Verzögerte Dauerhaftigkeit ist ein brandaktuelles, aber interessantes Feature in SQL Server 2014; Der High-Level-Elevator-Pitch des Features ist ganz einfach:
- "Tauschen Sie Langlebigkeit gegen Leistung ein."
Etwas Hintergrund zuerst. Standardmäßig verwendet SQL Server ein Write-Ahead-Protokoll (WAL), was bedeutet, dass Änderungen in das Protokoll geschrieben werden, bevor sie festgeschrieben werden können. In Systemen, in denen das Schreiben von Transaktionsprotokollen zum Engpass wird und in denen es eine moderate Toleranz für Datenverlust gibt , haben Sie jetzt die Möglichkeit, die Anforderung zum Warten auf das Leeren und Bestätigen des Protokolls vorübergehend auszusetzen. Dies nimmt buchstäblich das D aus ACID heraus, zumindest für einen kleinen Teil der Daten (dazu später mehr).
Du bringst dieses Opfer schon jetzt. Im vollständigen Wiederherstellungsmodus besteht immer ein gewisses Risiko von Datenverlust, es wird nur in Zeit und nicht in Größe gemessen. Wenn Sie beispielsweise das Transaktionsprotokoll alle fünf Minuten sichern, könnten Sie im Katastrophenfall bis zu knapp fünf Minuten Daten verlieren. Ich spreche hier nicht von einem einfachen Failover, aber sagen wir, der Server fängt buchstäblich Feuer oder jemand stolpert über das Netzkabel – die Datenbank kann sehr gut nicht wiederherstellbar sein und Sie müssen möglicherweise zum Zeitpunkt der letzten Protokollsicherung zurückkehren . Und das setzt voraus, dass Sie Ihre Backups sogar testen, indem Sie sie irgendwo wiederherstellen – im Falle eines kritischen Fehlers haben Sie möglicherweise nicht den Wiederherstellungspunkt, den Sie zu haben glauben. Wir neigen natürlich dazu, nicht über dieses Szenario nachzudenken, weil wir niemals mit schlechten Dingen™ rechnen passieren.
Wie es funktioniert
Die verzögerte Haltbarkeit ermöglicht es, dass Schreibtransaktionen so weiterlaufen, als ob das Protokoll auf die Festplatte geschrieben worden wäre; In Wirklichkeit wurden die Schreibvorgänge auf der Festplatte gruppiert und zurückgestellt, um im Hintergrund verarbeitet zu werden. Die Transaktion ist optimistisch; es wird davon ausgegangen, dass das Log-Flush wird passieren. Das System verwendet einen 60-KB-Block des Protokollpuffers und versucht, das Protokoll auf die Festplatte zu leeren, wenn dieser 60-KB-Block voll ist (spätestens – es kann und wird oft vorher passieren). Sie können diese Option auf Datenbankebene, auf individueller Transaktionsebene oder – im Fall von nativ kompilierten Prozeduren in In-Memory-OLTP – auf Prozedurebene festlegen. Im Konfliktfall gewinnt die Datenbankeinstellung; Wenn beispielsweise die Datenbank deaktiviert ist, wird der Versuch, eine Transaktion mit der verzögerten Option festzuschreiben, einfach ignoriert, ohne dass eine Fehlermeldung angezeigt wird. Außerdem sind einige Transaktionen immer vollständig dauerhaft, unabhängig von Datenbankeinstellungen oder Commit-Einstellungen; B. Systemtransaktionen, datenbankübergreifende Transaktionen und Vorgänge mit FileTable, Änderungsverfolgung, Änderungsdatenerfassung und Replikation.
Auf Datenbankebene können Sie Folgendes verwenden:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Wenn Sie es auf ALLOWED setzen , das bedeutet, dass jede einzelne Transaktion die verzögerte Haltbarkeit verwenden kann; FORCED bedeutet, dass alle Transaktionen, die eine verzögerte Haltbarkeit verwenden können, dies tun werden (die oben genannten Ausnahmen sind in diesem Fall immer noch relevant). Sie werden wahrscheinlich ALLOWED verwenden wollen statt FORCED – Letzteres kann jedoch bei einer bestehenden Anwendung nützlich sein, bei der Sie diese Option durchgehend verwenden und auch die Menge an Code minimieren möchten, die berührt werden muss. Ein wichtiger Hinweis zu ALLOWED besteht darin, dass vollständig dauerhafte Transaktionen möglicherweise länger warten müssen, da sie zuerst das Löschen aller verzögerten dauerhaften Transaktionen erzwingen.
Auf Transaktionsebene können Sie sagen:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
Und in einer nativ kompilierten In-Memory-OLTP-Prozedur können Sie die folgende Option zu BEGIN ATOMIC hinzufügen blockieren:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Eine häufig gestellte Frage ist, was mit der Sperr- und Isolationssemantik passiert. Nichts ändert sich, wirklich. Das Sperren und Blockieren findet immer noch statt, und Transaktionen werden auf die gleiche Weise und mit den gleichen Regeln festgeschrieben. Der einzige Unterschied besteht darin, dass alle damit verbundenen Sperren viel früher freigegeben werden, indem die Übergabe zugelassen wird, ohne darauf zu warten, dass das Protokoll auf die Festplatte geschrieben wird.
Wann Sie es verwenden sollten
Zusätzlich zu dem Vorteil, den Sie erhalten, wenn Sie die Transaktionen fortfahren lassen, ohne auf das Schreiben von Protokollen zu warten, erhalten Sie auch weniger Protokollschreibvorgänge mit größeren Größen. Dies kann sehr gut funktionieren, wenn Ihr System einen hohen Anteil an Transaktionen hat, die tatsächlich kleiner als 60 KB sind, und insbesondere wenn die Protokollfestplatte langsam ist (obwohl ich ähnliche Vorteile bei SSD und herkömmlicher Festplatte gefunden habe). Es funktioniert nicht so gut, wenn Ihre Transaktionen größtenteils größer als 60 KB sind, wenn sie normalerweise lange laufen oder wenn Sie einen hohen Durchsatz und eine hohe Parallelität haben. Was hier passieren kann, ist, dass Sie den gesamten Protokollpuffer füllen können, bevor der Flush beendet ist, was nur bedeutet, dass Sie Ihre Wartezeiten auf eine andere Ressource übertragen und letztendlich die von den Benutzern der Anwendung wahrgenommene Leistung nicht verbessern.
Mit anderen Worten, wenn Ihr Transaktionsprotokoll derzeit keinen Engpass darstellt, schalten Sie diese Funktion nicht ein. Wie können Sie feststellen, ob Ihr Transaktionsprotokoll derzeit einen Engpass darstellt? Der erste Indikator wäre hoch WRITELOG wartet, insbesondere in Verbindung mit PAGEIOLATCH_** . Paul Randal (@PaulRandal) hat eine großartige vierteilige Serie zum Identifizieren von Transaktionsprotokollproblemen sowie zum Konfigurieren für optimale Leistung:
- Beschneiden des Transaktionsprotokolls auf Fett
- Mehr Fett im Transaktionsprotokoll kürzen
- Probleme bei der Konfiguration des Transaktionsprotokolls
- Transaktionsprotokollüberwachung
Siehe auch diesen Blogpost von Kimberly Tripp (@KimberlyLTripp), 8 Steps to Better Transaction Log Throughput, und den Blogpost des SQL CAT-Teams Diagnosing Transaction Log Performance Issues and Limits of the Log Manager.
Diese Untersuchung kann Sie zu dem Schluss führen, dass es sich lohnt, sich mit der verzögerten Haltbarkeit zu befassen; es darf nicht. Das Testen Ihrer Workload ist der zuverlässigste Weg, um es sicher zu wissen. Wie viele andere Ergänzungen in neueren Versionen von SQL Server (*hust* Hekaton ), ist diese Funktion NICHT darauf ausgelegt, jede einzelne Workload zu verbessern – und wie oben erwähnt, kann sie einige Workloads tatsächlich verschlimmern. In diesem Blogbeitrag von Simon Harvey finden Sie einige weitere Fragen, die Sie sich zu Ihrer Arbeitslast stellen sollten, um festzustellen, ob es möglich ist, etwas Haltbarkeit zu opfern, um eine bessere Leistung zu erzielen.
Möglicher Datenverlust
Ich werde dies mehrmals erwähnen und jedes Mal betonen, wenn ich es tue:Sie müssen gegenüber Datenverlust tolerant sein . Bei einer gut funktionierenden Festplatte beträgt der maximale Verlust bei einer Katastrophe – oder sogar einem geplanten und ordnungsgemäßen Herunterfahren – bis zu einem vollen Block (60 KB). Falls Ihr E/A-Subsystem jedoch nicht mithalten kann, ist es möglich, dass Sie den gesamten Protokollpuffer (~7 MB) verlieren.
Zur Verdeutlichung aus der Dokumentation (Hervorhebung von mir):
Bei verzögerter Dauerhaftigkeit gibt es keinen Unterschied zwischen einem unerwarteten Herunterfahren und einem erwarteten Herunterfahren/Neustart von SQL Server . Wie bei katastrophalen Ereignissen sollten Sie Datenverluste einplanen . Bei einem geplanten Herunterfahren/Neustart werden einige Transaktionen, die nicht auf die Festplatte geschrieben wurden, möglicherweise zuerst auf der Festplatte gespeichert, aber Sie sollten dies nicht planen. Planen Sie so, als ob bei einem geplanten oder ungeplanten Herunterfahren/Neustart die Daten genauso verloren gehen wie bei einem katastrophalen Ereignis.Daher ist es sehr wichtig, dass Sie Ihr Datenverlustrisiko mit Ihrer Notwendigkeit abwägen, Probleme mit der Transaktionsprotokollleistung zu verringern. Wenn Sie eine Bank oder irgendetwas betreiben, das mit Geld zu tun hat, kann es für Sie viel sicherer und angemessener sein, Ihr Protokoll auf eine schnellere Festplatte zu verschieben, als mit dieser Funktion zu würfeln. Wenn Sie versuchen, die Antwortzeit in Ihrer Web Gamerz-Chatraumanwendung zu verbessern, ist das Risiko möglicherweise geringer.
Sie können dieses Verhalten bis zu einem gewissen Grad steuern, um das Risiko eines Datenverlusts zu minimieren. Sie können auf zwei Arten erzwingen, dass alle verzögerten dauerhaften Transaktionen auf die Festplatte geschrieben werden:
- Bestätigen Sie eine vollständig dauerhafte Transaktion.
- Rufen Sie
sys.sp_flush_logauf manuell.
Auf diese Weise können Sie den Datenverlust in Bezug auf die Zeit und nicht auf die Größe kontrollieren. Sie können die Spülung beispielsweise alle 5 Sekunden planen. Aber Sie werden hier Ihren Sweet Spot finden wollen; Zu häufiges Spülen kann den Vorteil der verzögerten Haltbarkeit von vornherein ausgleichen. In jedem Fall müssen Sie Datenverlust tolerieren , auch wenn es nur
Man könnte meinen, dass CHECKPOINT könnte hier helfen, aber dieser Vorgang garantiert technisch gesehen nicht, dass das Protokoll auf die Festplatte geschrieben wird.
Interaktion mit HA/DR
Sie fragen sich vielleicht, wie Delayed Durablity mit HA/DR-Funktionen wie Protokollversand, Replikation und Verfügbarkeitsgruppen funktioniert. Bei den meisten funktioniert es unverändert. Der Protokollversand und die Replikation geben die gehärteten Protokolldatensätze wieder, sodass dort das gleiche Potenzial für Datenverlust besteht. Bei AGs im asynchronen Modus warten wir sowieso nicht auf die sekundäre Bestätigung, daher verhält es sich genauso wie heute. Mit synchron können wir jedoch nicht auf dem primären Knoten festschreiben, bis die Transaktion festgeschrieben und im Remote-Protokoll festgeschrieben ist. Selbst in diesem Szenario können wir lokal einen gewissen Vorteil haben, da wir nicht auf das Schreiben des lokalen Protokolls warten müssen, sondern immer noch auf die Remote-Aktivität. In diesem Szenario gibt es also weniger Nutzen und möglicherweise gar keinen; außer vielleicht in dem seltenen Szenario, in dem die Protokollfestplatte des Primärspeichers sehr langsam und die Protokollfestplatte des Sekundärspeichers sehr schnell ist. Ich vermute, dass die gleichen Bedingungen für die synchrone/asynchrone Spiegelung gelten, aber Sie werden von mir keine offizielle Zusage darüber erhalten, wie ein glänzendes neues Feature mit einem veralteten funktioniert. :-)
Leistungsbeobachtungen
Dies wäre kein großer Beitrag hier, wenn ich nicht einige tatsächliche Leistungsbeobachtungen zeigen würde. Ich habe 8 Datenbanken eingerichtet, um die Auswirkungen von zwei verschiedenen Arbeitslastmustern mit den folgenden Attributen zu testen:
- Wiederherstellungsmodell:einfach vs. vollständig
- Speicherort des Protokolls:SSD vs. HDD
- Haltbarkeit:verzögert vs. voll haltbar
Ich bin wirklich, wirklich, wirklich faul effizient über diese Art von Dingen. Da ich vermeiden möchte, dieselben Operationen in jeder Datenbank zu wiederholen, habe ich die folgende Tabelle vorübergehend in model erstellt :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Dann habe ich einen Satz dynamischer SQL-Befehle erstellt, um diese 8 Datenbanken zu erstellen, anstatt die Datenbanken einzeln zu erstellen und dann mit den Einstellungen herumzuspielen:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Fühlen Sie sich frei, diesen Code selbst auszuführen (mit dem EXEC noch auskommentiert), um zu sehen, dass dies 4 Datenbanken mit deaktivierter verzögerter Dauerhaftigkeit erstellen würde (zwei in FULL-Wiederherstellung, zwei in SIMPLE, jeweils eine mit Protokoll auf langsamer Festplatte und jeweils eine mit Protokoll auf SSD). Wiederholen Sie dieses Muster für 4 Datenbanken mit verzögerter Haltbarkeit FORCED – Ich habe dies getan, um den Code im Test zu vereinfachen, anstatt widerzuspiegeln, was ich im wirklichen Leben tun würde (wobei ich wahrscheinlich einige Transaktionen als kritisch und andere als gut, weniger als kritisch).
Zur Plausibilitätsprüfung habe ich die folgende Abfrage ausgeführt, um sicherzustellen, dass die Datenbanken die richtige Matrix von Attributen hatten:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Ergebnisse:
| Name | Wiederherstellungsmodell | delayed_durability | log_disk |
|---|---|---|---|
| dd1 | VOLL | ERZWUNGEN | SSD |
| dd2 | EINFACH | ERZWUNGEN | SSD |
| dd3 | VOLL | ERZWUNGEN | Festplatte |
| dd4 | EINFACH | ERZWUNGEN | Festplatte |
| dd5 | VOLL | DEAKTIVIERT | SSD |
| dd6 | EINFACH | DEAKTIVIERT | SSD |
| dd7 | VOLL | DEAKTIVIERT | Festplatte |
| dd8 | EINFACH | DEAKTIVIERT | Festplatte |
Relevante Konfiguration der 8 Testdatenbanken
Ich habe den Test auch mehrmals sauber ausgeführt, um sicherzustellen, dass eine 1-GB-Datendatei und eine 1-GB-Protokolldatei ausreichen würden, um den gesamten Satz von Workloads auszuführen, ohne dass Autogrowth-Ereignisse in die Gleichung eingeführt werden. Als bewährte Methode gebe ich mir regelmäßig alle Mühe, um sicherzustellen, dass die Systeme der Kunden über genügend zugewiesenen Speicherplatz verfügen (und ordnungsgemäße Warnmeldungen eingebaut sind), sodass kein Wachstumsereignis jemals zu einem unerwarteten Zeitpunkt auftritt. Ich weiß, dass dies in der realen Welt nicht immer passiert, aber es ist ideal.
Ich habe das zu überwachende System mit SQL Sentry eingerichtet – das würde es mir ermöglichen, die meisten Leistungsmetriken, die ich hervorheben wollte, einfach anzuzeigen. Aber ich habe auch eine temporäre Tabelle erstellt, um Batch-Metriken einschließlich Dauer und sehr spezifischer Ausgabe von sys.dm_io_virtual_file_stats zu speichern:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Dies würde es mir ermöglichen, die Start- und Endzeit jeder einzelnen Charge aufzuzeichnen und Deltas in der DMV zwischen Startzeit und Endzeit zu messen (in diesem Fall nur zuverlässig, weil ich weiß, dass ich der einzige Benutzer im System bin). P>
Viele kleine Transaktionen
Der erste Test, den ich durchführen wollte, waren viele kleine Transaktionen. Für jede Datenbank wollte ich am Ende 500.000 separate Stapel mit jeweils einer einzelnen Einfügung haben:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Denken Sie daran, dass ich versuche, faul zu sein effizient über diese Art von Dingen. Um den Code für alle 8 Datenbanken zu generieren, habe ich Folgendes ausgeführt:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Ich habe diesen Test durchgeführt und mir dann die #Metrics angesehen Tabelle mit der folgenden Abfrage:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Dies ergab die folgenden Ergebnisse (und ich bestätigte durch mehrere Tests, dass die Ergebnisse konsistent waren):
| Datenbank | schreibt | Bytes | Byte/Schreiben | io_stall_ms | start_time | end_time | Dauer (Sekunden) |
|---|---|---|---|---|---|---|---|
| dd1 | 8.068 | 261.894.656 | 32.460,91 | 6.232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8.072 | 261.682.688 | 32.418,56 | 2.740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8.246 | 262.254.592 | 31.803,85 | 3.996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8.055 | 261.688.320 | 32.487,68 | 4.231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500.012 | 526.448.640 | 1.052,87 | 35.593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500.014 | 525.870.080 | 1.051,71 | 35.435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500.015 | 526.120.448 | 1.052,20 | 50.857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500.017 | 525.886.976 | 1.051,73 | 49.680 | 133 |
Kleine Transaktionen:Dauer und Ergebnisse von sys.dm_io_virtual_file_stats
Definitiv einige interessante Beobachtungen hier:
- Die Anzahl der einzelnen Schreibvorgänge war für die Datenbanken mit verzögerter Haltbarkeit sehr gering (ca. 60-fach für herkömmliche Datenbanken).
- Die Gesamtzahl der geschriebenen Bytes wurde durch die Verwendung von Delayed Durability halbiert (ich nehme an, weil alle Schreibvorgänge im herkömmlichen Fall viel verschwendeten Speicherplatz enthielten).
- Die Anzahl der Bytes pro Schreibvorgang war bei Delayed Durability viel höher. Dies war nicht allzu überraschend, da der ganze Zweck dieser Funktion darin besteht, Schreibvorgänge in größeren Stapeln zusammenzufassen.
- Die Gesamtdauer der E/A-Blockierungen war volatil, aber ungefähr eine Größenordnung niedriger für die verzögerte Haltbarkeit. Die Unterbrechungen bei vollständig dauerhaften Transaktionen waren viel empfindlicher für den Festplattentyp.
- Falls Sie bisher etwas nicht überzeugt hat, ist die Dauer-Spalte sehr aufschlussreich. Vollständig haltbare Chargen, die zwei Minuten oder länger dauern, werden fast halbiert.
Die Start-/Endzeitspalten ermöglichten es mir, mich auf das Leistungsberater-Dashboard für den genauen Zeitraum zu konzentrieren, in dem diese Transaktionen stattfanden, wo wir viele zusätzliche visuelle Indikatoren zeichnen können:
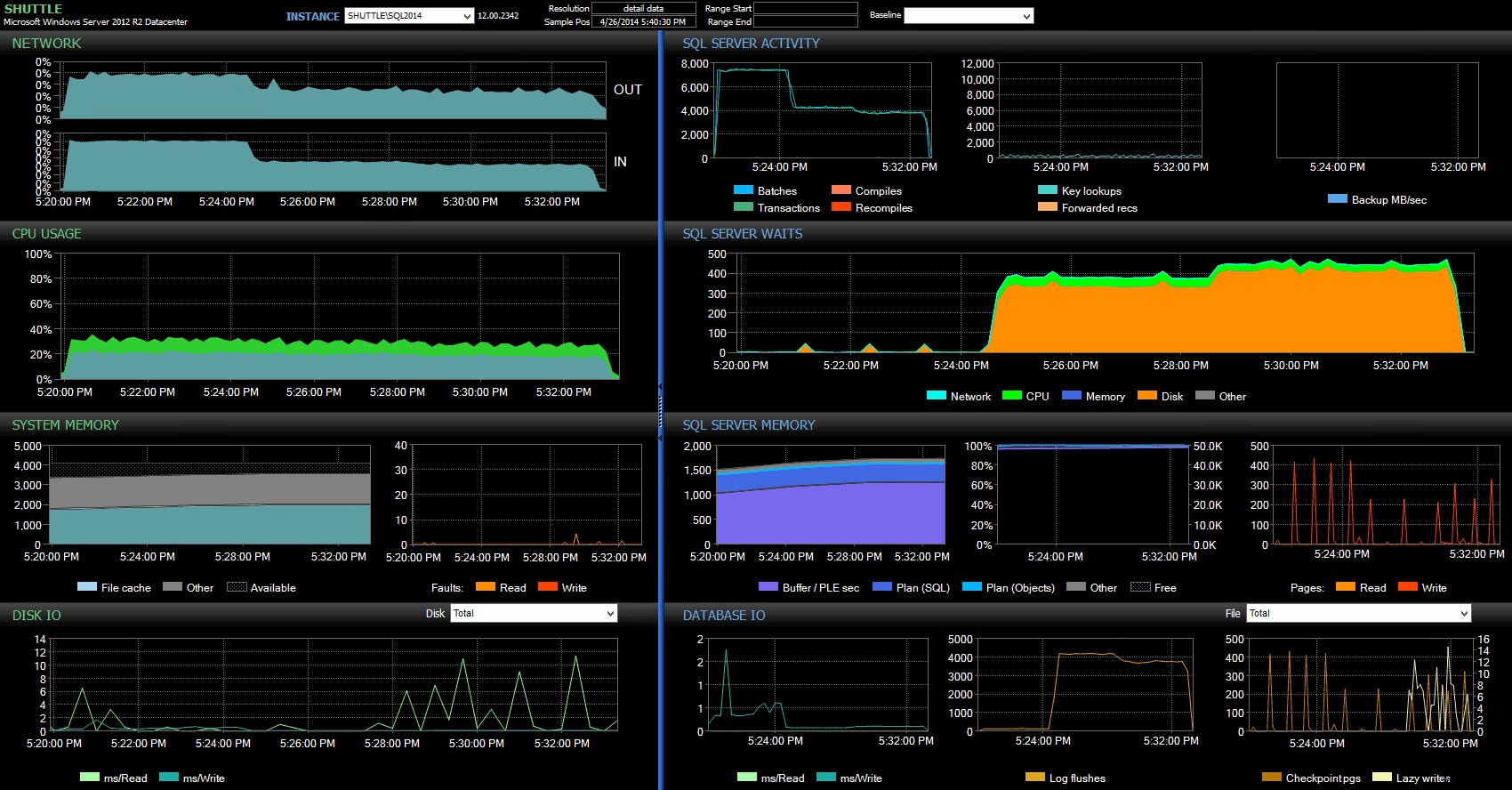
SQL Sentry-Dashboard – zum Vergrößern klicken
Weitere Beobachtungen hier:
- Auf mehreren Diagrammen können Sie genau sehen, wann der nicht verzögerte Haltbarkeitsanteil des Stapels übernommen wurde (ca. 17:24:32 Uhr).
- Es gibt keine beobachtbaren Auswirkungen auf die CPU oder den Speicher, wenn die verzögerte Haltbarkeit verwendet wird.
- Im ersten Diagramm unter SQL Server-Aktivität können Sie einen enormen Einfluss auf Batches/Transaktionen pro Sekunde erkennen.
- SQL Server-Wartezeiten gehen durch die Decke, wenn die vollständig dauerhaften Transaktionen gestartet werden. Diese bestanden fast ausschließlich aus
WRITELOGwartet, mit einer kleinen Anzahl vonPAGEIOLOATCH_EXundPAGEIOLATCH_UPwartet auf ein gutes Maß. - Die Gesamtzahl der Log-Flushes während der Vorgänge mit verzögerter Haltbarkeit war recht gering (niedrige 100 s/s), während diese für das herkömmliche Verhalten auf über 4.000/s stieg (und etwas niedriger für die HDD-Dauer des Tests).
Weniger, größere Transaktionen
Für den nächsten Test wollte ich sehen, was passieren würde, wenn wir weniger Operationen ausführen würden, aber sicherstellen würden, dass jede Anweisung eine größere Datenmenge betrifft. Ich wollte, dass dieser Batch für jede Datenbank ausgeführt wird:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Also habe ich wieder die Lazy-Methode verwendet, um 8 Kopien dieses Skripts zu erstellen, eine pro Datenbank:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Ich habe diesen Stapel ausgeführt und dann die Abfrage gegen #Metrics geändert oben, um den zweiten Test anstelle des ersten zu betrachten. Die Ergebnisse:
| Datenbank | schreibt | Bytes | Byte/Schreiben | io_stall_ms | start_time | end_time | Dauer (Sekunden) |
|---|---|---|---|---|---|---|---|
| dd1 | 20.970 | 1.271.911.936 | 60.653,88 | 12.577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20.997 | 1.272.145.408 | 60.587,00 | 14.698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20.973 | 1.272.982.016 | 60.696,22 | 12.085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20.958 | 1.272.064.512 | 60.695,89 | 11.795 | 143 | ||
| dd5 | 30.138 | 1.282.231.808 | 42.545,35 | 7.402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30.138 | 1.282.260.992 | 42.546,31 | 7.806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30.129 | 1.281.575.424 | 42.536,27 | 9.888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30.130 | 1.281.449.472 | 42.530,68 | 11.452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
Größere Transaktionen:Dauer und Ergebnisse von sys.dm_io_virtual_file_stats
Diesmal ist der Einfluss der verzögerten Haltbarkeit viel weniger spürbar. Wir sehen eine etwas geringere Anzahl von Schreibvorgängen bei einer etwas größeren Anzahl von Bytes pro Schreibvorgang, wobei die insgesamt geschriebenen Bytes fast identisch sind. In diesem Fall sehen wir tatsächlich, dass die E/A-Stalls für die verzögerte Haltbarkeit höher sind, und dies erklärt wahrscheinlich die Tatsache, dass die Dauern auch fast identisch waren.
Aus dem Performance Advisor-Dashboard sehen wir einige Ähnlichkeiten mit dem vorherigen Test und auch einige deutliche Unterschiede:
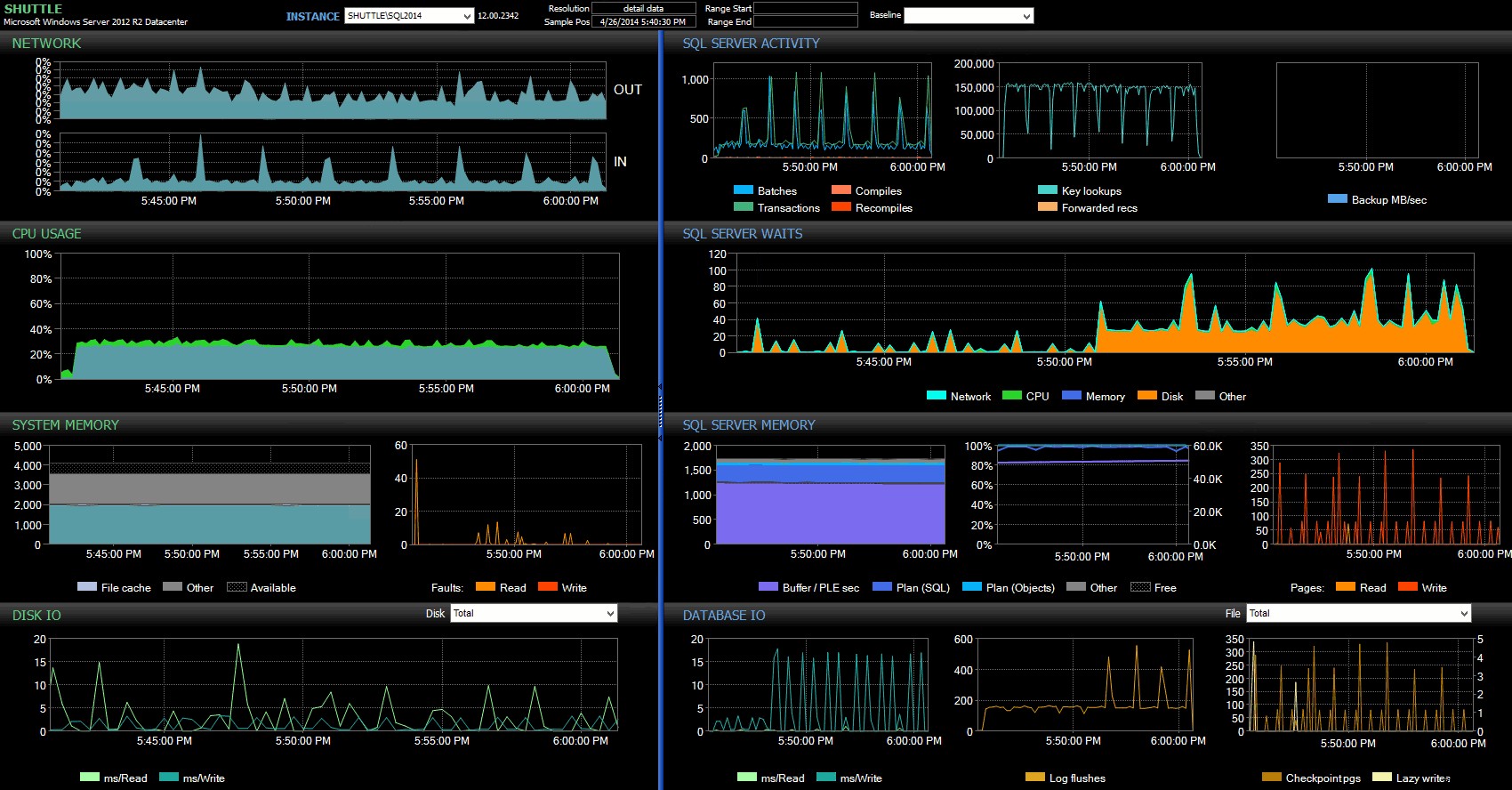
SQL Sentry-Dashboard – zum Vergrößern klicken
Einer der großen Unterschiede, die hier hervorzuheben sind, ist, dass das Delta in den Wartestatistiken nicht ganz so ausgeprägt ist wie beim vorherigen Test – es gibt immer noch eine viel höhere Häufigkeit von WRITELOG wartet auf die vollständig haltbaren Chargen, aber bei weitem nicht auf dem Niveau der kleineren Transaktionen. Eine andere Sache, die Sie sofort erkennen können, ist, dass die zuvor beobachteten Auswirkungen auf Batches und Transaktionen pro Sekunde nicht mehr vorhanden sind. Und schließlich, obwohl es bei vollständig dauerhaften Transaktionen mehr Log-Flushes gibt als bei verzögerten Transaktionen, ist dieser Unterschied weit weniger ausgeprägt als bei kleineren Transaktionen.
Schlussfolgerung
Es sollte klar sein, dass es bestimmte Workload-Typen gibt, die stark von der verzögerten Dauerhaftigkeit profitieren können – vorausgesetzt natürlich, dass Sie eine Toleranz für Datenverlust haben . Dieses Feature ist nicht auf In-Memory-OLTP beschränkt, steht in allen Editionen von SQL Server 2014 zur Verfügung und kann mit wenigen bis gar keinen Codeänderungen implementiert werden. Es kann sicherlich eine leistungsstarke Technik sein, wenn Ihr Workload es unterstützen kann. Aber auch hier müssen Sie Ihren Workload testen, um sicher zu sein, dass er von dieser Funktion profitiert, und auch genau überlegen, ob Sie dadurch dem Risiko von Datenverlusten ausgesetzt sind.
Abgesehen davon mag dies der SQL Server-Menge wie eine frische neue Idee erscheinen, aber in Wahrheit hat Oracle dies 2006 als "Asynchronous Commit" eingeführt (siehe COMMIT WRITE ... NOWAIT). wie hier dokumentiert und 2007 gebloggt). Und die Idee selbst gibt es schon seit fast 3 Jahrzehnten; siehe Hal Berensons kurze Chronik seiner Geschichte.
Nächstes Mal
Eine Idee, mit der ich herumgekämpft habe, ist der Versuch, die Leistung von tempdb zu verbessern indem dort die verzögerte Haltbarkeit erzwungen wird. Eine besondere Eigenschaft von tempdb Das macht es zu einem so verlockenden Kandidaten, weil es von Natur aus vorübergehend ist – alles in tempdb ist explizit so konzipiert, dass es nach einer Vielzahl von Systemereignissen verschoben werden kann. Ich sage das jetzt, ohne eine Ahnung zu haben, ob es eine Workload-Form gibt, bei der dies gut funktionieren wird; aber ich habe vor, es auszuprobieren, und wenn ich etwas Interessantes finde, können Sie sicher sein, dass ich hier darüber berichten werde.