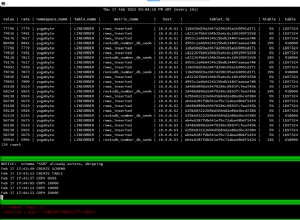
Sie können versuchen, WIDTH_BUCKET zu verwenden Funktion.
select bucket , count(name)
from (select name, spend,
WIDTH_BUCKET(spend, 0, 200, 4) bucket
from mytable
)
group by bucket
order by bucket;
Hier habe ich den Bereich 0 bis 200 in 4 Buckets unterteilt. Und die Funktion weist jedem Wert eine Bucket-Nummer zu. Sie können nach diesem Bucket gruppieren und zählen, wie viele Datensätze in jeden Bucket fallen.
Demo hier .
Sie können sogar die tatsächliche Bucket-Reichweite anzeigen.
select bucket,
cast(min_value + ((bucket-1) * (max_value-min_value)/buckets) as varchar2(10))
||'-'
||cast(min_value + ((bucket) * (max_value-min_value)/buckets) as varchar2(10)),
count(name) c
from (select name,
spend,
WIDTH_BUCKET(spend, min_value, max_value, buckets) bucket
from mytable)
group by bucket
order by bucket;
Beispiel hier .