Im ersten Teil dieser Serie habe ich die grundlegende Terminologie rund um das Logging eingeführt, daher empfehle ich Ihnen, diese zu lesen, bevor Sie mit diesem Beitrag fortfahren. Alles andere, was ich in der Serie behandeln werde, erfordert Kenntnisse über die Architektur des Transaktionsprotokolls, also werde ich dieses Mal darauf eingehen. Auch wenn Sie der Serie nicht folgen werden, sind einige der Konzepte, die ich im Folgenden erläutern werde, für alltägliche Aufgaben, die DBAs in der Produktion erledigen, wissenswert.
Strukturelle Hierarchie
Das Transaktionsprotokoll ist intern in einer dreistufigen Hierarchie organisiert, wie in Abbildung 1 unten gezeigt.
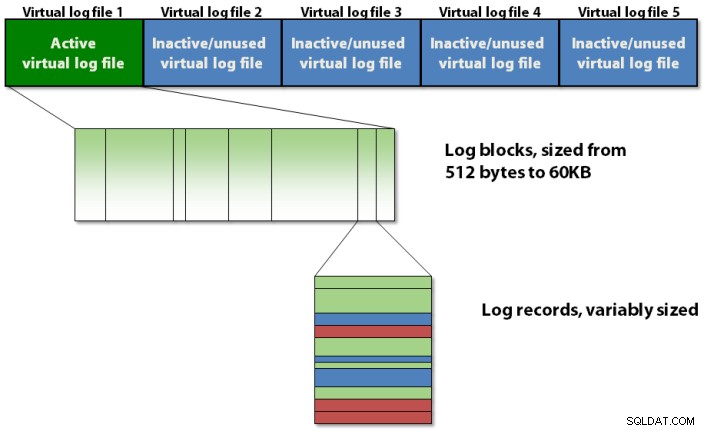 Abbildung 1:Die dreistufige Strukturhierarchie des Transaktionsprotokolls
Abbildung 1:Die dreistufige Strukturhierarchie des Transaktionsprotokolls
Das Transaktionsprotokoll enthält virtuelle Protokolldateien, die Protokollblöcke enthalten, die die eigentlichen Protokolldatensätze speichern.
Virtuelle Protokolldateien
Das Transaktionsprotokoll ist in Abschnitte unterteilt, die als virtuelle Protokolldateien bezeichnet werden , allgemein nur VLFs genannt . Dies geschieht, um die Verwaltung von Vorgängen im Transaktionsprotokoll für den Protokollmanager in SQL Server zu vereinfachen. Wie viele VLFs von SQL Server beim ersten Anlegen der Datenbank erstellt werden oder die Logdatei automatisch wächst, können Sie nicht festlegen, aber Sie können darauf Einfluss nehmen. Der Algorithmus dafür, wie viele VLFs erstellt werden, lautet wie folgt:
- Protokolldateigröße kleiner als 64 MB:Erstellen Sie 4 VLFs mit jeweils etwa 16 MB Größe
- Protokolldateigröße von 64 MB bis 1 GB:Erstellen Sie 8 VLFs, von denen jede etwa 1/8 der Gesamtgröße ausmacht
- Größe der Protokolldatei größer als 1 GB:Erstellen Sie 16 VLFs, von denen jede etwa 1/16 der Gesamtgröße ausmacht
Vor SQL Server 2014, wenn die Protokolldatei automatisch wächst, wird die Anzahl der neuen VLFs, die am Ende der Protokolldatei hinzugefügt werden, durch den obigen Algorithmus basierend auf der Größe der automatischen Vergrößerung bestimmt. Bei Verwendung dieses Algorithmus kann es jedoch, wenn die Größe der automatischen Vergrößerung klein ist und die Protokolldatei vielen automatischen Vergrößerungen unterzogen wird, zu einer sehr großen Anzahl kleiner VLFs führen (als VLF-Fragmentierung bezeichnet). ), die für einige Operationen ein großes Leistungsproblem darstellen kann (siehe hier).
Aufgrund dieses Problems wurde in SQL Server 2014 der Algorithmus für die automatische Vergrößerung der Protokolldatei geändert. Wenn die Größe der automatischen Vergrößerung weniger als 1/8 der Gesamtgröße der Protokolldatei beträgt, wird nur ein neues VLF erstellt, andernfalls wird der alte Algorithmus verwendet. Dadurch wird die Anzahl der VLFs für eine Protokolldatei, die stark automatisch vergrößert wurde, drastisch reduziert. Ein Beispiel für den Unterschied habe ich in diesem Blogbeitrag erklärt.
Jedes VLF hat eine laufende Nummer das es eindeutig identifiziert und an verschiedenen Stellen verwendet wird, was ich weiter unten und in zukünftigen Beiträgen erläutern werde. Sie würden denken, dass die Sequenznummern für eine brandneue Datenbank bei 1 beginnen würden, aber das ist nicht der Fall.
Auf einer SQL Server 2019-Instanz habe ich eine neue Datenbank erstellt, ohne Dateigrößen anzugeben, und dann die VLFs mit dem folgenden Code überprüft:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Beachten Sie die sys.dm_db_log_info DMV wurde in SQL Server 2016 SP2 hinzugefügt. Davor (und heute, weil es noch existiert) können Sie die undokumentierte DBCC LOGINFO verwenden Befehl, aber Sie können ihm keine Auswahlliste geben – führen Sie einfach DBCC LOGINFO(N'NewDB'); aus und die VLF-Sequenznummern sind in der FSeqNo Spalte der Ergebnismenge.
Wie auch immer, die Ergebnisse der Abfrage von sys.dm_db_log_info waren:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Beachten Sie, dass das erste VLF bei Offset 8.192 Bytes in der Protokolldatei beginnt. Dies liegt daran, dass alle Datenbankdateien, einschließlich des Transaktionsprotokolls, eine Dateikopfseite haben, die die ersten 8 KB einnimmt und verschiedene Metadaten über die Datei speichert.
Warum also wählt SQL Server 37 und nicht 1 für die erste VLF-Sequenznummer aus? Es findet die höchste VLF-Sequenznummer im model Datenbank und dann verwendet das erste VLF des Transaktionsprotokolls für jede neue Datenbank diese Nummer plus 1 als Sequenznummer. Ich weiß nicht, warum dieser Algorithmus damals gewählt wurde, aber das ist mindestens seit SQL Server 7.0 so.
Um es zu beweisen, habe ich diesen Code ausgeführt:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); Und die Ergebnisse waren:
Max_VLF_SeqNo -------------------- 36
Da haben Sie es also.
Es gibt noch mehr über VLFs und ihre Verwendung zu diskutieren, aber im Moment reicht es aus zu wissen, dass jedes VLF eine Sequenznummer hat, die sich für jedes VLF um eins erhöht.
Protokollblöcke
Jedes VLF enthält einen kleinen Metadaten-Header, und der Rest des Platzes ist mit Protokollblöcken gefüllt. Jeder Protokollblock beginnt bei 512 Byte und wächst in 512-Byte-Schritten auf eine maximale Größe von 60 KB an, an welcher Stelle er auf die Festplatte geschrieben werden muss. Ein Protokollblock wird möglicherweise auf die Festplatte geschrieben, bevor er seine maximale Größe erreicht, wenn einer der folgenden Fälle eintritt:
- Eine Transaktion wird festgeschrieben, und für diese Transaktion wird keine verzögerte Dauerhaftigkeit verwendet, daher muss der Protokollblock auf die Festplatte geschrieben werden, um die Transaktion dauerhaft zu machen
- Verzögerte Dauerhaftigkeit wird verwendet und die 1-ms-Timer-Aufgabe „den aktuellen Protokollblock auf die Festplatte leeren“ wird ausgelöst
- Eine Datendateiseite wird von einem Prüfpunkt oder dem Lazy Writer auf die Festplatte geschrieben, und es gibt einen oder mehrere Protokolleinträge im aktuellen Protokollblock, die sich auf die zu schreibende Seite auswirken (denken Sie daran, dass die Write-Ahead-Protokollierung erfolgen muss garantiert)
Sie können sich einen Protokollblock als eine Seite mit variabler Größe vorstellen, die Protokolldatensätze in der Reihenfolge speichert, in der sie durch Transaktionen erstellt werden, die die Datenbank ändern. Es gibt keinen Protokollblock für jede Transaktion; Die Protokolldatensätze für mehrere gleichzeitige Transaktionen können in einem Protokollblock vermischt werden. Sie könnten denken, dass dies Schwierigkeiten für Operationen bereiten würde, die alle Protokolldatensätze für eine einzelne Transaktion finden müssen, aber das ist nicht der Fall, wie ich erklären werde, wenn ich in einem späteren Beitrag erkläre, wie Transaktions-Rollbacks funktionieren.
Wenn ein Protokollblock auf die Festplatte geschrieben wird, ist es außerdem durchaus möglich, dass er Protokolldatensätze von nicht festgeschriebenen Transaktionen enthält. Dies ist auch kein Problem, da die Wiederherstellung nach einem Absturz funktioniert – was ein paar Posts in der Zukunft der Serie sind.
Sequenznummern protokollieren
Protokollblöcke haben innerhalb eines VLF eine ID, die bei 1 beginnt und für jeden neuen Protokollblock im VLF um 1 erhöht wird. Protokolldatensätze haben auch innerhalb eines Protokollblocks eine ID, die bei 1 beginnt und für jeden neuen Protokolldatensatz im Protokollblock um 1 erhöht wird. Alle drei Elemente in der Strukturhierarchie des Transaktionsprotokolls haben also eine ID und werden zu einer dreiteiligen Kennung zusammengefasst, die als Protokollfolgenummer bezeichnet wird , häufiger einfach als LSN bezeichnet .
Eine LSN ist definiert als <VLF sequence number>:<log block ID>:<log record ID> (4 Bytes:4 Bytes:2 Bytes) und identifiziert eindeutig einen einzelnen Protokolldatensatz. Es ist eine immer größer werdende Kennung, weil die VLF-Sequenznummern immer weiter steigen.
Grundarbeiten erledigt!
Obwohl es wichtig ist, über VLFs Bescheid zu wissen, ist LSN meiner Meinung nach das wichtigste Konzept, das man im Zusammenhang mit der SQL Server-Implementierung der Protokollierung verstehen muss, da LSNs der Eckpfeiler sind, auf dem Transaktions-Rollback und Wiederherstellung nach einem Absturz aufgebaut sind, und LSNs werden immer wieder auftauchen als Ich arbeite mich durch die Reihe. Im nächsten Beitrag werde ich das Abschneiden von Protokollen und die zirkuläre Natur des Transaktionsprotokolls behandeln, was alles mit VLFs zu tun hat und wie sie wiederverwendet werden.