Dieser Blog startet eine Multiserie, die meinen Weg zum Benchmarking von PostgreSQL in der Cloud dokumentiert.
Der erste Teil enthält einen Überblick über Benchmarking-Tools und bringt den Spaß mit Amazon Aurora PostgreSQL in Schwung.
Auswahl der PostgreSQL-Cloud-Dienstanbieter
Vor einiger Zeit bin ich auf das AWS-Benchmark-Verfahren für Aurora gestoßen und dachte, es wäre wirklich cool, wenn ich diesen Test machen und auf anderen Cloud-Hosting-Anbietern ausführen könnte. Von den drei bekanntesten Utility-Computing-Anbietern – AWS, Google und Microsoft – ist Amazon der einzige große Beitrag zur Entwicklung von PostgreSQL und der erste, der verwaltete PostgreSQL-Dienste anbietet (seit November 2013).
Während verwaltete PostgreSQL-Dienste auch von einer Vielzahl von PostgreSQL-Hostinganbietern verfügbar sind, wollte ich mich auf die genannten drei Cloud-Computing-Anbieter konzentrieren, da in ihren Umgebungen viele Unternehmen, die nach den Vorteilen des Cloud-Computing suchen, ihre Anwendungen ausführen, sofern dies der Fall ist das erforderliche Know-how zur Verwaltung von PostgreSQL. Ich bin fest davon überzeugt, dass in der heutigen IT-Landschaft Organisationen, die mit kritischen Workloads in der Cloud arbeiten, stark von den Diensten eines spezialisierten PostgreSQL-Dienstleisters profitieren würden, der ihnen helfen kann, sich in der komplexen Welt von GUCS und unzähligen SlideShare-Präsentationen zurechtzufinden. P>
Auswahl des richtigen Benchmark-Tools
Benchmarking PostgreSQL taucht ziemlich oft auf der Performance-Mailingliste auf, und wie unzählige Male betont wurde, sind die Tests nicht dazu gedacht, eine Konfiguration für eine Anwendung im wirklichen Leben zu validieren. Die Auswahl des richtigen Benchmark-Tools und der richtigen Parameter ist jedoch wichtig, um aussagekräftige Ergebnisse zu erzielen. Ich würde erwarten, dass jeder Cloud-Anbieter Verfahren zum Benchmarking seiner Dienste bereitstellt, insbesondere wenn die erste Cloud-Erfahrung möglicherweise nicht auf dem richtigen Fuß beginnt. Die gute Nachricht ist, dass zwei der drei Spieler in diesem Test Benchmarks in ihre Dokumentation aufgenommen haben. Der Leitfaden zum AWS-Benchmark-Verfahren für Aurora ist leicht zu finden und direkt auf der Amazon Aurora-Ressourcenseite verfügbar. Google stellt keinen spezifischen Leitfaden für PostgreSQL bereit, die Compute Engine-Dokumentation enthält jedoch einen Lasttestleitfaden für SQL Server auf Basis von HammerDB.
Im Folgenden finden Sie eine Zusammenfassung von Benchmark-Tools, die aufgrund ihrer Referenzen einen Blick wert sind:
- Der oben erwähnte AWS-Benchmark basiert auf pgbench und sysbench.
- Der ebenfalls bereits erwähnte HammerDB wird in einem kürzlich erschienenen Beitrag auf der pgsql-hackers list diskutiert.
- TPC-C-Tests basierend auf oltpbench, wie in dieser anderen pgsql-Hacker-Diskussion angedeutet.
- benchmarksql ist ein weiterer TPC-C-Test, der verwendet wurde, um die Änderungen an B-Tree-Seitenaufteilungen zu validieren.
- pg_ycsb ist das neue Kind in der Stadt, das pgbench verbessert und bereits von einigen PostgreSQL-Hackern verwendet wird.
- pgbench-tools basiert, wie der Name schon sagt, auf pgbench und obwohl es seit 2016 keine Updates mehr erhalten hat, ist es das Produkt von Greg Smith, dem Autor von PostgreSQL High Performance-Büchern.
- Join-Order-Benchmark ist ein Benchmark, der den Abfrageoptimierer testet.
- pgreplay, auf das ich beim Lesen des Blogs zur Eingabeaufforderung gestoßen bin, kommt dem Benchmarking eines realen Szenarios so nahe, wie es nur sein kann.
Ein weiterer zu beachtender Punkt ist, dass PostgreSQL noch nicht gut für den TPC-H-Benchmark-Standard geeignet ist, und wie oben erwähnt, müssen alle Tools (außer pgreplay) im TPC-C-Modus ausgeführt werden (pgbench ist standardmäßig darauf eingestellt).
Für die Zwecke dieses Blogs dachte ich, dass das AWS-Benchmark-Verfahren für Aurora ein guter Anfang ist, einfach weil es einen Standard für Cloud-Anbieter setzt und auf weit verbreiteten Tools basiert.
Außerdem habe ich die damals neueste verfügbare PostgreSQL-Version verwendet. Bei der Auswahl eines Cloud-Anbieters ist es wichtig, die Häufigkeit von Upgrades zu berücksichtigen, insbesondere wenn wichtige Funktionen, die durch neue Versionen eingeführt werden, die Leistung beeinträchtigen können (was bei den Versionen 10 und 11 gegenüber 9 der Fall ist). Zum jetzigen Zeitpunkt haben wir:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS für PostgreSQL 10.6
- Google Cloud SQL für PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
... und der Gewinner hier ist AWS, indem es die neueste Version anbietet (obwohl es nicht die neueste ist, die zum jetzigen Zeitpunkt 11.2 ist).
Einrichten der Benchmarking-Umgebung
Ich habe mich aus mehreren Gründen entschieden, meine Tests auf durchschnittliche Workloads zu beschränken:Erstens sind die verfügbaren Cloud-Ressourcen nicht bei allen Anbietern identisch. Im Leitfaden lauten die AWS-Spezifikationen für die Datenbankinstanz 64 vCPU / 488 GiB RAM / 25 Gigabit-Netzwerk, während Googles maximaler RAM für jede Instanzgröße (die Auswahl muss im Google-Rechner auf „benutzerdefiniert“ eingestellt sein) 208 GiB beträgt. und Microsofts Business Critical Gen5 mit 32 vCPU kommt mit nur 163 GiB). Zweitens bringt die pgbench-Initialisierung die Datenbankgröße auf 160 GiB, was im Fall einer Instanz mit 488 GiB RAM wahrscheinlich im Arbeitsspeicher gespeichert wird.
Außerdem habe ich die PostgreSQL-Konfiguration unberührt gelassen. Der Grund für das Festhalten an den Vorgaben des Cloud-Anbieters liegt darin, dass von einem verwalteten Dienst erwartet wird, dass er standardmäßig recht gut abschneidet, wenn er durch einen Standard-Benchmark belastet wird. Denken Sie daran, dass die PostgreSQL-Community pgbench-Tests als Teil des Release-Management-Prozesses durchführt. Darüber hinaus erwähnt der AWS-Leitfaden keine Änderungen an der standardmäßigen PostgreSQL-Konfiguration.
Wie in der Anleitung erläutert, hat AWS zwei Patches auf pgbench angewendet. Da der Patch für die Anzahl der Clients auf der Version 10.6 von PostgreSQL nicht sauber angewendet wurde und ich keine Zeit in die Behebung investieren wollte, wurde die Anzahl der Clients auf maximal 1.000 begrenzt.
Der Leitfaden gibt an, dass für die Clientinstanz erweitertes Netzwerk aktiviert sein muss – für diesen Instanztyp ist dies die Standardeinstellung:
[example@sqldat.com ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff
inet 172.31.19.190/20 brd 172.31.31.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8cd:eeff:fe40:2be6/64 scope link
valid_lft forever preferred_lft forever
[example@sqldat.com ~]$ ethtool -i eth0
driver: ena
version: 2.0.2g
firmware-version:
bus-info: 0000:00:03.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
>>> aws (master *%) ~ $ aws ec2 describe-instances --instance-ids i-0ee51642334c1ec57 --query "Reservations[].Instances[].EnaSupport"
[
true
]Ausführen des Benchmarks auf Amazon Aurora PostgreSQL
Während des eigentlichen Laufs entschied ich mich, noch eine weitere Abweichung von der Anleitung zu machen:Statt den Test 1 Stunde lang laufen zu lassen, stellte ich das Zeitlimit auf 10 Minuten ein, was allgemein als guter Wert akzeptiert wird.
Lauf Nr. 1
Besonderheiten
- Dieser Test verwendet die AWS-Spezifikationen für Client- und Datenbank-Instance-Größen.
- Client-Rechner:On Demand Memory Optimized EC2-Instanz:
- vCPU:32 (16 Kerne x 2 Threads/Kern)
- RAM:244 GiB
- Speicher:EBS-optimiert
- Netzwerk:10 Gigabit
- DB-Cluster:db.r4.16xlarge
- vCPU:64
- ECU (CPU-Kapazität):195 x [1,0-1,2 GHz] 2007 Opteron / Xeon
- RAM:488 GiB
- Speicher:EBS-optimiert (dedizierte Kapazität für E/A)
- Netzwerk:14.000 Mbit/s maximale Bandbreite in einem 25-Gps-Netzwerk
- Client-Rechner:On Demand Memory Optimized EC2-Instanz:
- Das Datenbank-Setup beinhaltete ein Replikat.
- Datenbankspeicherung war nicht verschlüsselt.
Durchführung der Tests und Ergebnisse
- Folgen Sie den Anweisungen in der Anleitung, um pgbench und sysbench zu installieren.
- Bearbeiten Sie ~/.bashrc, um die Umgebungsvariablen für die Datenbankverbindung und die erforderlichen Pfade zu PostgreSQL-Bibliotheken festzulegen:
export PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com export PGUSER=postgres export PGPASSWORD=postgres export PGDATABASE=postgres export PATH=$PATH:/usr/local/pgsql/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Datenbank initialisieren:
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.05 s, remaining 457.23 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 631.70 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 688.29 s) ... 999500000 of 1000000000 tuples (99%) done (elapsed 811.41 s, remaining 0.41 s) 999600000 of 1000000000 tuples (99%) done (elapsed 811.50 s, remaining 0.32 s) 999700000 of 1000000000 tuples (99%) done (elapsed 811.58 s, remaining 0.24 s) 999800000 of 1000000000 tuples (99%) done (elapsed 811.65 s, remaining 0.16 s) 999900000 of 1000000000 tuples (99%) done (elapsed 811.73 s, remaining 0.08 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 811.80 s, remaining 0.00 s) vacuum... set primary keys... done. - Überprüfen Sie die Datenbankgröße:
postgres=> \l+ postgres List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description ----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------------------------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 160 GB | pg_default | default administrative connection database (1 row) - Verwenden Sie die folgende Abfrage, um zu überprüfen, ob das Zeitintervall zwischen Checkpoints so eingestellt ist, dass Checkpoints während des 10-minütigen Laufs erzwungen werden:
Ergebnis:SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpoints FROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutes_between_checkpoints -------------------+----------------------------- 50 | 0.977392292333333 (1 row) - Lesen/Schreiben-Workload ausführen:
Ausgabe[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048starting vacuum...end. progress: 60.0 s, 35670.3 tps, lat 27.243 ms stddev 10.915 progress: 120.0 s, 36569.5 tps, lat 27.352 ms stddev 11.859 progress: 180.0 s, 35845.2 tps, lat 27.896 ms stddev 12.785 progress: 240.0 s, 36613.7 tps, lat 27.310 ms stddev 11.804 progress: 300.0 s, 37323.4 tps, lat 26.793 ms stddev 11.376 progress: 360.0 s, 36828.8 tps, lat 27.155 ms stddev 11.318 progress: 420.0 s, 36670.7 tps, lat 27.268 ms stddev 12.083 progress: 480.0 s, 37176.1 tps, lat 26.899 ms stddev 10.981 progress: 540.0 s, 37210.8 tps, lat 26.875 ms stddev 11.341 progress: 600.0 s, 37415.4 tps, lat 26.727 ms stddev 11.521 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 22040445 latency average = 27.149 ms latency stddev = 11.617 ms tps = 36710.828624 (including connections establishing) tps = 36811.054851 (excluding connections establishing) - Bereiten Sie den Sysbench-Test vor:
Ausgabe:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ --oltp-table-size=450000 \ preparesysbench 0.5: multi-threaded system evaluation benchmark Creating table 'sbtest1'... Inserting 450000 records into 'sbtest1' Creating secondary indexes on 'sbtest1'... Creating table 'sbtest2'... ... Creating table 'sbtest250'... Inserting 450000 records into 'sbtest250' Creating secondary indexes on 'sbtest250'... - Führen Sie den Sysbench-Test aus:
Ausgabe:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ --oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp-sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-time=600 \ --num-threads=1000 \ runsysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 20443.09, reads: 0.00, writes: 81834.16, response time: 68.24ms (95%), errors: 0.62, reconnects: 0.00 [ 120s] threads: 1000, tps: 20580.68, reads: 0.00, writes: 82324.33, response time: 70.75ms (95%), errors: 0.73, reconnects: 0.00 [ 180s] threads: 1000, tps: 20531.85, reads: 0.00, writes: 82127.21, response time: 70.63ms (95%), errors: 0.73, reconnects: 0.00 [ 240s] threads: 1000, tps: 20212.67, reads: 0.00, writes: 80861.67, response time: 71.99ms (95%), errors: 0.43, reconnects: 0.00 [ 300s] threads: 1000, tps: 19383.90, reads: 0.00, writes: 77537.87, response time: 75.64ms (95%), errors: 0.75, reconnects: 0.00 [ 360s] threads: 1000, tps: 19797.20, reads: 0.00, writes: 79190.78, response time: 75.27ms (95%), errors: 0.68, reconnects: 0.00 [ 420s] threads: 1000, tps: 20304.43, reads: 0.00, writes: 81212.87, response time: 73.82ms (95%), errors: 0.70, reconnects: 0.00 [ 480s] threads: 1000, tps: 20933.80, reads: 0.00, writes: 83737.16, response time: 74.71ms (95%), errors: 0.68, reconnects: 0.00 [ 540s] threads: 1000, tps: 20663.05, reads: 0.00, writes: 82626.42, response time: 73.56ms (95%), errors: 0.75, reconnects: 0.00 [ 600s] threads: 1000, tps: 20746.02, reads: 0.00, writes: 83015.81, response time: 73.58ms (95%), errors: 0.78, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 48868458 other: 24434022 total: 73302480 transactions: 12216804 (20359.59 per sec.) read/write requests: 48868458 (81440.43 per sec.) other operations: 24434022 (40719.87 per sec.) ignored errors: 414 (0.69 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0516s total number of events: 12216804 total time taken by event execution: 599964.4735s response time: min: 6.27ms avg: 49.11ms max: 350.24ms approx. 95 percentile: 72.90ms Threads fairness: events (avg/stddev): 12216.8040/31.27 execution time (avg/stddev): 599.9645/0.01
Erfasste Metriken
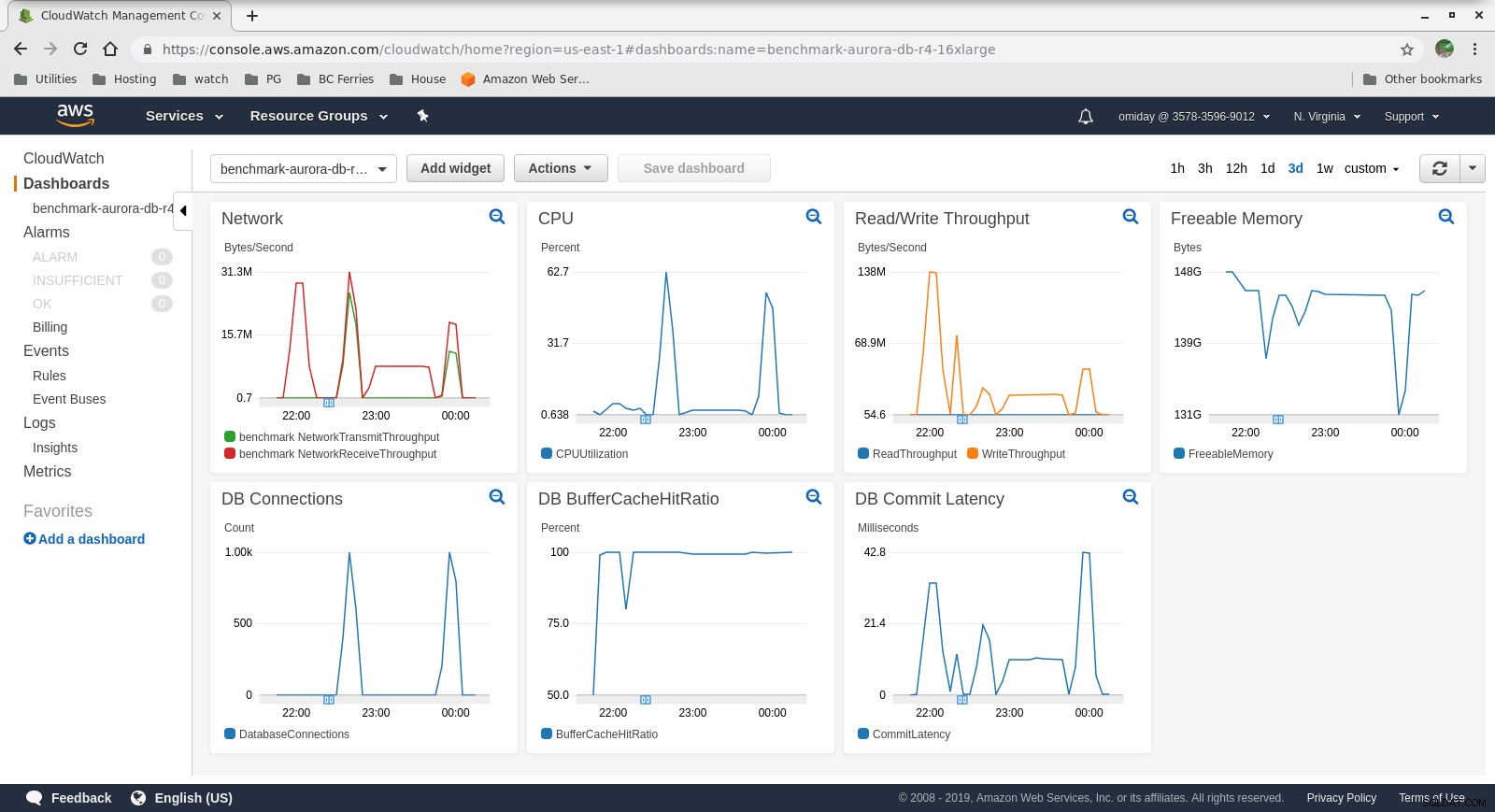 Cloudwatch-Metriken
Cloudwatch-Metriken 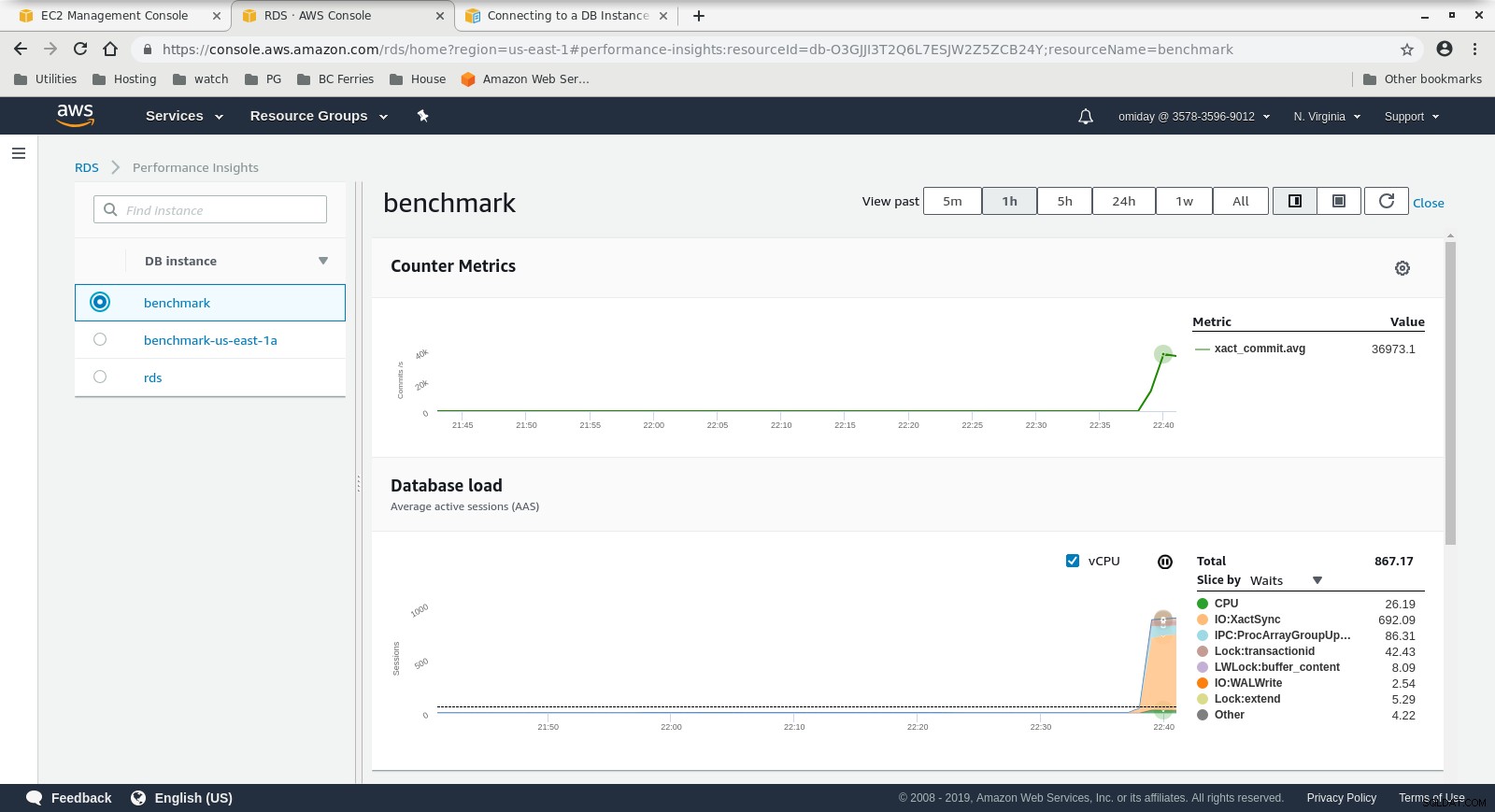 Performance Insights MetricsLaden Sie noch heute das Whitepaper herunter PostgreSQL-Verwaltung und -Automatisierung mit ClusterControlErfahren Sie, was Sie wissen müssen, um PostgreSQL verwalten und skalierenLaden Sie das Whitepaper herunter
Performance Insights MetricsLaden Sie noch heute das Whitepaper herunter PostgreSQL-Verwaltung und -Automatisierung mit ClusterControlErfahren Sie, was Sie wissen müssen, um PostgreSQL verwalten und skalierenLaden Sie das Whitepaper herunter Lauf Nr. 2
Besonderheiten
- Dieser Test verwendet die AWS-Spezifikationen für den Client und eine kleinere Instanzgröße für die Datenbank:
- Client-Rechner:On Demand Memory Optimized EC2-Instanz:
- vCPU:32 (16 Kerne x 2 Threads/Kern)
- RAM:244 GiB
- Speicher:EBS-optimiert
- Netzwerk:10 Gigabit
- DB-Cluster:db.r4.2xlarge:
- vCPU:8
- RAM:61 GiB
- Speicher:EBS-optimiert
- Netzwerk:1.750 Mbit/s maximale Bandbreite bei einer Verbindung mit bis zu 10 Gbit/s
- Client-Rechner:On Demand Memory Optimized EC2-Instanz:
- Die Datenbank enthielt kein Replikat.
- Datenbankspeicherung war nicht verschlüsselt.
Durchführung der Tests und Ergebnisse
Die Schritte sind identisch mit Ausführung Nr. 1, daher zeige ich nur die Ausgabe:
-
pgbench Lese-/Schreiblast:
... 745700000 of 1000000000 tuples (74%) done (elapsed 794.93 s, remaining 271.09 s) 745800000 of 1000000000 tuples (74%) done (elapsed 795.00 s, remaining 270.97 s) 745900000 of 1000000000 tuples (74%) done (elapsed 795.09 s, remaining 270.86 s) 746000000 of 1000000000 tuples (74%) done (elapsed 795.17 s, remaining 270.74 s) 746100000 of 1000000000 tuples (74%) done (elapsed 795.24 s, remaining 270.62 s) 746200000 of 1000000000 tuples (74%) done (elapsed 795.33 s, remaining 270.51 s) ... 999800000 of 1000000000 tuples (99%) done (elapsed 1067.11 s, remaining 0.21 s) 999900000 of 1000000000 tuples (99%) done (elapsed 1067.19 s, remaining 0.11 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 1067.28 s, remaining 0.00 s) vacuum... set primary keys... total time: 4386.44 s (insert 1067.33 s, commit 0.46 s, vacuum 2088.25 s, index 1230.41 s) done.starting vacuum...end. progress: 60.0 s, 3361.3 tps, lat 286.143 ms stddev 80.417 progress: 120.0 s, 3466.8 tps, lat 288.386 ms stddev 76.373 progress: 180.0 s, 3683.1 tps, lat 271.840 ms stddev 75.712 progress: 240.0 s, 3444.3 tps, lat 289.909 ms stddev 69.564 progress: 300.0 s, 3475.8 tps, lat 287.736 ms stddev 73.712 progress: 360.0 s, 3449.5 tps, lat 289.832 ms stddev 71.878 progress: 420.0 s, 3518.1 tps, lat 284.432 ms stddev 74.276 progress: 480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264 progress: 540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206 progress: 600.0 s, 3482.9 tps, lat 287.037 ms stddev 71.649 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 2090702 latency average = 286.030 ms latency stddev = 74.245 ms tps = 3481.731730 (including connections establishing) tps = 3494.157830 (excluding connections establishing) -
Sysbench-Test:
sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 4809.05, reads: 0.00, writes: 19301.02, response time: 288.03ms (95%), errors: 0.05, reconnects: 0.00 [ 120s] threads: 1000, tps: 5264.15, reads: 0.00, writes: 21005.40, response time: 255.23ms (95%), errors: 0.08, reconnects: 0.00 [ 180s] threads: 1000, tps: 5178.27, reads: 0.00, writes: 20713.07, response time: 260.40ms (95%), errors: 0.03, reconnects: 0.00 [ 240s] threads: 1000, tps: 5145.95, reads: 0.00, writes: 20610.08, response time: 255.76ms (95%), errors: 0.05, reconnects: 0.00 [ 300s] threads: 1000, tps: 5127.92, reads: 0.00, writes: 20507.98, response time: 264.24ms (95%), errors: 0.05, reconnects: 0.00 [ 360s] threads: 1000, tps: 5063.83, reads: 0.00, writes: 20278.10, response time: 268.55ms (95%), errors: 0.05, reconnects: 0.00 [ 420s] threads: 1000, tps: 5057.51, reads: 0.00, writes: 20237.28, response time: 269.19ms (95%), errors: 0.10, reconnects: 0.00 [ 480s] threads: 1000, tps: 5036.32, reads: 0.00, writes: 20139.29, response time: 279.62ms (95%), errors: 0.10, reconnects: 0.00 [ 540s] threads: 1000, tps: 5115.25, reads: 0.00, writes: 20459.05, response time: 264.64ms (95%), errors: 0.08, reconnects: 0.00 [ 600s] threads: 1000, tps: 5124.89, reads: 0.00, writes: 20510.07, response time: 265.43ms (95%), errors: 0.10, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 12225686 other: 6112822 total: 18338508 transactions: 3056390 (5093.75 per sec.) read/write requests: 12225686 (20375.20 per sec.) other operations: 6112822 (10187.57 per sec.) ignored errors: 42 (0.07 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0277s total number of events: 3056390 total time taken by event execution: 600005.2104s response time: min: 9.57ms avg: 196.31ms max: 608.70ms approx. 95 percentile: 268.71ms Threads fairness: events (avg/stddev): 3056.3900/67.44 execution time (avg/stddev): 600.0052/0.01
Erfasste Metriken
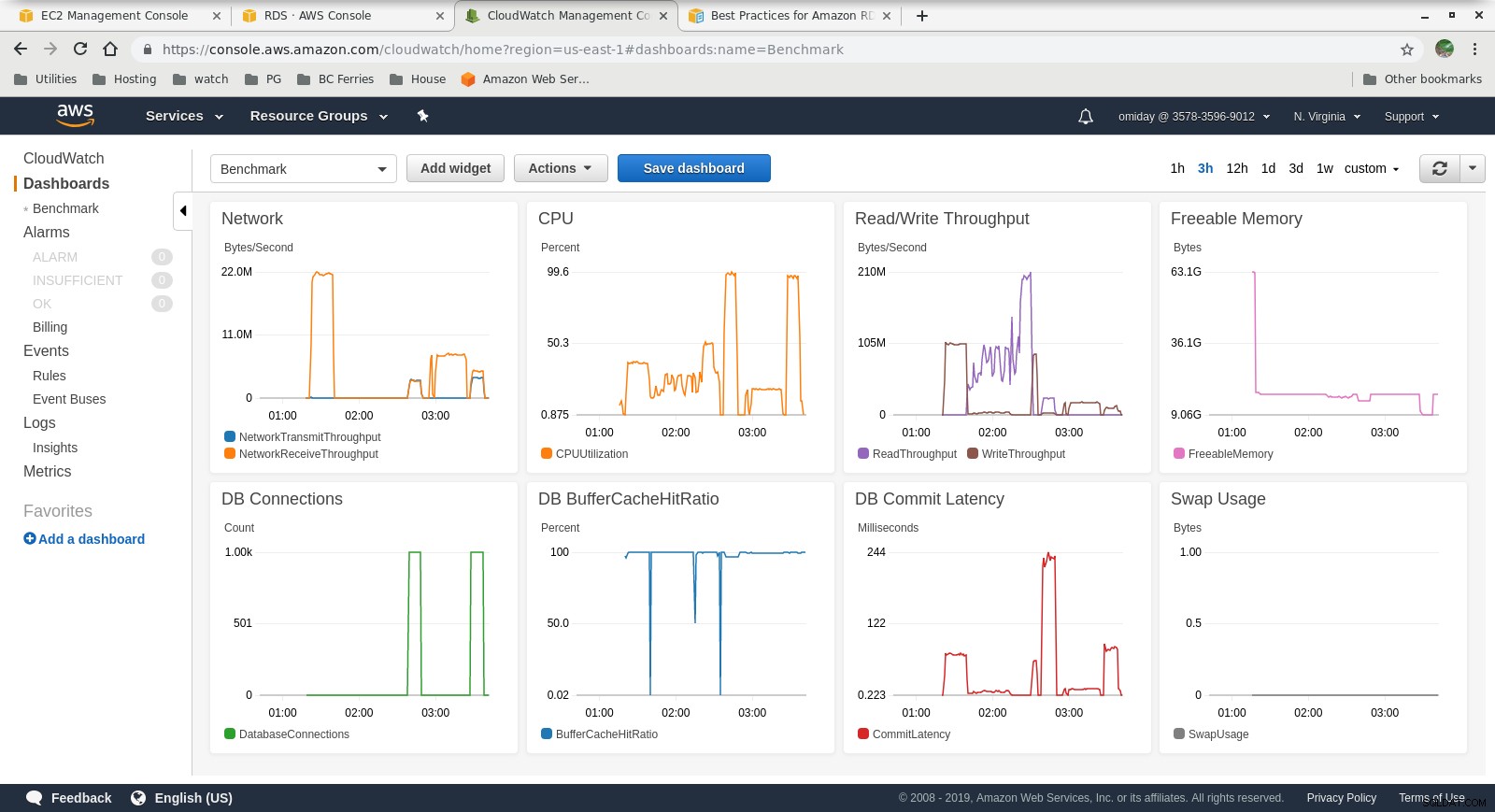 Cloudwatch-Metriken
Cloudwatch-Metriken 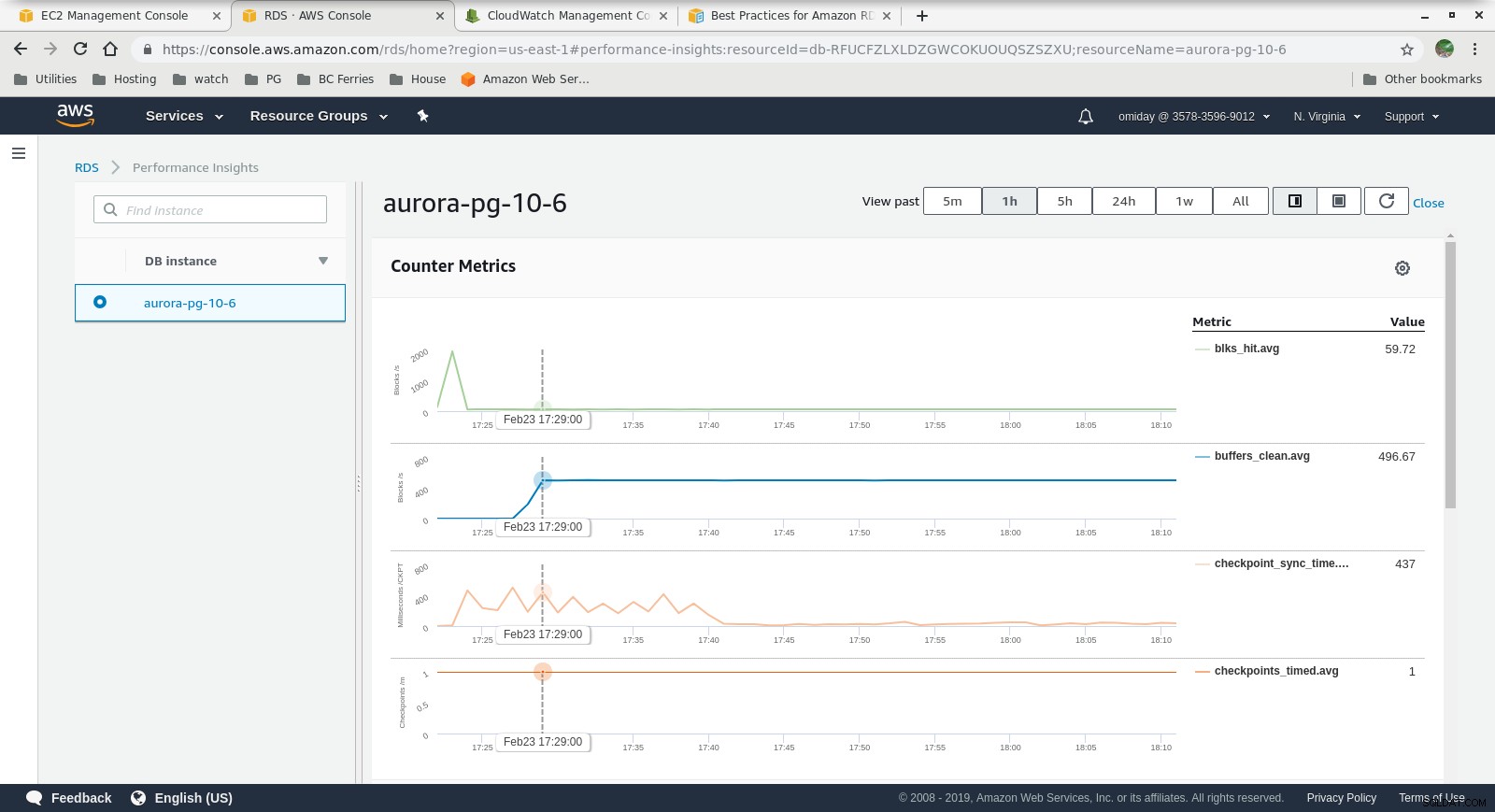 Leistungseinblicke – Zählermetriken
Leistungseinblicke – Zählermetriken 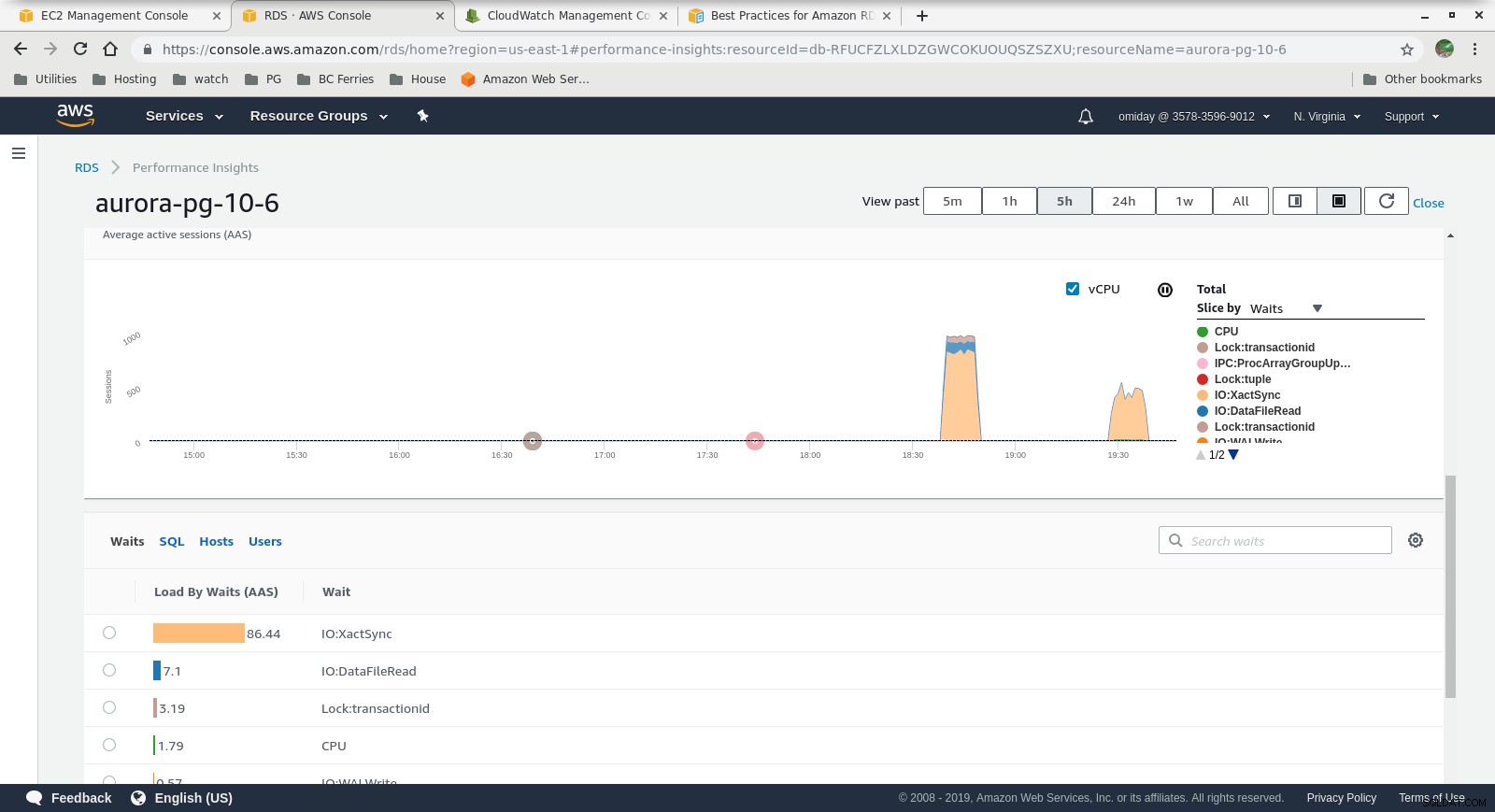 Leistungseinblicke – Datenbanklast nach Wartezeiten
Leistungseinblicke – Datenbanklast nach Wartezeiten Abschließende Gedanken
- Benutzer sind auf die Verwendung vordefinierter Instanzgrößen beschränkt. Als Nachteil, wenn der Benchmark zeigt, dass die Instanz von zusätzlichem Speicher profitieren kann, ist es nicht möglich, „einfach mehr RAM hinzuzufügen“. Das Hinzufügen von mehr Arbeitsspeicher bedeutet eine Erhöhung der Instanzgröße, was mit höheren Kosten einhergeht (die Kosten verdoppeln sich für jede Instanzgröße).
- Die Amazon Aurora-Speicher-Engine unterscheidet sich stark von RDS und baut auf SAN-Hardware auf. Die I/O-Durchsatzmetriken pro Instanz zeigen, dass der Test nicht noch näher an das Maximum für die bereitgestellten IOPS-SSD-EBS-Volumes von 1.750 MiB/s herangekommen ist.
- Eine weitere Optimierung kann durch Überprüfung der AWS PostgreSQL-Ereignisse durchgeführt werden, die in den Performance Insights-Diagrammen enthalten sind.
Nächster in der Serie
Bleiben Sie dran für den nächsten Teil:Amazon RDS für PostgreSQL 10.6.