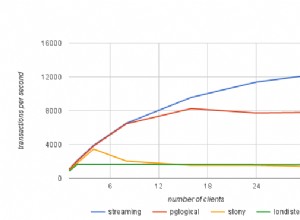
UPDATE Leistungstests, Vergleich mit populärem Jeff-Moden-Splitter
Probieren Sie es aus:
USE master;
GO
CREATE DATABASE dbTest;
GO
USE dbTest;
GO
--Jeff Moden's splitter
CREATE FUNCTION [dbo].[DelimitedSplit8K](@pString VARCHAR(8000), @pDelimiter CHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), --10E+1 or 10 rows
E2(N) AS (SELECT 1 FROM E1 a, E1 b), --10E+2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), --10E+4 or 10,000 rows max
cteTally(N) AS (
SELECT TOP (ISNULL(DATALENGTH(@pString),0)) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
),
cteStart(N1) AS (
SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(
SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,8000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l
;
GO
--Avoid first call bias
SELECT * FROM dbo.DelimitedSplit8K('a,b,c',',');
GO
--Table to keep the results
CREATE TABLE Results(ID INT IDENTITY,ResultSource VARCHAR(100),durationMS INT, RowsCount INT);
GO
--Table with strings to split
CREATE TABLE dbo.DelimitedItems(ID INT IDENTITY,DelimitedNString nvarchar(4000),DelimitedString varchar(8000));
GO
--Erhalte Zeilen mit zufällig gemischten Zeichenfolgen von 100 Elementen
--Versuche mit der Anzahl der Zeilen (Zählung hinter GO) und der Zählung mit TOP
INSERT INTO DelimitedItems(DelimitedNString)
SELECT STUFF((
SELECT TOP 100 ','+REPLACE(v.[name],',',';')
FROM master..spt_values v
WHERE LEN(v.[name])>0
ORDER BY NewID()
FOR XML PATH('')),1,1,'')
--Keep it twice in varchar and nvarchar
UPDATE DelimitedItems SET DelimitedString=DelimitedNString;
GO 500 --create 500 differently mixed rows
--Die Tests
DECLARE @d DATETIME2;
SET @d = SYSUTCDATETIME();
SELECT DI.ID, DS.Item, DS.ItemNumber
INTO #TEMP
FROM dbo.DelimitedItems DI
CROSS APPLY dbo.DelimitedSplit8K(DI.DelimitedNString,',') DS;
INSERT INTO Results(ResultSource,RowsCount,durationMS)
SELECT 'delimited8K with NVARCHAR(4000)'
,(SELECT COUNT(*) FROM #TEMP) AS RowCountInTemp
,DATEDIFF(MILLISECOND,@d,SYSUTCDATETIME()) AS Duration_NV_ms_delimitedSplit8K
SET @d = SYSUTCDATETIME();
SELECT DI.ID, DS.Item, DS.ItemNumber
INTO #TEMP2
FROM dbo.DelimitedItems DI
CROSS APPLY dbo.DelimitedSplit8K(DI.DelimitedString,',') DS;
INSERT INTO Results(ResultSource,RowsCount,durationMS)
SELECT 'delimited8K with VARCHAR(8000)'
,(SELECT COUNT(*) FROM #TEMP2) AS RowCountInTemp
,DATEDIFF(MILLISECOND,@d,SYSUTCDATETIME()) AS Duration_V_ms_delimitedSplit8K
SET @d = SYSUTCDATETIME();
SELECT DI.ID, OJ.[Value] AS Item, OJ.[Key] AS ItemNumber
INTO #TEMP3
FROM dbo.DelimitedItems DI
CROSS APPLY OPENJSON('["' + REPLACE(DI.DelimitedNString,',','","') + '"]') OJ;
INSERT INTO Results(ResultSource,RowsCount,durationMS)
SELECT 'OPENJSON with NVARCHAR(4000)'
,(SELECT COUNT(*) FROM #TEMP3) AS RowCountInTemp
,DATEDIFF(MILLISECOND,@d,SYSUTCDATETIME()) AS Duration_NV_ms_OPENJSON
SET @d = SYSUTCDATETIME();
SELECT DI.ID, OJ.[Value] AS Item, OJ.[Key] AS ItemNumber
INTO #TEMP4
FROM dbo.DelimitedItems DI
CROSS APPLY OPENJSON('["' + REPLACE(DI.DelimitedString,',','","') + '"]') OJ;
INSERT INTO Results(ResultSource,RowsCount,durationMS)
SELECT 'OPENJSON with VARCHAR(8000)'
,(SELECT COUNT(*) FROM #TEMP4) AS RowCountInTemp
,DATEDIFF(MILLISECOND,@d,SYSUTCDATETIME()) AS Duration_V_ms_OPENJSON
GO
SELECT * FROM Results;
GO
--Aufräumen
DROP TABLE #TEMP;
DROP TABLE #TEMP2;
DROP TABLE #TEMP3;
DROP TABLE #TEMP4;
USE master;
GO
DROP DATABASE dbTest;
Ergebnisse:
200 Elemente in 500 Zeilen
1220 delimited8K with NVARCHAR(4000)
274 delimited8K with VARCHAR(8000)
417 OPENJSON with NVARCHAR(4000)
443 OPENJSON with VARCHAR(8000)
100 Artikel in 500 Zeilen
421 delimited8K with NVARCHAR(4000)
140 delimited8K with VARCHAR(8000)
213 OPENJSON with NVARCHAR(4000)
212 OPENJSON with VARCHAR(8000)
100 Artikel in 5 Reihen
10 delimited8K with NVARCHAR(4000)
5 delimited8K with VARCHAR(8000)
3 OPENJSON with NVARCHAR(4000)
4 OPENJSON with VARCHAR(8000)
5 Elemente in 500 Zeilen
32 delimited8K with NVARCHAR(4000)
30 delimited8K with VARCHAR(8000)
28 OPENJSON with NVARCHAR(4000)
24 OPENJSON with VARCHAR(8000)
--unbegrenzte Länge (nur mit OPENJSON möglich )--Ohne eine TOP-Klausel beim Füllen
--ergibt ungefähr 500 Elemente in 500 Zeilen
1329 OPENJSON with NVARCHAR(4000)
1117 OPENJSON with VARCHAR(8000)
Tatsache:
- Die beliebte Splitterfunktion mag
NVARCHARnicht - Die Funktion ist auf Strings mit einem Volumen von 8 KB beschränkt
- Nur bei vielen Elementen und vielen Zeilen in
VARCHARder Fall lässt die Splitterfunktion voraus. - In allen anderen Fällen
OPENJSONscheint mehr oder weniger schneller zu sein... OPENJSONkann mit (fast) unbegrenzten Zählimpulsen umgehenOPENJSONAnforderungen für v2016- Alle warten auf
STRING_SPLITmit der Position
UPDATE STRING_SPLIT zum Test hinzugefügt
In der Zwischenzeit führe ich den Test mit zwei weiteren Testabschnitten mit STRING_SPLIT() erneut aus . Als Position musste ich einen fest codierten Wert zurückgeben, da diese Funktion nicht den Index des Teils zurückgibt.
In allen getesteten Fällen OPENJSON war knapp bei STRING_SPLIT und oft schneller:
5 Elemente in 1000 Zeilen
250 delimited8K with NVARCHAR(4000)
124 delimited8K with VARCHAR(8000) --this function is best with many rows in VARCHAR
203 OPENJSON with NVARCHAR(4000)
204 OPENJSON with VARCHAR(8000)
235 STRING_SPLIT with NVARCHAR(4000)
234 STRING_SPLIT with VARCHAR(8000)
200 Artikel in 30 Reihen
140 delimited8K with NVARCHAR(4000)
31 delimited8K with VARCHAR(8000)
47 OPENJSON with NVARCHAR(4000)
31 OPENJSON with VARCHAR(8000)
47 STRING_SPLIT with NVARCHAR(4000)
31 STRING_SPLIT with VARCHAR(8000)
100 Artikel in 10.000 Zeilen
8145 delimited8K with NVARCHAR(4000)
2806 delimited8K with VARCHAR(8000) --fast with many rows!
5112 OPENJSON with NVARCHAR(4000)
4501 OPENJSON with VARCHAR(8000)
5028 STRING_SPLIT with NVARCHAR(4000)
5126 STRING_SPLIT with VARCHAR(8000)