Zusammenfassung:
Ich habe jede Abfrage 10 Mal ausgeführt, wobei ich den folgenden Testdatensatz verwendet habe..
- Eine sehr große Unterabfrage-Ergebnismenge (100000 Zeilen)
- Doppelte Zeilen
- Nullzeilen
Für alle oben genannten Szenarien sind beide IN und EXISTS in identischer Weise durchgeführt.
Einige Informationen über die Performance V3-Datenbank zum Testen verwendet. 20000 Kunden mit 1000000 Bestellungen, daher wird jeder Kunde zufällig (in einem Bereich von 10 bis 100) in der Bestelltabelle dupliziert.
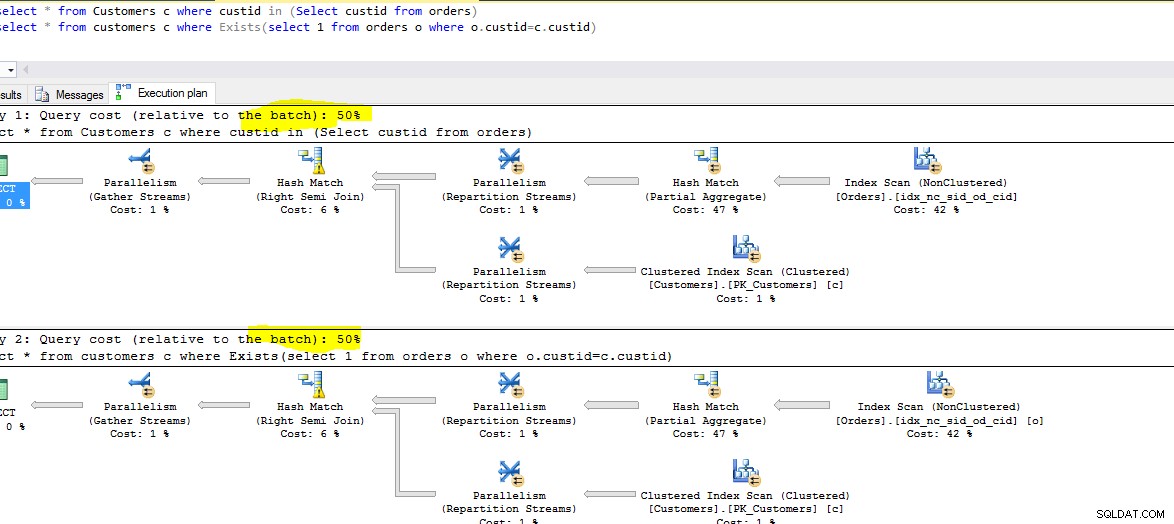
Ausführungskosten, Zeit:
Unten ist ein Screenshot von beiden ausgeführten Abfragen. Beobachten Sie die relativen Kosten jeder Abfrage.
Speicherkosten:
Die Speicherzuweisung für die beiden Abfragen ist ebenfalls gleich.. Ich habe MDOP 1 erzwungen, um sie nicht an TEMPDB zu übergeben..
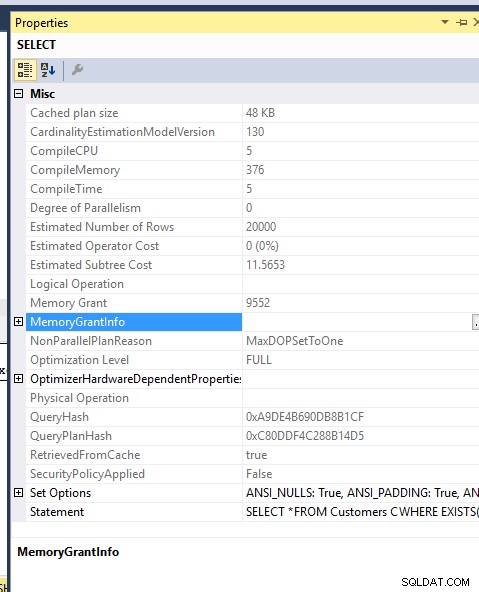
CPU-Zeit, liest:
Für Existiert:
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 469 ms, elapsed time = 595 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Für EIN:
(20000 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 547 ms, elapsed time = 669 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
In jedem Fall ist der Optimierer schlau genug, die Abfragen neu anzuordnen.
Ich neige dazu, EXISTS zu verwenden nur obwohl (meine meinung). Ein Anwendungsfall zur Verwendung von EXISTS ist, wenn Sie keine zweite Tabellenergebnismenge zurückgeben möchten.
Aktualisierung gemäß Anfragen von Martin Smith:
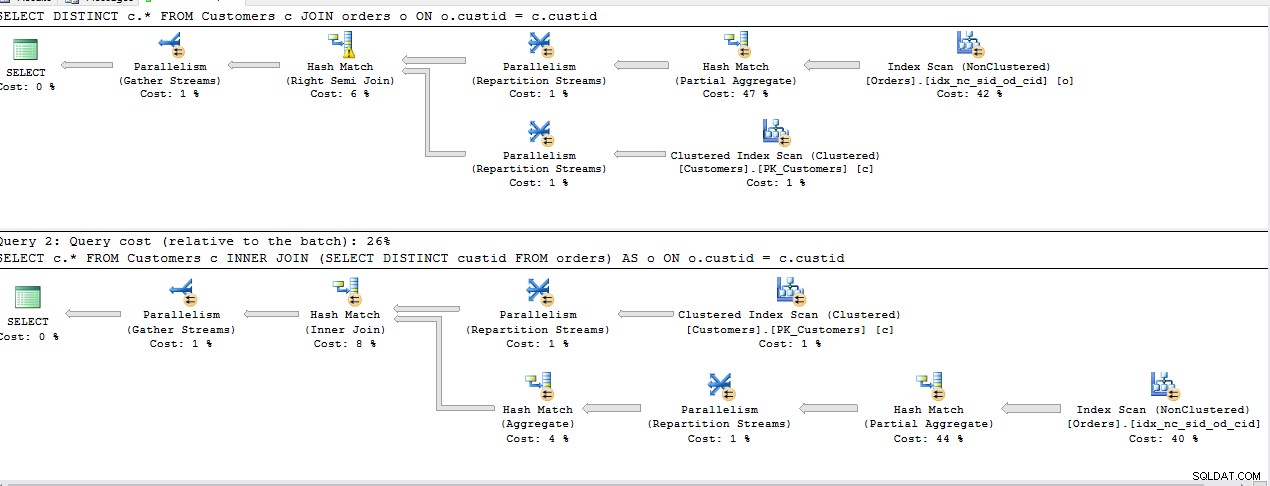
Ich habe die folgenden Abfragen ausgeführt, um den effektivsten Weg zu finden, Zeilen aus der ersten Tabelle zu erhalten, für die in der zweiten Tabelle eine Referenz vorhanden ist.
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
SELECT *
FROM Customers C
WHERE EXISTS(SELECT 1 FROM Orders o WHERE o.custid = c.custid)
SELECT *
FROM Customers c
WHERE custid IN (SELECT custid FROM Orders)
Alle obigen Abfragen teilen sich die gleichen Kosten mit Ausnahme von 2nd INNER JOIN , Planen Sie für den Rest dasselbe.
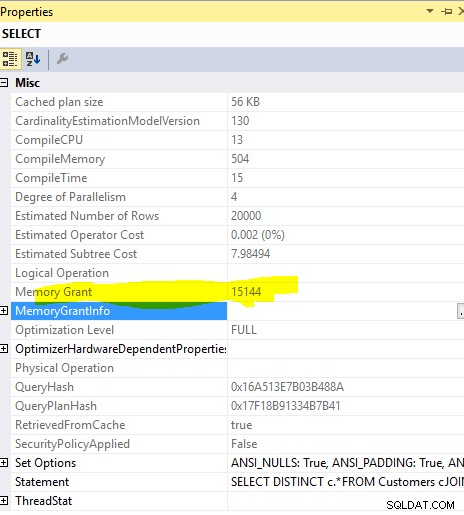
Speicherzuschuss:
Diese Abfrage
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
erforderliche Speicherzuweisung von
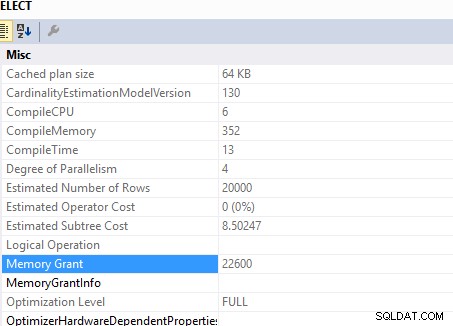
Diese Abfrage
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
erforderliche Speicherzuteilung von ..
CPU-Zeit, liest:
Für Abfrage:
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 48, logical reads 1344, physical reads 96, read-ahead reads 1248, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms, elapsed time = 781 ms.
Für Abfrage:
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1499 ms, elapsed time = 403 ms.