In meinem letzten Beitrag habe ich eine Serie begonnen, in der es um proaktive Zustandsprüfungen geht, die für Ihren SQL Server von entscheidender Bedeutung sind. Wir haben mit Speicherplatz begonnen und in diesem Beitrag werden wir Wartungsaufgaben besprechen. Eine der grundlegenden Verantwortlichkeiten eines DBA besteht darin, sicherzustellen, dass die folgenden Wartungsaufgaben regelmäßig ausgeführt werden:
- Sicherungen
- Integritätsprüfungen
- Indexpflege
- Statistikaktualisierungen
Ich wette, dass Sie bereits Jobs haben, um diese Aufgaben zu bewältigen. Und ich würde auch wetten, dass Sie Benachrichtigungen konfiguriert haben, die Sie und Ihr Team per E-Mail benachrichtigen, wenn ein Job fehlschlägt. Wenn beides zutrifft, gehen Sie bereits proaktiv mit der Wartung um. Und wenn Sie nicht beides tun, müssen Sie das jetzt beheben – wie in, hören Sie auf, dies zu lesen, laden Sie Ola Hallengrens Skripte herunter, planen Sie sie und stellen Sie sicher, dass Sie Benachrichtigungen einrichten. (Eine weitere Alternative speziell für die Indexverwaltung, die wir unseren Kunden ebenfalls empfehlen, ist der SQL Sentry Fragmentation Manager.)
Wenn Sie nicht wissen, ob Ihre Jobs so eingestellt sind, dass sie Ihnen eine E-Mail senden, wenn sie fehlschlagen, verwenden Sie diese Abfrage:
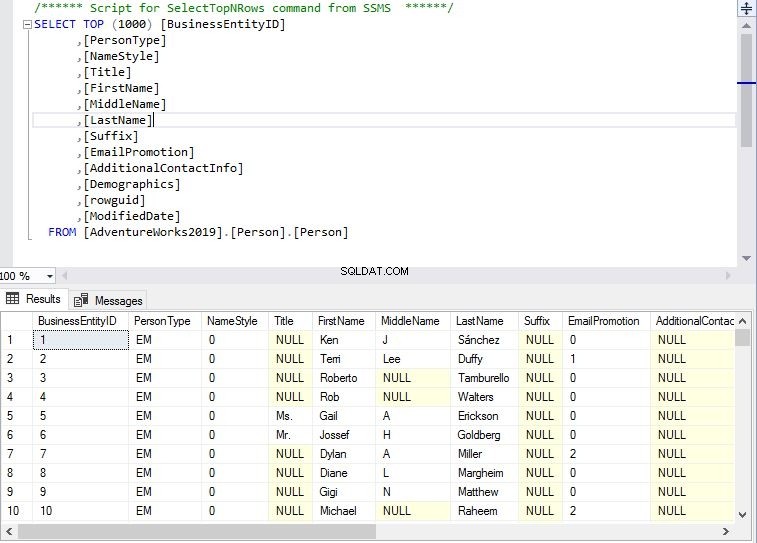
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Die proaktive Wartung geht jedoch noch einen Schritt weiter. Sie müssen nicht nur sicherstellen, dass Ihre Jobs ausgeführt werden, sondern auch wissen, wie lange sie dauern. Sie können die Systemtabellen in msdb verwenden, um dies zu überwachen:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Wenn Sie Olas Skripte und Protokollinformationen verwenden, können Sie auch seine CommandLog-Tabelle abfragen:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Das obige Skript listet die Sicherungsdauer für jede vollständige Sicherung für die AdventureWorks2014-Datenbank auf. Sie können davon ausgehen, dass die Dauer der Wartungsaufgaben mit der Zeit langsam ansteigt, wenn die Datenbanken größer werden. Daher suchen Sie nach starken Erhöhungen oder unerwarteten Verkürzungen der Dauer. Ich hatte zum Beispiel einen Kunden mit einer durchschnittlichen Sicherungsdauer von weniger als 30 Minuten. Plötzlich dauern Sicherungen länger als eine Stunde. Die Größe der Datenbank hatte sich nicht wesentlich geändert, es hatten sich keine Einstellungen für die Instanz oder Datenbank geändert, nichts hatte sich an der Hardware- oder Festplattenkonfiguration geändert. Ein paar Wochen später sank die Backup-Dauer wieder auf weniger als eine halbe Stunde. Einen Monat später stiegen sie wieder auf. Wir haben schließlich die Änderung der Backup-Dauer mit Failovern zwischen Cluster-Knoten korreliert. Auf einem Knoten dauerten die Backups weniger als eine halbe Stunde. Andererseits dauerten sie über eine Stunde. Eine kleine Untersuchung der Konfiguration der NICs und des SAN-Fabric und wir konnten das Problem lokalisieren.
Es ist auch wichtig, die durchschnittliche Ausführungszeit für CHECKDB-Operationen zu verstehen. Dies ist etwas, worüber Paul in unserem Immersions-Event zu Hochverfügbarkeit und Notfallwiederherstellung spricht:Sie müssen wissen, wie lange CHECKDB normalerweise zum Ausführen braucht, damit Sie wissen, wie lange es dauern sollte, wenn Sie eine Beschädigung finden und eine Überprüfung der gesamten Datenbank durchführen dauern, bis CHECKDB abgeschlossen ist. Wenn Ihr Chef fragt:„Wie lange dauert es noch, bis wir das Ausmaß des Problems kennen?“ Sie können eine quantitative Antwort auf die Mindestzeit geben, die Sie warten müssen. Wenn CHECKDB länger als gewöhnlich dauert, wissen Sie, dass etwas gefunden wurde (was nicht unbedingt eine Beschädigung sein muss; Sie müssen die Prüfung immer zu Ende führen).
Wenn Sie nun Hunderte von Datenbanken verwalten, möchten Sie die obige Abfrage nicht für jede Datenbank oder jeden Job ausführen. Stattdessen möchten Sie vielleicht nur Jobs finden, die um einen bestimmten Prozentsatz außerhalb der durchschnittlichen Dauer liegen, die Sie mit dieser Abfrage erhalten können:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Diese Abfrage listet Jobs auf, die 25 % länger als der Durchschnitt gedauert haben. Die Abfrage erfordert einige Anpassungen, um die gewünschten Informationen bereitzustellen – einige Jobs mit einer kurzen Dauer (z. B. weniger als 5 Minuten) werden angezeigt, wenn sie nur ein paar zusätzliche Minuten dauern – das ist möglicherweise kein Problem. Dennoch ist diese Abfrage ein guter Anfang, und erkennen Sie, dass es viele Möglichkeiten gibt, Abweichungen zu finden – Sie könnten auch jede Ausführung mit der vorherigen vergleichen und nach Jobs suchen, die einen bestimmten Prozentsatz länger als die vorherige gedauert haben.
Offensichtlich ist die Auftragsdauer die logischste Kennung für potenzielle Probleme – ob es sich um einen Sicherungsauftrag, eine Integritätsprüfung oder den Auftrag handelt, der Fragmentierung entfernt und Statistiken aktualisiert. Ich habe festgestellt, dass die größten Schwankungen in der Dauer typischerweise in den Aufgaben zum Entfernen von Fragmentierung und Aktualisieren von Statistiken liegen. Abhängig von Ihren Schwellenwerten für Neuorganisation versus Neuaufbau und der Volatilität Ihrer Daten können Sie Tage mit hauptsächlich Neuorganisationen verbringen und dann plötzlich ein paar Indexneuaufbauten für große Tabellen einsetzen, wobei diese Neuaufbauten die durchschnittliche Dauer vollständig verändern. Möglicherweise möchten Sie Ihre Schwellenwerte für einige Indizes ändern oder den Füllfaktor anpassen, sodass Neuerstellungen häufiger oder seltener erfolgen – je nach Index und Fragmentierungsgrad. Um diese Anpassungen vorzunehmen, müssen Sie sich ansehen, wie oft jeder Index neu erstellt oder neu organisiert wird, was Sie nur tun können, wenn Sie Olas Skripte verwenden und sich in der CommandLog-Tabelle protokollieren oder wenn Sie Ihre eigene Lösung gerollt haben und protokollieren jede Neuorganisation oder Neuerstellung. Um dies anhand der CommandLog-Tabelle zu sehen, können Sie zunächst prüfen, welche Indizes am häufigsten geändert werden:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Anhand dieser Ausgabe können Sie beginnen zu sehen, welche Tabellen (und damit Indizes) die größte Volatilität aufweisen, und dann bestimmen, ob der Schwellenwert für die Neuorganisation im Vergleich zum Neuaufbau angepasst oder der Füllfaktor geändert werden muss.
Das Leben leichter machen
Jetzt gibt es eine einfachere Lösung als das Schreiben eigener Abfragen, solange Sie SQL Sentry Event Manager (EM) verwenden. Das Tool überwacht alle auf einer Instanz eingerichteten Agent-Jobs, und anhand der Kalenderansicht können Sie schnell sehen, welche Jobs fehlgeschlagen sind, abgebrochen wurden oder länger als gewöhnlich liefen:
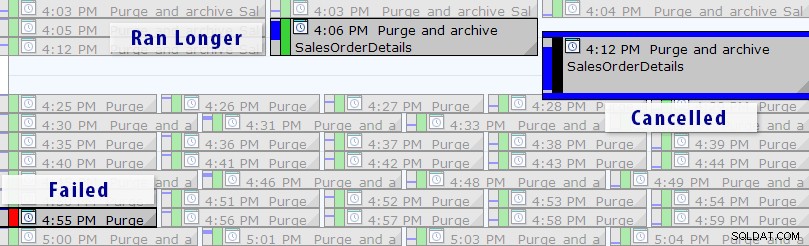 SQL Sentry Event Manager-Kalenderansicht (mit in Photoshop hinzugefügten Beschriftungen)
SQL Sentry Event Manager-Kalenderansicht (mit in Photoshop hinzugefügten Beschriftungen)
Sie können auch einzelne Ausführungen aufschlüsseln, um zu sehen, wie lange die Ausführung eines Jobs gedauert hat, und es gibt auch praktische Laufzeitdiagramme, mit denen Sie schnell alle Muster in Daueranomalien oder Fehlerbedingungen visualisieren können. In diesem Fall sehe ich, dass die Laufzeitdauer für diesen speziellen Job etwa alle 15 Minuten um fast 400 % sprunghaft angestiegen ist:
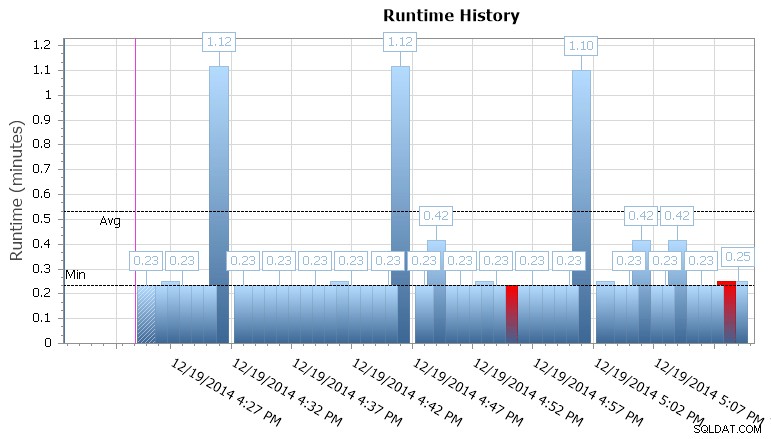 SQL Sentry Event Manager-Laufzeitdiagramm
SQL Sentry Event Manager-Laufzeitdiagramm
Dies gibt mir einen Hinweis darauf, dass ich mich mit anderen geplanten Jobs befassen sollte, die hier möglicherweise Probleme mit der Parallelität verursachen. Ich könnte den Kalender wieder herauszoomen, um zu sehen, welche anderen Jobs ungefähr zur gleichen Zeit ausgeführt werden, oder ich muss nicht einmal hinsehen, um zu erkennen, dass dies ein Berichts- oder Sicherungsjob ist, der für diese Datenbank ausgeführt wird.
Zusammenfassung
Ich würde wetten, dass die meisten von Ihnen bereits die erforderlichen Wartungsaufträge eingerichtet haben und dass Sie auch Benachrichtigungen für Auftragsausfälle eingerichtet haben. Wenn Sie mit der durchschnittlichen Dauer Ihrer Jobs nicht vertraut sind, dann ist dies Ihr nächster Schritt, um proaktiv zu sein. Hinweis:Möglicherweise müssen Sie auch überprüfen, wie lange Sie den Auftragsverlauf aufbewahren. Wenn ich nach Abweichungen in der Beschäftigungsdauer suche, ziehe ich es vor, die Daten von einigen Monaten statt von einigen Wochen zu betrachten. Sie müssen sich diese Laufzeiten nicht merken, aber sobald Sie sich vergewissert haben, dass Sie genügend Daten speichern, um den Verlauf für die Forschung zu verwenden, suchen Sie regelmäßig nach Variationen. Im Idealfall kann die erhöhte Laufzeit Sie auf ein potenzielles Problem aufmerksam machen, sodass Sie es beheben können, bevor ein Problem in Ihrer Produktionsumgebung auftritt.