Dies ist Teil einer Reihe problematischer Operatoren zu SQL Server Internals. Lesen Sie unbedingt Kalens ersten Post und zweiten Post zu diesem Thema.
SQL Server gibt es seit über 30 Jahren und ich arbeite fast genauso lange mit SQL Server. Ich habe im Laufe der Jahre (und Jahrzehnte!) und Versionen dieses unglaublichen Produkts viele Veränderungen gesehen. In diesen Beiträgen werde ich mit Ihnen teilen, wie ich einige der Funktionen oder Aspekte von SQL Server betrachte, manchmal zusammen mit einem kleinen historischen Blickwinkel.
Letztes Mal habe ich über Hashing in einem SQL Server-Abfrageplan als potenziell problematischen Operator in der SQL Server-Diagnose gesprochen. Hashing wird häufig für Joins und Aggregation verwendet, wenn kein nützlicher Index vorhanden ist. Und wie bei Scans (über die ich im ersten Beitrag dieser Serie gesprochen habe) gibt es Zeiten, in denen Hashing tatsächlich eine bessere Wahl ist als die Alternativen. Eine der Alternativen für Hash-Joins ist LOOP JOIN, von dem ich Ihnen auch letztes Mal erzählt habe.
In diesem Beitrag erzähle ich Ihnen von einer anderen Alternative für das Hashing. Die meisten Alternativen zum Hashing erfordern, dass die Daten sortiert werden, sodass entweder der Plan einen SORT-Operator enthalten muss oder die erforderlichen Daten aufgrund vorhandener Indizes bereits sortiert sein müssen.
Verschiedene Arten von Joins für die SQL Server-Diagnose
Bei JOIN-Operationen ist der häufigste und nützlichste JOIN-Typ ein LOOP JOIN. Den Algorithmus für einen LOOP JOIN habe ich im vorigen Post beschrieben. Obwohl die Daten selbst für einen LOOP JOIN nicht sortiert werden müssen, macht das Vorhandensein eines Indexes in der inneren Tabelle den Join viel effizienter, und wie Sie wissen sollten, impliziert das Vorhandensein eines Indexes eine gewisse Sortierung. Während ein Clustered-Index die Daten selbst sortiert, sortiert ein Nonclustered-Index die Indexschlüsselspalten. Tatsächlich entscheidet sich der Optimierer von SQL Server ohne den Index in den meisten Fällen für die Verwendung des HASH JOIN-Algorithmus. Wir haben das letztes Mal im Beispiel gesehen, dass ohne Indizes HASH JOIN gewählt wurde und mit Indizes ein LOOP JOIN.
Der dritte Join-Typ ist ein MERGE JOIN. Dieser Algorithmus arbeitet mit zwei bereits sortierten Datensätzen. Wenn wir versuchen, zwei bereits sortierte Datensätze zu kombinieren (oder VERBINDEN), ist nur ein einziger Durchlauf durch jeden Satz erforderlich, um die übereinstimmenden Zeilen zu finden. Hier ist der Pseudocode für den Merge-Join-Algorithmus:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Obwohl MERGE JOIN ein sehr effizienter Algorithmus ist, müssen beide Eingabedatensätze nach dem Join-Schlüssel sortiert werden, was normalerweise bedeutet, dass ein gruppierter Index für den Join-Schlüssel für beide Tabellen vorhanden ist. Da Sie nur einen geclusterten Index pro Tabelle erhalten, ist die Auswahl der geclusterten Schlüsselspalte, nur um MERGE JOINS zu ermöglichen, möglicherweise nicht die beste Wahl für den Clustering-Schlüssel.
Daher empfehle ich normalerweise nicht, dass Sie versuchen, Indizes nur zum Zwecke von MERGE JOINS zu erstellen, aber wenn Sie am Ende einen MERGE JOIN aufgrund bereits vorhandener Indizes erhalten, ist dies normalerweise eine gute Sache. MERGE JOIN erfordert nicht nur, dass beide Eingabedatensätze sortiert werden, sondern auch, dass mindestens einer der Datensätze eindeutige Werte für den Join-Schlüssel hat.
Schauen wir uns ein Beispiel an. Zuerst erstellen wir die Header neu und Details Tabellen:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Sehen Sie sich als Nächstes den Plan für einen Join zwischen diesen Tabellen an:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Hier ist der Plan:

Beachten Sie, dass wir selbst bei einem gruppierten Index für beide Tabellen einen HASH JOIN erhalten. Wir können einen der Indizes so umbauen, dass er EINZIGARTIG ist. In diesem Fall muss es der Index auf den Headern sein Tabelle, da dies die einzige ist, die eindeutige Werte für SalesOrderID. hat
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Führen Sie nun die Abfrage erneut aus und beachten Sie, dass der Plan wie ein MERGE JOIN funktioniert.

Diese Pläne profitieren davon, dass die Daten bereits in einem Index sortiert sind, da der Ausführungsplan die Sortierung nutzen kann. Aber manchmal muss SQL Server im Rahmen der Abfrageausführung sortieren. Gelegentlich kann es vorkommen, dass ein SORT-Operator in einem Plan auftaucht, auch wenn Sie keine sortierte Ausgabe anfordern. Wenn SQL Server der Meinung ist, dass ein MERGE JOIN eine gute Option sein könnte, aber eine der Tabellen nicht über den geeigneten gruppierten Index verfügt und klein genug ist, um das Sortieren sehr kostengünstig zu machen, könnte ein SORT ausgeführt werden, um MERGE JOIN zu ermöglichen verwendet.
Aber normalerweise taucht der SORT-Operator in Abfragen auf, bei denen wir nach sortierten Daten mit ORDER BY gefragt haben, wie im folgenden Beispiel.
SELECT * FROM Details
ORDER BY ProductID;
GO

Der gruppierte Index wird gescannt (was dem Scannen der Tabelle entspricht) und dann werden die Zeilen wie angefordert sortiert.
Umgang mit bereits sortiertem Clustered-Index
Was aber, wenn die Daten bereits in einem gruppierten Index sortiert sind und die Abfrage ein ORDER BY für die gruppierte Schlüsselspalte enthält? Im obigen Beispiel haben wir einen gruppierten Index für SalesOrderID in der Details-Tabelle erstellt. Sehen Sie sich die folgenden zwei Abfragen an:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Wenn wir diese Abfragen zusammen ausführen, zeigt das Analysefenster des Quest Spotlight Tuning Pack an, dass die beiden Pläne die gleichen Kosten haben; jeder macht 50% der Gesamtsumme aus. Also, was ist eigentlich der Unterschied zwischen ihnen?
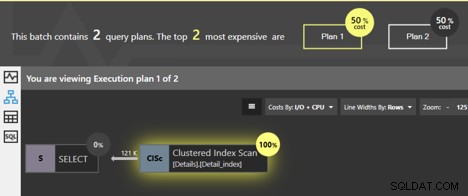
Beide Abfragen scannen den gruppierten Index, und SQL Server weiß, dass die Daten in der Reihenfolge der gruppierten Schlüssel zurückgegeben werden, wenn die Seiten der Blattebene der Reihe nach verfolgt werden. Es muss keine zusätzliche Sortierung durchgeführt werden, daher wird dem Plan kein SORT-Operator hinzugefügt. Aber es gibt einen Unterschied. Wir können auf den Clustered Index Scan-Operator klicken und erhalten einige detaillierte Informationen.
Sehen Sie sich zuerst die detaillierten Informationen für den ersten Plan an, für die Abfrage ohne ORDER BY.

Die Details sagen uns, dass die Eigenschaft „Ordered“ False ist. Eine sortierte Rückgabe der Daten ist dabei nicht erforderlich. Es stellt sich heraus, dass es in den meisten Fällen am einfachsten ist, die Daten abzurufen, indem Sie den Seiten des gruppierten Index folgen, sodass die Daten am Ende der Reihe nach zurückgegeben werden, aber es gibt keine Garantie. Die False-Eigenschaft bedeutet, dass SQL Server den geordneten Seiten nicht folgen muss, um das Ergebnis zurückzugeben. Es gibt tatsächlich andere Möglichkeiten, wie SQL Server alle Zeilen für die Tabelle abrufen kann, ohne dem gruppierten Index zu folgen. Wenn sich SQL Server während der Ausführung entscheidet, eine andere Methode zum Abrufen der Zeilen zu verwenden, würden wir keine geordneten Ergebnisse sehen.
Für die zweite Abfrage sehen die Details so aus:
 Da die Abfrage ein ORDER BY enthielt, besteht die Anforderung, dass die Daten in sortierter Reihenfolge und von SQL Server zurückgegeben werden folgt den Seiten des gruppierten Index in dieser Reihenfolge.
Da die Abfrage ein ORDER BY enthielt, besteht die Anforderung, dass die Daten in sortierter Reihenfolge und von SQL Server zurückgegeben werden folgt den Seiten des gruppierten Index in dieser Reihenfolge.
Das Wichtigste, woran Sie sich erinnern sollten, ist, dass KEINE Garantie für sortierte Daten besteht, wenn Sie ORDER BY nicht in Ihre Abfrage aufnehmen. Nur weil Sie einen geclusterten Index haben, gibt es noch keine Garantie! Selbst wenn Sie im letzten Jahr jedes Mal, wenn Sie die Abfrage ausgeführt haben, die Daten ohne ORDER BY wieder in Ordnung gebracht haben, gibt es keine Garantie dafür, dass Sie die Daten auch weiterhin in Ordnung bekommen. Die Verwendung von ORDER BY ist die einzige Möglichkeit, die Reihenfolge zu garantieren, in der Ihre Ergebnisse zurückgegeben werden.
Tipps zur Verwendung von Sortieroperationen
Ist also ein SORT-Vorgang in der SQL-Server-Diagnose zu vermeiden? Genau wie bei Scans und Hash-Operationen lautet die Antwort natürlich „es kommt darauf an“. Das Sortieren kann sehr teuer sein, insbesondere bei großen Datensätzen. Die richtige Indizierung hilft SQL Server, die Durchführung von SORT-Vorgängen zu vermeiden, da ein Index im Grunde bedeutet, dass Ihre Daten vorsortiert sind. Aber die Indizierung ist mit Kosten verbunden. Zusätzlich zu den Wartungskosten fallen für jeden Index Speicherkosten an. Wenn Ihre Daten stark aktualisiert werden, müssen Sie die Anzahl der Indizes auf ein Minimum beschränken.
Wenn Sie feststellen, dass einige Ihrer langsam ausgeführten Abfragen SORT-Vorgänge in ihren Plänen zeigen und diese SORTs zu den teuersten Operatoren im Plan gehören, können Sie erwägen, Indizes zu erstellen, die es SQL Server ermöglichen, das Sortieren zu vermeiden. Sie müssen jedoch gründliche Tests durchführen, um sicherzustellen, dass die zusätzlichen Indizes nicht andere Abfragen verlangsamen, die für die Gesamtleistung Ihrer Anwendung entscheidend sind.