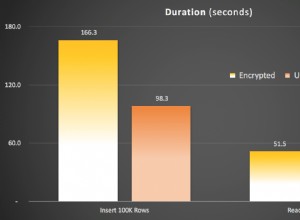
Nur Minuten mit Aktivität zurückgeben
Am kürzesten
SELECT DISTINCT
date_trunc('minute', "when") AS minute
, count(*) OVER (ORDER BY date_trunc('minute', "when")) AS running_ct
FROM mytable
ORDER BY 1;
Verwenden Sie date_trunc() , gibt es genau das zurück, was Sie brauchen.
Geben Sie id nicht ein in der Abfrage, da Sie GROUP BY möchten winzige Scheiben.
count() wird typischerweise als einfache Aggregatfunktion verwendet. Anhängen eines OVER -Klausel macht es zu einer Fensterfunktion. Lassen Sie PARTITION BY weg in der Fensterdefinition - Sie möchten eine laufende Zählung über alle Zeilen . Standardmäßig zählt dies von der ersten Zeile bis zum letzten Peer der aktuellen Zeile, wie durch ORDER BY definiert . Das Handbuch:
Die standardmäßige Framing-Option ist RANGE UNBOUNDED PRECEDING , was dasselbe ist wie RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW . Mit ORDER BY , setzt dies den Rahmen auf alle Zeilen vom Beginn der Partition bis zur letzten ORDER BY der aktuellen Zeile Peer.
Und das ist genau der Fall was Sie brauchen.
Verwenden Sie count(*) statt count(id) . Es passt besser zu Ihrer Frage ("Anzahl der Zeilen"). Es ist im Allgemeinen etwas schneller als count(id) . Und obwohl wir davon ausgehen könnten, dass id ist NOT NULL , wurde in der Frage nicht angegeben, also count(id) ist falsch , genau genommen, weil NULL-Werte nicht mit count(id) gezählt werden .
Sie können nicht GROUP BY winzige Scheiben auf der gleichen Abfrageebene. Aggregatfunktionen werden vorher angewendet Fensterfunktionen, die Fensterfunktion count(*) würde auf diese Weise nur 1 Zeile pro Minute sehen.
Sie können jedoch SELECT DISTINCT , weil DISTINCT wird nach angewendet Fensterfunktionen.
ORDER BY 1 ist nur eine Abkürzung für ORDER BY date_trunc('minute', "when") hier.1 ist eine Positionsreferenz Referenz auf den 1. Ausdruck im SELECT Liste.
Verwenden Sie to_char() wenn Sie das Ergebnis formatieren müssen. Wie:
SELECT DISTINCT
to_char(date_trunc('minute', "when"), 'DD.MM.YYYY HH24:MI') AS minute
, count(*) OVER (ORDER BY date_trunc('minute', "when")) AS running_ct
FROM mytable
ORDER BY date_trunc('minute', "when");
Am schnellsten
SELECT minute, sum(minute_ct) OVER (ORDER BY minute) AS running_ct
FROM (
SELECT date_trunc('minute', "when") AS minute
, count(*) AS minute_ct
FROM tbl
GROUP BY 1
) sub
ORDER BY 1;
Ähnlich wie oben, aber:
Ich verwende eine Unterabfrage, um Zeilen pro Minute zu aggregieren und zu zählen. Auf diese Weise erhalten wir 1 Zeile pro Minute ohne DISTINCT im äußeren SELECT .
Verwenden Sie sum() als Fenster-Aggregatfunktion, um nun die Zählungen aus der Unterabfrage zu addieren.
Ich habe festgestellt, dass dies mit vielen Zeilen pro Minute wesentlich schneller ist.
Minuten ohne Aktivität einbeziehen
Am kürzesten
@GabiMe fragte in einem Kommentar, wie man eine Zeile für jeden bekommt minute im Zeitraum, einschließlich derjenigen, in denen kein Ereignis aufgetreten ist (keine Zeile in der Basistabelle):
SELECT DISTINCT
minute, count(c.minute) OVER (ORDER BY minute) AS running_ct
FROM (
SELECT generate_series(date_trunc('minute', min("when"))
, max("when")
, interval '1 min')
FROM tbl
) m(minute)
LEFT JOIN (SELECT date_trunc('minute', "when") FROM tbl) c(minute) USING (minute)
ORDER BY 1;
Generieren Sie mit generate_series() für jede Minute im Zeitraum zwischen dem ersten und dem letzten Ereignis eine Zeile - hier direkt basierend auf aggregierten Werten aus der Subquery.
LEFT JOIN zu allen Zeitstempeln auf die Minute gekürzt und zählen. NULL Werte (wo keine Zeile vorhanden ist) werden nicht zur laufenden Zählung hinzugefügt.
Am schnellsten
Mit CTE:
WITH cte AS (
SELECT date_trunc('minute', "when") AS minute, count(*) AS minute_ct
FROM tbl
GROUP BY 1
)
SELECT m.minute
, COALESCE(sum(cte.minute_ct) OVER (ORDER BY m.minute), 0) AS running_ct
FROM (
SELECT generate_series(min(minute), max(minute), interval '1 min')
FROM cte
) m(minute)
LEFT JOIN cte USING (minute)
ORDER BY 1;
Auch hier aggregieren und zählen Sie im ersten Schritt Zeilen pro Minute, dadurch entfällt die Notwendigkeit für späteres DISTINCT .
Anders als count() , sum() kann NULL zurückgeben . Standardmäßig 0 mit COALESCE .
Mit vielen Zeilen und einem Index auf "when" Diese Version mit einer Unterabfrage war die schnellste unter einigen Varianten, die ich mit Postgres 9.1 - 9.4 getestet habe:
SELECT m.minute
, COALESCE(sum(c.minute_ct) OVER (ORDER BY m.minute), 0) AS running_ct
FROM (
SELECT generate_series(date_trunc('minute', min("when"))
, max("when")
, interval '1 min')
FROM tbl
) m(minute)
LEFT JOIN (
SELECT date_trunc('minute', "when") AS minute
, count(*) AS minute_ct
FROM tbl
GROUP BY 1
) c USING (minute)
ORDER BY 1;