SQL Server gibt es seit über 30 Jahren und ich arbeite fast genauso lange mit SQL Server. Kalen behandelt Scans in Teil Eins von SQL Server Internals:Problematic Operators.
Ich habe im Laufe der Jahre (und Jahrzehnte!) und Versionen dieses unglaublichen Produkts viele Veränderungen gesehen. In diesen Beiträgen werde ich mit Ihnen teilen, wie ich einige der Funktionen oder Aspekte von SQL Server betrachte, manchmal zusammen mit einem kleinen historischen Blickwinkel.
Das Optimieren Ihrer SQL Server-Abfragen ist eines der besten Dinge, die Sie für eine bessere Leistung und Optimierung der SQL Server-Diagnose tun können. Aber Tuning ist ein Riesenthema! Um genau zu wissen, wie Sie optimal optimieren können, ist nicht nur eine gründliche Kenntnis Ihrer Daten und Ihrer Arbeitslast erforderlich, sondern auch das Wissen darüber, wie SQL Server tatsächlich seine Planausführungsentscheidungen trifft. Was können Sie also tun, wenn Sie kein Experte für SQL Server Internals sind? Eine Sache, die Sie tun können, ist, sich auf Menschen zu verlassen, die Experten sind, sowie auf Tools, die von Experten geschrieben wurden. Tools wie das Quest Spotlight Cloud Tuning Pack können Ihnen einige großartige Vorschläge für den Einstieg in den Weg zu einer besseren Abfrageleistung geben. Natürlich kennt kein externes Tool Ihre Daten und alle Details all Ihrer Workloads, daher wird immer empfohlen, jeden Vorschlag, den Sie umsetzen möchten, gründlich zu testen.
In diesen Beiträgen zu problematischen Operatoren gehe ich davon aus, dass Sie über grundlegende Kenntnisse der Indexstrukturen von SQL Server verfügen. Hier sind einige hilfreiche Informationen:
- Eine Tabelle ohne Clustered-Index wird Heap genannt und hat keine Ordnung. Es gibt keine erste Reihe oder letzte Reihe. Ein Heap ist nur eine Ansammlung von Zeilen in keiner bestimmten Reihenfolge.
- Die Blattebene eines Clustered-Index ist die Tabelle selbst. (Es ist keine Kopie der Tabelle, es IST die Tabelle.) Die Zeilen des Index sind logisch nach der Spalte geordnet, die als Clustered-Index-Schlüssel definiert wurde.
- Die Blattebene eines Nonclustered-Index enthält eine Indexzeile für jede Zeile in der Tabelle. Die Zeilen enthalten die nicht gruppierten Schlüsselspalten und sind logisch in der Reihenfolge angeordnet, in der die Schlüssel angegeben sind. Zusätzlich zu den Schlüsselspalten enthalten die Nonclustered-Indexzeilen ein „Lesezeichen“, das auf die referenzierte Zeile in der Tabelle zeigt. Das Lesezeichen kann in einer von zwei Formen vorliegen:
- Wenn die Tabelle einen Clustered-Index hat, ist das Lesezeichen der Clustered-Index-Schlüssel. (Wenn der Clustered-Index-Schlüssel Teil des Nonclustered-Index-Schlüssels ist, wird er nicht dupliziert.)
- Wenn die Tabelle ein Heap ist, ist das Lesezeichen eine Zeilen-ID oder RID, die den physischen Speicherort der Zeile angibt. Der Speicherort wird normalerweise als FileNum:PageNum:RowNum angegeben .
Die eigenen Tools von SQL Server bieten mehrere Möglichkeiten zum Anzeigen des Abfrageausführungsplans, den der Optimierer für eine bestimmte Abfrage verwendet hat. Mit dem Quest Spotlight Tuning Pack erhalten Sie noch mehr Informationen über Ihre Pläne.
Der folgende Code erstellt Kopien von zwei Tabellen in AdventureWorks Datenbank (ich verwende AdventureWorks2016 , aber Sie könnten eine andere Version verwenden).
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS SalesHeader;
GO
SELECT *
INTO SalesHeader
FROM Sales.SalesOrderHeader;
GO
DROP TABLE IF EXISTS SalesDetail;
GO
SELECT * INTO SalesDetail
FROM Sales.SalesOrderDetail;
GO
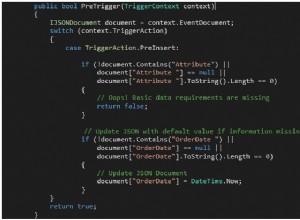
Führen Sie nun eine Abfrage aus, die die beiden Tabellen miteinander verbindet, nachdem Sie „Aktuellen Ausführungsplan einbeziehen“ aktiviert haben
SELECT h.SalesOrderID, OrderDate, ProductID, UnitPrice, OrderQty
FROM SalesHeader h JOIN SalesDetail d
ON h.SalesOrderID = d.SalesOrderID
WHERE SalesOrderDetailID < 100;
GO
Das Quest Spotlight Tuning Pack meldet ein Problem mit der Abfrage, sodass Sie auf „Analyse anzeigen“ klicken und die Option „Ausführungsplan“ auswählen können. Sie sollten Folgendes sehen:

Table Scans verstehen
Zuerst möchte ich auf die Beine gehen und sagen, dass es keinen Planbetreiber gibt, der immer schlecht ist! Warum würde der Optimierer es Ihrem Abfrageplan hinzufügen, wenn es schlecht wäre? Es könnte darauf hindeuten, dass es Raum für Verbesserungen in Ihren Daten oder Indexstrukturen gibt, aber an sich ist es nicht schlecht.
Im obigen Beispiel scheint das Tuning Pack die Tabellenscans hervorzuheben, was darauf hinweist, dass sie möglicherweise problematisch sind. Aber es stimmt nicht immer, dass Tabellenscans problematisch sind. Eine viel schlimmere Situation wäre es, eine Nonclustered-Index-Suche für eine Abfrage zu verwenden, die auf jede Zeile in der Tabelle zugreift. Für diese spezielle Abfrage würde ich zustimmen, dass der Scan möglicherweise keine gute Sache ist, da wir nur an einigen Zeilen in SalesDetail interessiert sind Tabelle (99 von 121.317 Zeilen oder weniger als ein Zehntelprozent.)
Wir könnten uns also die Vorschläge im Analysebereich zum Erstellen von Indizes ansehen. Der Vorschlag für das SalesDetail Tabelle soll einen Nonclustered-Index auf der SalesOrderID erstellen Spalte (die Spalte in der JOIN-Klausel) und INCLUDE jede andere Spalte in der Tabelle, die von der Abfrage zurückgegeben wird. Der Vorschlag für den SalesHeader Tabelle ist ein nicht gruppierter Index auf der SalesOrderDetailId -Spalte, die die Spalte in der WHERE-Klausel ist, und INCLUDE das OrderDate -Spalte, die die einzige andere Spalte ist, die von dieser Tabelle zurückgegeben wird.
Was wäre, wenn unsere Abfrage etwas anders wäre? Was wäre, wenn ich diese Abfrage mit SELECT * anstelle einer bestimmten Spaltenliste ausgeführt hätte. Wenn Sie es versuchen und sich die Empfehlungen ansehen, schlägt es vor, das INCLUDE für jede Spalte in der Tabelle außer der einzelnen Schlüsselspalte zu verwenden. Obwohl ein solcher Index dazu führen kann, dass diese bestimmte Abfrage etwas schneller ausgeführt wird, könnte er letztendlich andere Abfragen verlangsamen, insbesondere Ihre UPDATE-Abfragen. Dieser Index ist im Grunde nur eine Kopie der Tabelle, da die Blattebene des Index jede einzelne Spalte in der Tabelle enthält. Wenn Sie Empfehlungen wie diese sehen, die einen Index vorschlagen, der alle Spalten in der Tabelle enthält, empfehle ich auf jeden Fall, etwas zurückzutreten und ihn nicht blind zu erstellen.
Die Abfrageoptimierung für Ihre SQL Server-Diagnose umfasst nicht nur die Verwaltung von Indizes, sondern auch die Verwaltung der Abfragen selbst. Für diese spezielle Abfrage ist es möglicherweise besser, die Abfrage so umzuschreiben, dass sie NICHT SELECT * verwendet, um jede Zeile in der Tabelle zurückzugeben. Es könnte ausreichen, nur eine kleine Teilmenge der Spalten zurückzugeben, und dann würde ein viel schmalerer Index ausreichen, wie im ersten Beispiel.
Wäre einer dieser Indizes tatsächlich ein guter Index zum Erstellen? Der schmalere Index ist insgesamt kleiner und wird weniger von Aktualisierungen der Daten beeinflusst. Ein Index für alle Spalten ist wie eine zweite Kopie der Tabelle, sortiert in einer anderen Reihenfolge als die Tabelle selbst. Es gibt Situationen, in denen es nützlich sein kann, eine „zweite Kopie“ der Tabelle in einer anderen Reihenfolge zu haben, aber es wird viel Overhead für Datenänderungsvorgänge geben. Gewissheit gibt es nur, wenn die Empfehlungen auf einem Testsystem mit repräsentativer Auslastung ausprobiert werden. Nur Sie kennen Ihre Daten und Ihre Abfragen, also probieren Sie es aus!
Index-Scans verstehen
Wie ich oben erwähnt habe, sind Tabellenscans nicht immer eine schlechte Sache. Aber was ist mit Index-Scans? Da eine Clustered-Index-Blattebene die Tabelle selbst ist, ist ein Clustered-Index-Scan dasselbe wie ein Tabellen-Scan! Wenn ein Tabellenscan schlecht ist, ist ein Clustered-Index-Scan genauso schlecht. Aber es ist nicht immer schlecht. Auch hier müssen Sie es auf Ihrem System testen.
Die Empfehlungen der SQL Server Engine, die das Quest Spotlight Tuning Pack zeigt, schlagen niemals einen gruppierten Index vor. Es kann ein Nonclustered vorschlagen, das jede Spalte in der Tabelle enthält (wie bereits erwähnt), was nur ein Duplikat der Tabelle ist. Das Herausfinden der besten Spalte oder Spalten für Ihren gruppierten Index ist ein großes Thema für sich, daher werde ich hier nicht darauf eingehen.
Was ist eine Suche? Ein Suchvorgang in einem Plan bedeutet, dass SQL Server die geordneten Daten in der Indexstruktur verwendet, um eine Zeile, eine Reihe von Zeilen oder den Start- und/oder Endpunkt in einem Bereich von Zeilen zu finden. Im Allgemeinen ist die Verwendung eines Nonclustered-Index-Suchvorgangs eine vollkommen vernünftige Operation, wenn Sie nur einen sehr kleinen Prozentsatz von Zeilen aus einer Tabelle zurückgeben. Aber eine Suche ist keine gute Wahl für eine Abfrage, die VIELE Zeilen aus einer Tabelle zurückgibt. Wie viele sind LOTS? Es gibt keine einfache Antwort, aber wenn Ihre Abfrage mehr als ein paar Prozent der Zeilen zurückgibt, sollten Sie sicherstellen, dass Sie die Indexvorschläge gründlich testen. Manchmal ist ein Tabellenscan oder Clustered-Index-Scan besser als eine Indexsuche. (Ein solches Beispiel finden Sie in meinem Blogbeitrag hier).
Tools wie das Quest Spotlight Tuning Pack kann Ihnen großartige Vorschläge für den Einstieg in Ihre Optimierungsreise mit der SQL Server-Diagnose geben, aber je mehr Sie über die Funktionsweise von SQL Server-Indizes und dem SQL Server-Optimierer wissen, desto besser können Sie diese Vorschläge für Ihre Abfragen und Ihre auswerten Daten und eventuell sogar eigene Vorschläge einbringen.
In den folgenden Beiträgen dieser Serie werde ich Sie über andere problematische Operatoren informieren, die möglicherweise in Ihren Abfrageplänen auftauchen, also schauen Sie bald wieder vorbei!