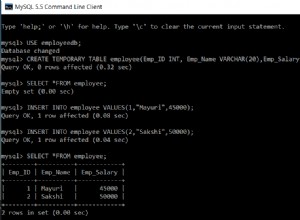
Sie können dies in SQL Fiddle sehen:https://sqlfiddle.com/#!3/ 8c3ee/32
Hier ist das Wesentliche:
with parsed as (
select
commasepa,
root.value('(/root/s/col[@name="X"])[1]', 'varchar(20)') as X,
root.value('(/root/s/col[@name="Y"])[1]', 'varchar(20)') as Y,
root.value('(/root/s/col[@name="Z"])[1]', 'varchar(20)') as Z,
root.value('(/root/s/col[@name="A"])[1]', 'varchar(20)') as A,
root.value('(/root/s/col[@name="B"])[1]', 'varchar(20)') as B,
root.value('(/root/s/col[@name="C"])[1]', 'varchar(20)') as C,
root.value('(/root/s/col[@name="D"])[1]', 'varchar(20)') as D
FROM
(
select
commasepa,
CONVERT(xml,'<root><s><col name="' + REPLACE(REPLACE(COMMASEPA, '=', '">'),',','</col></s><s><col name="') + '</col></s></root>') as root
FROM
samp
) xml
)
update
samp
set
samp.x = parsed.x,
samp.y = parsed.y,
samp.z = parsed.z,
samp.a = parsed.a,
samp.b = parsed.b,
samp.c = parsed.c,
samp.d = parsed.d
from
parsed
where
parsed.commasepa = samp.commasepa;
Vollständige Offenlegung – Ich bin der Autor von sqlfiddle.com
Dies funktioniert, indem zuerst jeder Kommasepa-String in ein XML-Objekt umgewandelt wird, das wie folgt aussieht:
<root>
<s>
<col name="X">1</col>
</s>
<s>
<col name="Y">2</col>
</s>
....
</root>
Sobald ich die Zeichenfolge in diesem Format habe, verwende ich die xquery-Optionen, die SQL Server 2005 (und höher) unterstützt, nämlich .value('(/root/s/col[@name="X"])[1]', 'varchar(20)') Teil. Ich wähle jede der potenziellen Spalten einzeln aus, sodass sie normalisiert und gefüllt werden, wenn sie verfügbar sind. Mit diesem normalisierten Format definiere ich die Ergebnismenge mit einem Common Table Expression (CTE), den ich „parsed“ genannt habe. Dieser CTE wird dann wieder in die Update-Anweisung eingefügt, sodass die Werte in die ursprüngliche Tabelle eingetragen werden können.