Sie können in Ihrer Analysefunktion viele Bedingungen angeben, nach denen sortiert werden soll
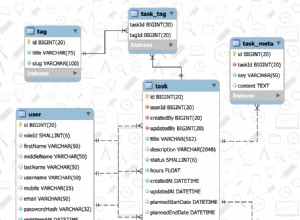
SELECT *
FROM (SELECT id,
col1,
col2,
col3,
dense_rank() over (partition by id
order by (case when col1 = 'xyz'
then 1
else 0
end) desc,
col2 asc,
col3 asc) rnk
FROM your_table)
WHERE rnk = 1
Ich gehe davon aus, dass Sie dense_rank wollen vorausgesetzt, Sie haben den dense_rank verwendet Schild. Sie sprechen nicht darüber, wie Sie mit Unentschieden umgehen möchten oder ob Unentschieden überhaupt möglich sind, daher geht aus der Frage selbst nicht hervor, ob Sie den rank verwenden möchten , dense_rank , oder row_number analytische Funktionen. Wenn Sie immer nur die Zeile mit dem höchsten Rang pro id abrufen , rank und dense_rank verhält sich identisch und gibt mehrere Zeilen zurück, wenn es Unentschieden für den ersten Platz gibt. row_number wird immer eine einzelne Zeile zurückgeben, indem die Bindung willkürlich gebrochen wird. Wenn Sie andere Zeilen als die erste Zeile pro id abrufen möchten , dann müssen Sie über Bindungen nachdenken und Sie werden ein anderes Verhalten von rank erhalten und dense_rank . Wenn zwei Zeilen für die erste gleich sind, dense_rank weist der dritten Zeile einen rnk zu von 2 während rank weist ihm einen rnk zu von 3.
Dies scheint für die von Ihnen geposteten Beispieldaten zu funktionieren
SQL> ed
Wrote file afiedt.buf
1 with x as (
2 select 1 id, 'abc' col1, to_date('01/01/2012', 'MM/DD/YYYY') col2, null col3 from dual union all
3 select 1 id, 'abc' col1, to_date('01/01/2012', 'MM/DD/YYYY') col2, 'A' col3 from dual union all
4 select 2 id, 'abc' col1, to_date('01/01/2012', 'MM/DD/YYYY') col2, null col3 from dual union all
5 select 2 id, 'abc' col1, to_date('01/02/2012', 'MM/DD/YYYY') col2, null col3 from dual union all
6 select 3 id, 'abc' col1, to_date('01/02/2012', 'MM/DD/YYYY') col2, null col3 from dual union all
7 select 3 id, 'xyz' col1, to_date('01/01/2012', 'MM/DD/YYYY') col2, null col3 from dual union all
8 select 4 id, 'abc' col1, to_date('01/02/2012', 'MM/DD/YYYY') col2, null col3 from dual union all
9 select 4 id, 'xyz' col1, to_date('01/01/2012', 'MM/DD/YYYY') col2, null col3 from dual union all
10 select 4 id, 'xyz' col1, to_date('01/02/2012', 'MM/DD/YYYY') col2, null col3 from dual
11 )
12 SELECT *
13 FROM (SELECT id,
14 col1,
15 col2,
16 col3,
17 dense_rank() over (partition by id
18 order by (case when col1 = 'xyz'
19 then 1
20 else 0
21 end) desc,
22 col2 asc,
23 col3 asc) rnk
24 FROM x)
25* WHERE rnk = 1
SQL> /
ID COL COL2 C RNK
---------- --- --------- - ----------
1 abc 01-JAN-12 A 1
2 abc 01-JAN-12 1
3 xyz 01-JAN-12 1
4 xyz 01-JAN-12 1