Auf einigen Testtabellen meinerseits sieht Ihr ursprünglicher Plan wie folgt aus.
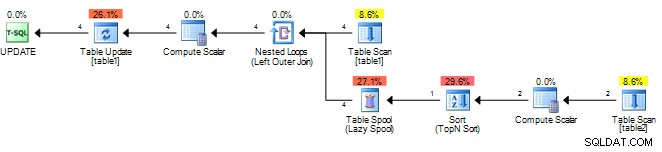
Es berechnet das Ergebnis nur einmal und speichert es in einem sppol zwischen und gibt dieses Ergebnis dann wieder. Sie könnten Folgendes versuchen, damit SQL Server die Unterabfrage als korreliert ansieht und für jede äußere Zeile neu ausgewertet werden muss.
UPDATE table1
SET table2Id = (SELECT TOP 1 table2Id
FROM table2
ORDER BY Newid(),
table1.table1Id)
Für mich ergibt das diesen Plan ohne die Spule.
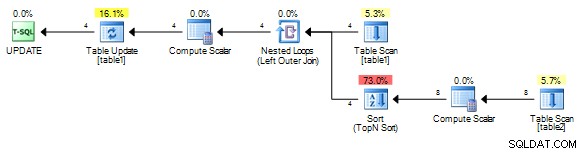
Es ist wichtig, mit einem eindeutigen Feld aus table1 zu korrelieren jedoch, selbst wenn eine Spule hinzugefügt wird, muss sie immer zurückgebunden und nicht zurückgespult werden (Wiedergabe des letzten Ergebnisses), da der Korrelationswert für jede Reihe unterschiedlich sein wird.
Wenn die Tabellen groß sind, wird dies langsam, da die erforderliche Arbeit ein Produkt der Zeilen der beiden Tabellen ist (für jede Zeile in table1 es muss einen vollständigen Scan von table2 durchführen )