In diesem Artikel untersuchen wir, wann und wie die SQL PARTITION BY-Klausel verwendet wird, und vergleichen sie mit der Verwendung der GROUP BY-Klausel.
Die Fensterfunktion verstehen
Datenbankbenutzer verwenden Aggregatfunktionen wie MAX(), MIN(), AVERAGE() und COUNT() zur Durchführung von Datenanalysen. Diese Funktionen arbeiten mit einer ganzen Tabelle und geben einzelne aggregierte Daten mithilfe der GROUP BY-Klausel zurück. Manchmal benötigen wir aggregierte Werte über eine kleine Gruppe von Zeilen. In diesem Fall hilft die Fensterfunktion in Kombination mit der Aggregatfunktion, die gewünschte Ausgabe zu erzielen. Die Window-Funktion verwendet die OVER()-Klausel und kann die folgenden Funktionen enthalten:
- Partitionieren nach: Dadurch werden die Zeilen oder die Ergebnismenge der Abfrage in kleine Partitionen unterteilt.
- Bestellen nach: Dadurch werden die Zeilen für das Partitionsfenster in aufsteigender oder absteigender Reihenfolge angeordnet. Die Standardreihenfolge ist aufsteigend.
- Zeile oder Bereich: Sie können die Zeilen in einer Partition weiter einschränken, indem Sie die Start- und Endpunkte angeben.
In diesem Artikel konzentrieren wir uns auf die Untersuchung der SQL PARTITION BY-Klausel.
Beispieldaten vorbereiten
Angenommen, wir haben eine Tabelle [SalesLT].[Orders], in der Kundenauftragsdetails gespeichert sind. Es hat eine Spalte [Stadt], die die Kundenstadt angibt, in der die Bestellung aufgegeben wurde.
CREATE TABLE [SalesLT].[Orders] ( orderid INT, orderdate DATE, customerName VARCHAR(100), City VARCHAR(50), amount MONEY ) INSERT INTO [SalesLT].[Orders] SELECT 1,'01/01/2021','Mohan Gupta','Alwar',10000 UNION ALL SELECT 2,'02/04/2021','Lucky Ali','Kota',20000 UNION ALL SELECT 3,'03/02/2021','Raj Kumar','Jaipur',5000 UNION ALL SELECT 4,'04/02/2021','Jyoti Kumari','Jaipur',15000 UNION ALL SELECT 5,'05/03/2021','Rahul Gupta','Jaipur',7000 UNION ALL SELECT 6,'06/04/2021','Mohan Kumar','Alwar',25000 UNION ALL SELECT 7,'07/02/2021','Kashish Agarwal','Alwar',15000 UNION ALL SELECT 8,'08/03/2021','Nagar Singh','Kota',2000 UNION ALL SELECT 9,'09/04/2021','Anil KG','Alwar',1000 Go
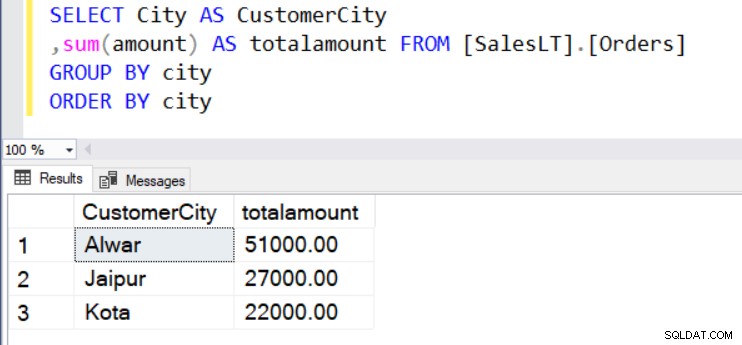
Nehmen wir an, wir möchten den Gesamtbestellwert nach Standort (Stadt) wissen. Zu diesem Zweck verwenden wir die SUM()- und GROUP BY-Funktion wie unten gezeigt.
SELECT City AS CustomerCity ,sum(amount) AS totalamount FROM [SalesLT].[Orders] GROUP BY city ORDER BY city
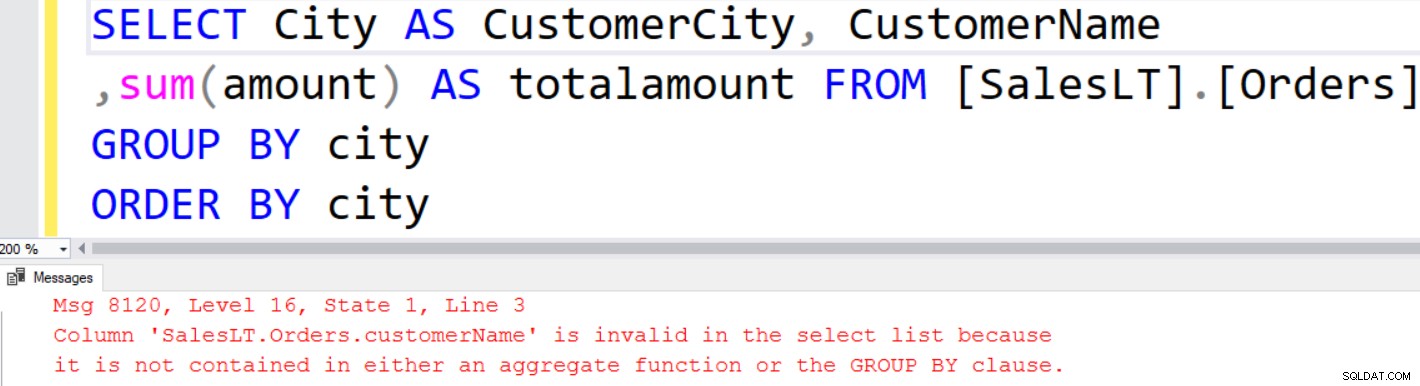
Im Resultset können wir die nicht aggregierten Spalten in der SELECT-Anweisung nicht verwenden. Beispielsweise können wir [CustomerName] nicht in der Ausgabe anzeigen, da er nicht in der GROUP BY-Klausel enthalten ist.
SQL Server gibt die folgende Fehlermeldung aus, wenn Sie versuchen, die nicht aggregierte Spalte in der Spaltenliste zu verwenden.
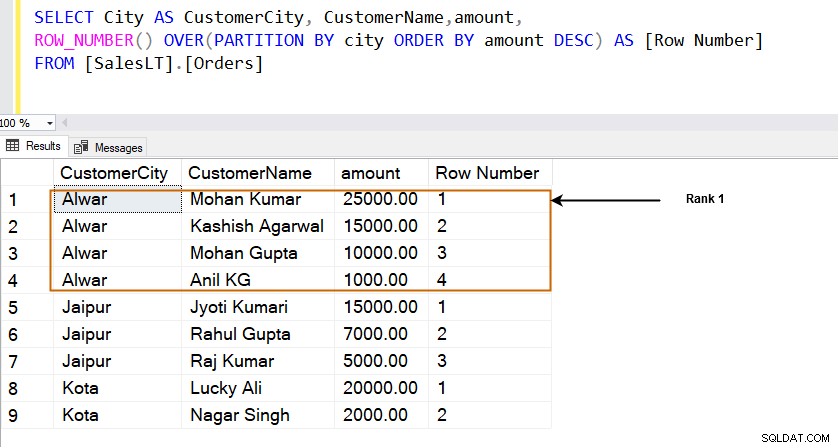
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount FROM [SalesLT].[Orders]
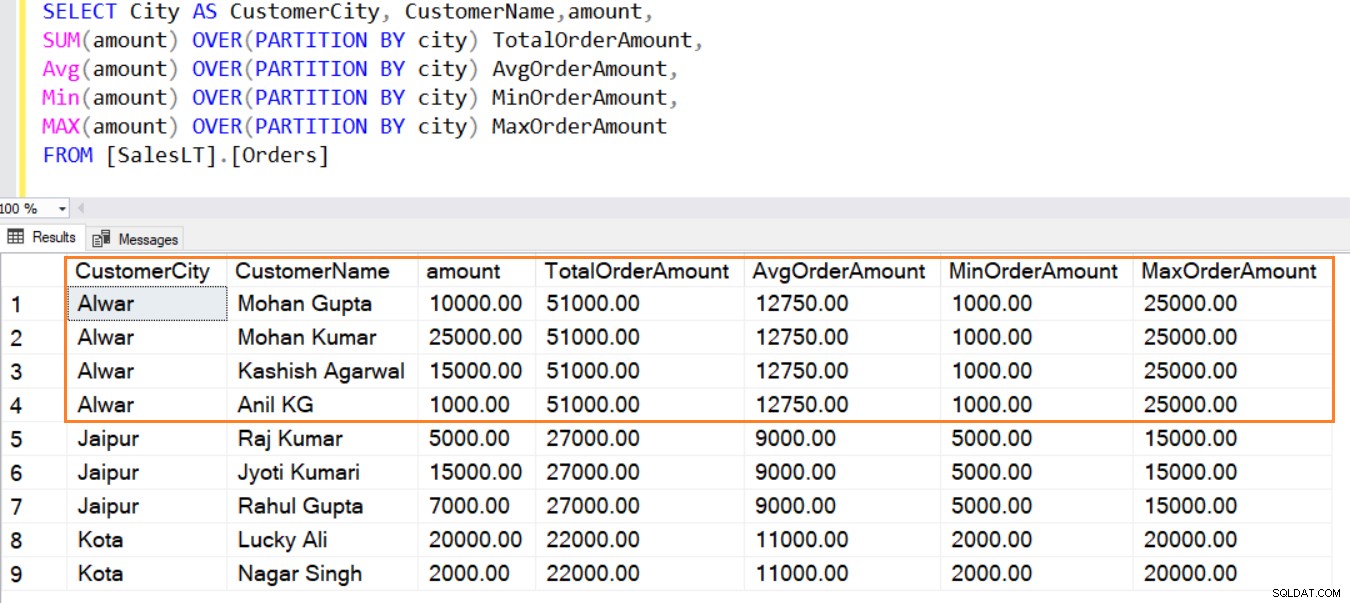
Wie unten gezeigt, erstellt die PARTITION BY-Klausel ein kleineres Fenster (Satz von Datenzeilen), führt die Aggregation durch und zeigt sie an. Sie können in dieser Ausgabe auch nicht aggregierte Spalten anzeigen.
Ebenso können Sie die Funktionen AVG(), MIN(), MAX() verwenden, um den durchschnittlichen, minimalen und maximalen Betrag aus den Zeilen in einem Fenster zu berechnen.
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount, Avg(amount) OVER(PARTITION BY city) AvgOrderAmount, Min(amount) OVER(PARTITION BY city) MinOrderAmount, MAX(amount) OVER(PARTITION BY city) MaxOrderAmount FROM [SalesLT].[Orders]
Verwenden der SQL-Klausel PARTITION BY mit der Funktion ROW_NUMBER()
Bisher haben wir die aggregierten Werte in einem Fenster mit der PARTITION BY-Klausel erhalten. Angenommen, wir benötigen anstelle der Gesamtsumme die kumulierte Gesamtsumme in einer Partition.
Eine kumulative Summe funktioniert auf folgende Weise.
| Zeile | Kumulative Gesamtsumme |
| 1 | Rang 1+2 |
| 2 | Rang 2+3 |
| 3 | Rang 3+4 |
Der Zeilenrang wird mit der Funktion ROW_NUMBER() berechnet. Lassen Sie uns zuerst diese Funktion verwenden und die Zeilenränge anzeigen.
- Die Funktion ROW_NUMBER() verwendet die Klauseln OVER und PARTITION BY und sortiert die Ergebnisse in aufsteigender oder absteigender Reihenfolge. Es beginnt mit der Rangfolge von Zeilen ab 1 pro Sortierreihenfolge.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number] FROM [SalesLT].[Orders]
Beispielsweise befindet sich in der Stadt [Alwar] die Zeile mit dem höchsten Betrag (25000,00) in Zeile 1. Wie unten gezeigt, werden Zeilen in dem durch die PARTITION BY-Klausel angegebenen Fenster in eine Rangfolge gebracht. Zum Beispiel haben wir drei verschiedene Städte [Alwar], [Jaipur] und [Kota], und jedes Fenster (Stadt) erhält seine Reihenränge.
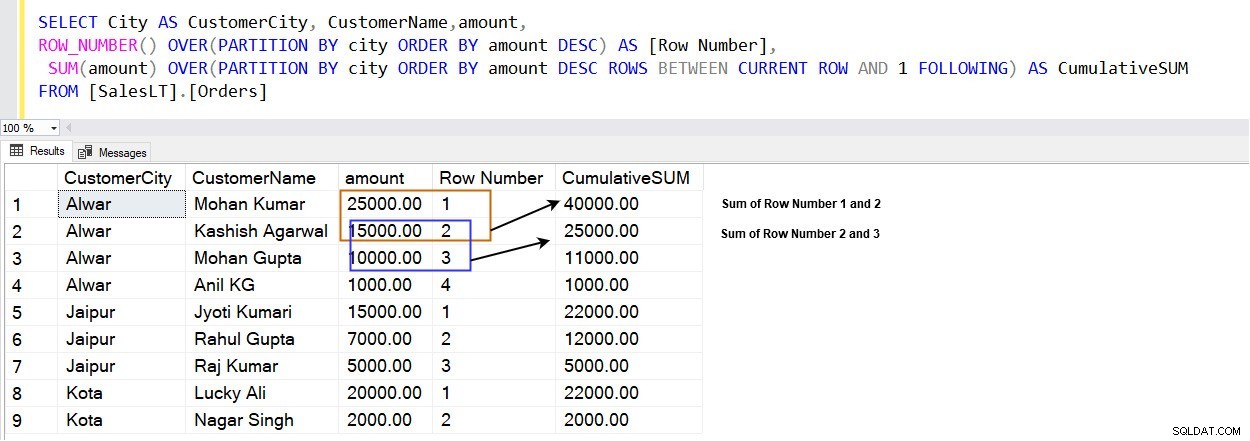
Um die kumulierte Summe zu berechnen, verwenden wir die folgenden Argumente.
- AKTUELLE REIHE:Gibt den Start- und Endpunkt im angegebenen Bereich an.
- 1 following:Gibt die Anzahl der Zeilen (1) an, die ab der aktuellen Zeile folgen sollen.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS CumulativeSUM FROM [SalesLT].[Orders]
Das folgende Bild zeigt, dass Sie eine kumulative Summe anstelle einer Gesamtsumme in einem Fenster erhalten, das durch die PARTITION BY-Klausel angegeben wird.
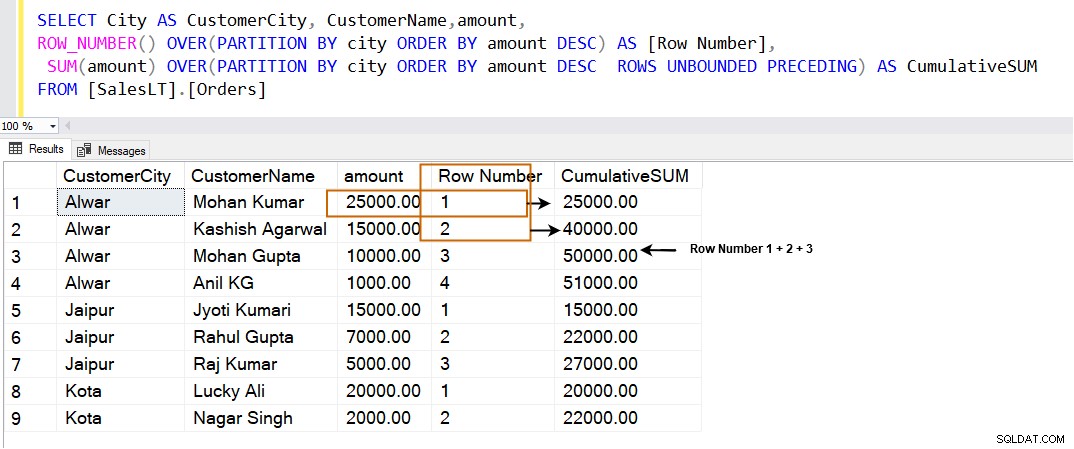
Wenn wir ROWS UNBOUNDED PRECEDING verwenden in der SQL PARTITION BY-Klausel wird die kumulierte Summe wie folgt berechnet. Es verwendet die aktuellen Zeilen zusammen mit den Zeilen mit den höchsten Werten im angegebenen Fenster.
| Zeile | Kumulative Gesamtsumme |
| 1 | Rang 1 |
| 2 | Rang 1+2 |
| 3 | Rang 1+2+3 |
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS UNBOUNDED PRECEDING) AS CumulativeSUM FROM [SalesLT].[Orders]
Vergleich der GROUP BY- und SQL PARTITION BY-Klausel
| GRUPPE NACH | PARTITION VON |
| Es gibt eine Zeile pro Gruppe zurück, nachdem die aggregierten Werte berechnet wurden. | Es gibt alle Zeilen aus der SELECT-Anweisung zusammen mit zusätzlichen Spalten mit aggregierten Werten zurück. |
| Wir können die nicht aggregierte Spalte in der SELECT-Anweisung nicht verwenden. | Wir können erforderliche Spalten in der SELECT-Anweisung verwenden, und es werden keine Fehler für die nicht aggregierte Spalte erzeugt. |
| Es erfordert die Verwendung der HAVING-Klausel, um Datensätze aus der SELECT-Anweisung zu filtern. | Die PARTITION-Funktion kann neben den in der SELECT-Anweisung verwendeten Spalten zusätzliche Prädikate in der WHERE-Klausel haben. |
| Das GROUP BY wird in regulären Aggregaten verwendet. | PARTITION BY wird in gefensterten Aggregaten verwendet. |
| Wir können es nicht zur Berechnung von Zeilennummern oder deren Rängen verwenden. | Es kann Zeilennummern und ihre Ränge im kleineren Fenster berechnen. |
Einsetzen
Es wird empfohlen, die SQL PARTITION BY-Klausel zu verwenden, wenn Sie mit mehreren Datengruppen für die aggregierten Werte in der einzelnen Gruppe arbeiten. Ebenso kann es verwendet werden, um Originalzeilen mit der zusätzlichen Spalte mit aggregierten Werten anzuzeigen.