Dies ist ein recht häufiges Problem.
Einfacher B-Tree Indizes sind nicht gut für Abfragen wie diese:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
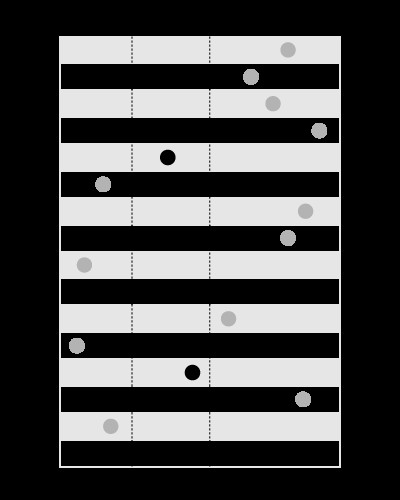
Ein Index eignet sich gut zum Suchen der Werte innerhalb der angegebenen Grenzen, etwa so:
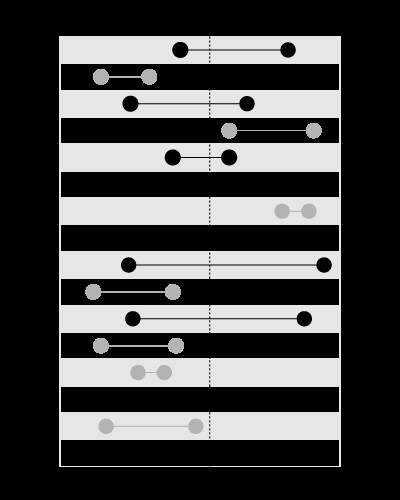
, aber nicht zum Suchen der Grenzen, die den angegebenen Wert enthalten, wie hier:
Dieser Artikel in meinem Blog erklärt das Problem genauer:
(Das Modell der verschachtelten Mengen befasst sich mit dem ähnlichen Typ von Prädikat).
Sie können den Index zum time erstellen , auf diese Weise die intervals in der Verknüpfung führen wird, wird die Bereichszeit innerhalb der verschachtelten Schleifen verwendet. Dies erfordert eine Sortierung zur time .
Sie können einen räumlichen Index für intervals erstellen (verfügbar in MySQL mit MyISAM storage), die start enthalten würde und end in einer Geometriespalte. Auf diese Weise measures kann im Join führen und es ist keine Sortierung erforderlich.
Die räumlichen Indizes sind jedoch langsamer, daher ist dies nur effizient, wenn Sie wenige Takte, aber viele Intervalle haben.
Da Sie nur wenige Intervalle, aber viele Takte haben, stellen Sie einfach sicher, dass Sie einen Index für measures.time haben :
CREATE INDEX ix_measures_time ON measures (time)
Aktualisierung:
Hier ist ein Beispielskript zum Testen:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Diese Abfrage:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
verwendet NESTED LOOPS und kehrt in 1.7 zurück Sekunden.
Diese Abfrage:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
verwendet MERGE JOIN und ich musste es nach 5 stoppen Minuten.
Aktualisierung 2:
Höchstwahrscheinlich müssen Sie die Engine zwingen, die richtige Tabellenreihenfolge im Join zu verwenden, indem Sie einen Hinweis wie diesen verwenden:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Das Oracle Der Optimierer von ist nicht schlau genug, um zu sehen, dass sich die Intervalle nicht schneiden. Deshalb wird es höchstwahrscheinlich measures verwenden als führende Tabelle (was eine kluge Entscheidung wäre, wenn sich die Intervalle schneiden).
Aktualisierung 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Diese Abfrage teilt die Zeitachse in die Bereiche auf und verwendet einen HASH JOIN um die Maße und Zeitstempel auf den Bereichswerten zu verbinden, mit späterer Feinfilterung.
In diesem Artikel in meinem Blog finden Sie ausführlichere Erklärungen zur Funktionsweise: