Wenn Ihr System auf PostgreSQL basiert und Sie nach Clustering-Lösungen für Hochverfügbarkeit suchen, möchten wir Sie im Voraus darüber informieren, dass dies eine komplexe Aufgabe ist, aber nicht unmöglich zu erreichen.
In Anbetracht Ihrer Anforderungen an die Fehlertoleranz finden Sie hier einige Hochverfügbarkeits-Clustering-Lösungen zur Auswahl, die hilfreich sein können.
PostgreSQL unterstützt nativ keine Multi-Master-Clustering-Lösung wie MySQL oder Oracle. Dennoch bieten viele kommerzielle und Community-Produkte diese Implementierung an, einschließlich Replikation und Lastenausgleich für PostgreSQL.
Lassen Sie uns zunächst einige grundlegende Konzepte wiederholen:
Was ist Hochverfügbarkeit?
Hohe Verfügbarkeit bezieht sich auf die Zeitspanne, während der ein Dienst verfügbar ist, und wird normalerweise durch das vereinbarte Leistungsniveau eines Unternehmens definiert.
Redundanz ist die Basis für Hochverfügbarkeit; Im Falle eines Vorfalls können Sie die Systeme problemlos weiter betreiben und darauf zugreifen.
Kontinuierliche Wiederherstellung
Wenn Sie bei einem Vorfall eine Sicherung wiederherstellen und dann die WAL-Protokolle (Write-Ahead Logging) anwenden müssen, wäre die Wiederherstellungszeit sehr lang und die Verfügbarkeit nicht hoch.
Wenn Sie die Sicherungen und Protokolle jedoch auf einem Notfallserver archiviert haben, können Sie die Protokolle anwenden, sobald sie eintreffen. Wenn die Protokolle jede Minute gesendet und angewendet werden, befindet sich die Notfallbasis in einer kontinuierlichen Wiederherstellung und hat einen veralteten Status für die Produktion von höchstens einer Minute.
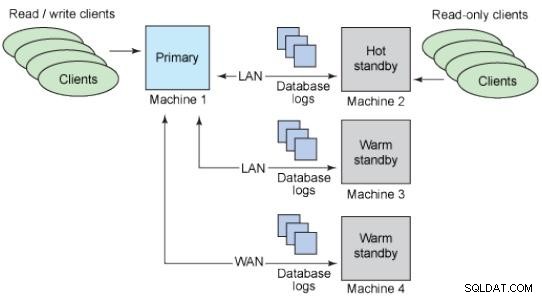
Standby-Datenbanken
Die Idee einer Standby-Datenbank besteht darin, eine Kopie einer Produktionsdatenbank aufzubewahren, die immer dieselben Daten enthält und im Falle eines Vorfalls verwendet werden kann.
Es gibt mehrere Möglichkeiten, eine Standby-Datenbank zu klassifizieren.
Durch die Art der Replikation:
-
Physical standbys:Plattenblöcke werden kopiert.
-
Logische Standbys:Streaming der Datenänderungen.
Durch die Synchronität der Transaktionen:
-
Asynchron:Es besteht die Möglichkeit von Datenverlust.
-
Synchron:Kein Datenverlust möglich; Die Commits im Master warten auf die Antwort des Standby.
Durch die Verwendung:
-
Warme Standbys:Sie unterstützen keine Verbindungen.
-
Hot Standbys:Unterstützt schreibgeschützte Verbindungen.
Cluster
Ein Cluster ist eine Gruppe von Hosts, die zusammenarbeiten und als Einheit betrachtet werden. Dies bietet eine Möglichkeit, horizontale Skalierbarkeit zu erreichen und durch Hinzufügen von Servern mehr Arbeit zu verarbeiten.
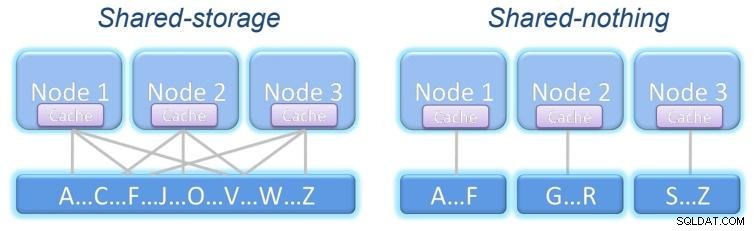
Es kann dem Ausfall eines Knotens widerstehen und transparent weiterarbeiten. Je nachdem, was geteilt wird, gibt es zwei Cluster-Modelle:
-
Gemeinsamer Speicher:Alle Knoten greifen auf denselben Speicher mit denselben Informationen zu.
-
Geteiltes Nichts:Jeder Knoten hat seinen eigenen Speicher, der die gleichen Informationen wie der andere haben kann oder nicht Knoten, abhängig von der Struktur unseres Systems.
Sehen wir uns nun einige der Clustering-Optionen an, die wir in PostgreSQL haben.
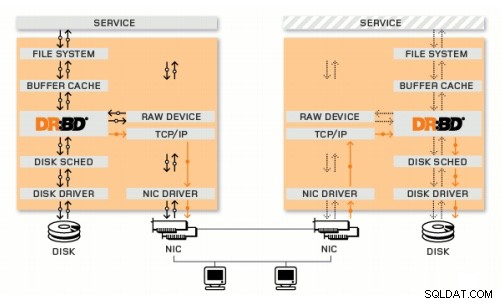
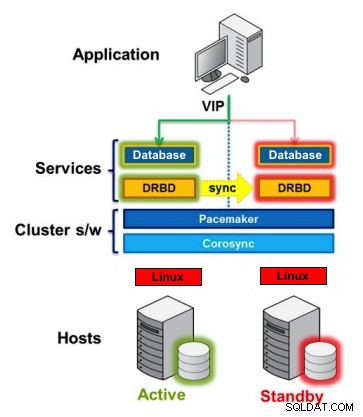
Verteiltes repliziertes Blockgerät
DRBD ist ein Linux-Kernelmodul, das die synchrone Blockreplikation über das Netzwerk implementiert. Es implementiert tatsächlich keinen Cluster und behandelt kein Failover oder Monitoring. Dazu benötigen Sie ergänzende Software, z. B. Corosync + Pacemaker + DRBD.
Beispiel:
-
Corosync:Verarbeitet Nachrichten zwischen Hosts.
-
Pacemaker:Startet und stoppt Dienste und stellt sicher, dass sie nur auf einem Host laufen.
-
DRBD:Synchronisiert die Daten auf der Ebene der Blockgeräte.
ClusterControl
ClusterControl ist eine agentenlose Verwaltungs- und Automatisierungssoftware für Datenbank-Cluster. Es hilft bei der Bereitstellung, Überwachung, Verwaltung und Skalierung Ihres Datenbankservers/Clusters direkt über seine Benutzeroberfläche. Es kann die meisten Verwaltungsaufgaben erledigen, die für die Wartung von Datenbankservern oder Clustern erforderlich sind.
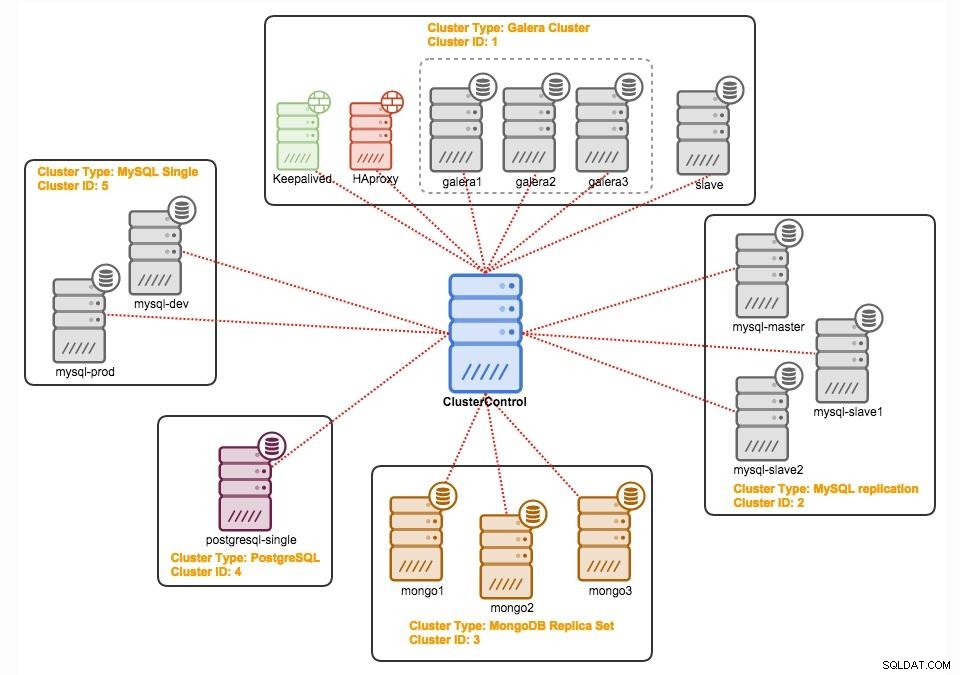
Mit ClusterControl können Sie:
-
Stellen Sie eigenständige, replizierte oder geclusterte Datenbanken auf dem Technologie-Stack Ihrer Wahl bereit.
-
Automatisieren Sie Failover, Wiederherstellung und alltägliche Aufgaben einheitlich über mehrsprachige Datenbanken und dynamische Infrastrukturen hinweg.
-
Erstellen Sie vollständige oder inkrementelle Sicherungen manuell oder planen Sie sie.
-
Führen Sie eine einheitliche und umfassende Echtzeitüberwachung Ihrer gesamten Datenbank- und Serverinfrastruktur durch.
-
Einfach einen Knoten mit einer einzigen Aktion hinzufügen oder entfernen.
-
Klonen Sie Ihren Cluster zu einem anderen Rechenzentrum/Cloud-Anbieter
Wenn Sie einen Vorfall auf PostgreSQL haben, kann Ihr Standby-Knoten automatisch zum Primärknoten heraufgestuft werden.
Es ist ein vollständiges Tool, das umfassende Lebenszyklusverwaltung und -automatisierung über eine einzige Konsole bietet. ClusterControl bietet auch eine kostenlose 30-Tage-Testversion, damit Sie es unverbindlich testen können.
Rubyrep
Rubyrep ist eine Lösung, die asynchrone, Multi-Master-, Multi-Plattform-Replikation (implementiert in Ruby oder JRuby) und Multi-DBMS (MySQL oder PostgreSQL) bereitstellt.
Es basiert auf Auslösern und unterstützt keine DDL, Benutzer oder Berechtigungen. Die Einfachheit der Verwendung und Verwaltung ist sein Hauptziel.
Einige Funktionen beinhalten:
-
Einfache Konfiguration
-
Einfache Installation
-
Plattformunabhängig, Tabellendesign unabhängig.
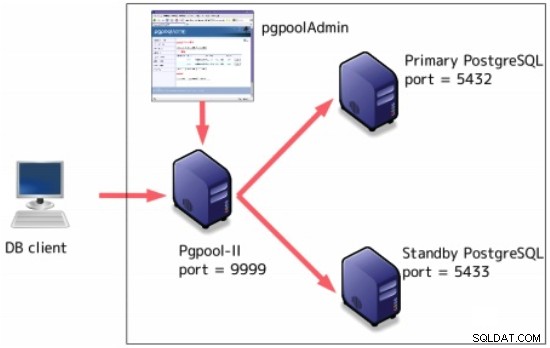
Pgpool-II
Pgpool-II ist eine Middleware, die zwischen PostgreSQL-Servern und einem PostgreSQL-Datenbankclient funktioniert.
Einige Funktionen beinhalten:
-
Verbindungspool
-
Replikation
-
Lastenausgleich
-
Automatisches Failover
-
Parallele Abfragen
Es kann zusätzlich zur Streaming-Replikation konfiguriert werden:
Bucardo
Bucardo bietet asynchrone, kaskadierende Master-Slave-Replikation, zeilenbasiert, unter Verwendung von Triggern und Warteschlangen in der Datenbank, und asynchrone Master-Master-Replikation, zeilenbasiert, unter Verwendung von Triggern und angepasster Konfliktlösung.
Bucardo benötigt eine dedizierte Datenbank und läuft als Perl-Daemon, der mit dieser Datenbank und allen anderen an der Replikation beteiligten Datenbanken kommuniziert. Es kann als Multi-Master oder Multi-Slave laufen.
Master-Slave-Replikation beinhaltet eine oder mehrere Quellen, die zu einem oder mehreren Zielen gehen. Die Quelle muss PostgreSQL sein, aber die Ziele können PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite oder MongoDB sein.
Einige Funktionen beinhalten:
-
Lastenausgleich
-
Slaves sind nicht eingeschränkt und können geschrieben werden
-
Teilweise Replikation
-
Replizierung nach Bedarf (Änderungen können automatisch oder bei Bedarf übertragen werden)
-
Slaves können für eine schnelle Einrichtung "vorgewärmt" werden
Nachteile:
-
Kann DDL nicht verarbeiten
-
Kann keine großen Objekte verarbeiten
-
Tabellen können ohne einen eindeutigen Schlüssel nicht inkrementell repliziert werden
-
Funktioniert nicht mit älteren Versionen als Postgres 8
Postgres-XC
Postgres-XC ist ein Open-Source-Projekt zur Bereitstellung einer schreibskalierbaren, synchronen, symmetrischen und transparenten PostgreSQL-Clusterlösung. Es ist eine Sammlung eng gekoppelter Datenbankkomponenten, die auf mehr als einer Hardware oder virtuellen Maschine installiert werden können.
Write-scalable bedeutet, dass Postgres-XC mit beliebig vielen Datenbankservern konfiguriert werden kann und viel mehr Schreibvorgänge (Aktualisierung von SQL-Anweisungen) verarbeiten kann als ein einzelner Datenbankserver.
Sie können mehr als einen Datenbankserver haben, mit dem sich Clients verbinden, wodurch eine einzelne, konsistente, clusterweite Ansicht der Datenbank bereitgestellt wird.
Jede Datenbankaktualisierung von jedem Datenbankserver ist sofort für alle anderen Transaktionen sichtbar, die auf anderen Mastern laufen.
Transparent bedeutet, dass Sie sich keine Gedanken darüber machen müssen, wie Ihre Daten intern auf mehr als einem Datenbankserver gespeichert werden.
Sie können Postgres-XC so konfigurieren, dass es auf mehreren Servern ausgeführt wird. Ihre Daten werden verteilt gespeichert, partitioniert oder repliziert, wie Sie es für jede Tabelle auswählen. Wenn Sie Abfragen stellen, ermittelt Postgres-XC, wo die Zieldaten gespeichert sind, und sendet entsprechende Abfragen an Server, die die Zieldaten enthalten.
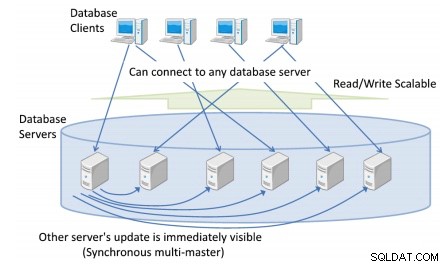
Citus
Citus ist ein Drop-in-Ersatz für PostgreSQL mit integrierten Hochverfügbarkeitsfunktionen wie Auto-Sharding und Replikation. Citus fragmentiert Ihre Datenbank und repliziert mehrere Kopien jedes Shards über den Cluster von Commodity-Knoten. Wenn ein Knoten im Cluster nicht mehr verfügbar ist, leitet Citus alle Schreibvorgänge oder Abfragen transparent an einen der anderen Knoten um, die eine Kopie des betroffenen Shards enthalten.
Einige Funktionen beinhalten:
-
Automatisches logisches Sharding
-
Integrierte Replikation
-
Rechenzentrumsbewusste Replikation für Notfallwiederherstellung
-
Fehlertoleranz in der Mitte der Abfrage mit erweitertem Lastenausgleich
Sie können die Betriebszeit Ihrer von PostgreSQL unterstützten Echtzeitanwendungen erhöhen und die Auswirkungen von Hardwareausfällen auf die Leistung minimieren. Sie können dies mit integrierten Hochverfügbarkeitstools erreichen, die kostspielige und fehleranfällige manuelle Eingriffe minimieren.
PostgresXL
PostgresXL ist eine Shared-Nothing-Multi-Master-Clustering-Lösung, die eine Tabelle transparent auf eine Reihe von Knoten verteilen und Abfragen parallel zu diesen Knoten ausführen kann. Es verfügt über eine zusätzliche Komponente namens Global Transaction Manager (GTM), um eine global konsistente Ansicht des Clusters bereitzustellen.
PostgresXL ist ein horizontal skalierbarer Open-Source-SQL-Datenbankcluster, der flexibel genug ist, um unterschiedliche Datenbank-Workloads zu bewältigen:
-
OLTP-schreibintensive Workloads
-
Business Intelligence erfordert MPP-Parallelität
-
Betriebsdatenspeicher
-
Schlüsselwertspeicher
-
GIS Geospatial
-
Umgebungen mit gemischter Arbeitslast
-
Mandantenfähige, vom Anbieter gehostete Umgebungen

Komponenten:
-
Global Transaction Monitor (GTM):Der Global Transaction Monitor stellt eine clusterweite Transaktionskonsistenz sicher.
-
Koordinator:Der Koordinator verwaltet die Benutzersitzungen und interagiert mit GTM und den Datenknoten.
-
Datenknoten:Im Datenknoten werden die eigentlichen Daten gespeichert.
Abschluss
Es sind viele weitere Produkte verfügbar, um Ihre Hochverfügbarkeitsumgebung für PostgreSQL zu implementieren, aber Sie müssen vorsichtig sein mit:
-
Neue Produkte, nicht ausreichend getestet
-
Eingestellte Projekte
-
Einschränkungen
-
Lizenzkosten
-
Sehr komplexe Implementierungen
-
Unsichere Lösungen
Berücksichtigen Sie bei der Auswahl Ihrer Lösung auch Ihre Infrastruktur. Wenn Sie nur einen Anwendungsserver haben, egal wie sehr Sie die Hochverfügbarkeit der Datenbanken konfiguriert haben, wenn der Anwendungsserver ausfällt, sind Sie nicht erreichbar. Sie müssen die Single Points of Failure in der Infrastruktur gut analysieren und versuchen, sie zu lösen.
Unter Berücksichtigung dieser Punkte finden Sie problemlos eine hochverfügbare Cluster-Lösung, die sich Ihren Bedürfnissen und Anforderungen anpasst. Wenn Sie nach zusätzlichen HA-Ressourcen für Ihre PG-Datenbank suchen, sehen Sie sich diesen Beitrag zur Bereitstellung von PostgreSQL für Hochverfügbarkeit an.
Um über Datenbankverwaltungslösungen und Best Practices auf dem Laufenden zu bleiben, folgen Sie uns auf Twitter und LinkedIn und abonnieren Sie unseren Newsletter.