Das Lesen aus dem Speicher ist immer performanter als das Auslesen von der Festplatte, daher sollten Sie für alle Datenbanktechnologien so viel Speicher wie möglich verwenden. Wenn Sie sich bei der Konfiguration nicht sicher sind oder einen Fehler haben, kann dies zu einer hohen Speicherauslastung oder sogar zu einem Problem mit nicht genügend Arbeitsspeicher führen.
In diesem Blog sehen wir uns an, wie Sie Ihre PostgreSQL-Speicherauslastung überprüfen und welche Parameter Sie berücksichtigen sollten, um sie zu optimieren. Sehen wir uns dazu zunächst einen Überblick über die Architektur von PostgreSQL an.
PostgreSQL-Architektur
Die Architektur von PostgreSQL basiert auf drei grundlegenden Teilen:Prozesse, Speicher und Festplatte.
Der Speicher kann in zwei Kategorien eingeteilt werden:
- Lokaler Speicher :Es wird von jedem Backend-Prozess für seine eigene Verwendung zur Verarbeitung von Abfragen geladen. Es ist in Unterbereiche unterteilt:
- Arbeitsspeicher:Der Arbeitsspeicher wird zum Sortieren von Tupeln durch ORDER BY- und DISTINCT-Operationen und zum Verbinden von Tabellen verwendet.
- Wartungsarbeitsspeicher:Einige Arten von Wartungsarbeiten verwenden diesen Bereich. Beispiel:VACUUM, wenn Sie autovacuum_work_mem nicht angeben.
- Temp-Puffer:Wird zum Speichern temporärer Tabellen verwendet.
- Gemeinsamer Speicher :Es wird vom PostgreSQL-Server beim Start zugewiesen und von allen Prozessen verwendet. Es ist in Unterbereiche unterteilt:
- Gemeinsamer Pufferpool:Hier lädt PostgreSQL Seiten mit Tabellen und Indizes von der Festplatte, um direkt vom Speicher aus zu arbeiten und den Festplattenzugriff zu reduzieren.
- WAL-Puffer:Die WAL-Daten sind das Transaktionsprotokoll in PostgreSQL und enthalten die Änderungen in der Datenbank. Der WAL-Puffer ist der Bereich, in dem die WAL-Daten vorübergehend gespeichert werden, bevor sie auf die Festplatte in die WAL-Dateien geschrieben werden. Dies geschieht zu jeder vordefinierten Zeit, die Checkpoint genannt wird. Dies ist sehr wichtig, um den Verlust von Informationen im Falle eines Serverausfalls zu vermeiden.
- Commit-Protokoll:Es speichert den Status aller Transaktionen zur Parallelitätssteuerung.
Wie man weiß, was passiert
Wenn Sie eine hohe Speicherauslastung haben, sollten Sie zuerst bestätigen, welcher Prozess den Verbrauch erzeugt.
Verwendung des „obersten“ Linux-Befehls
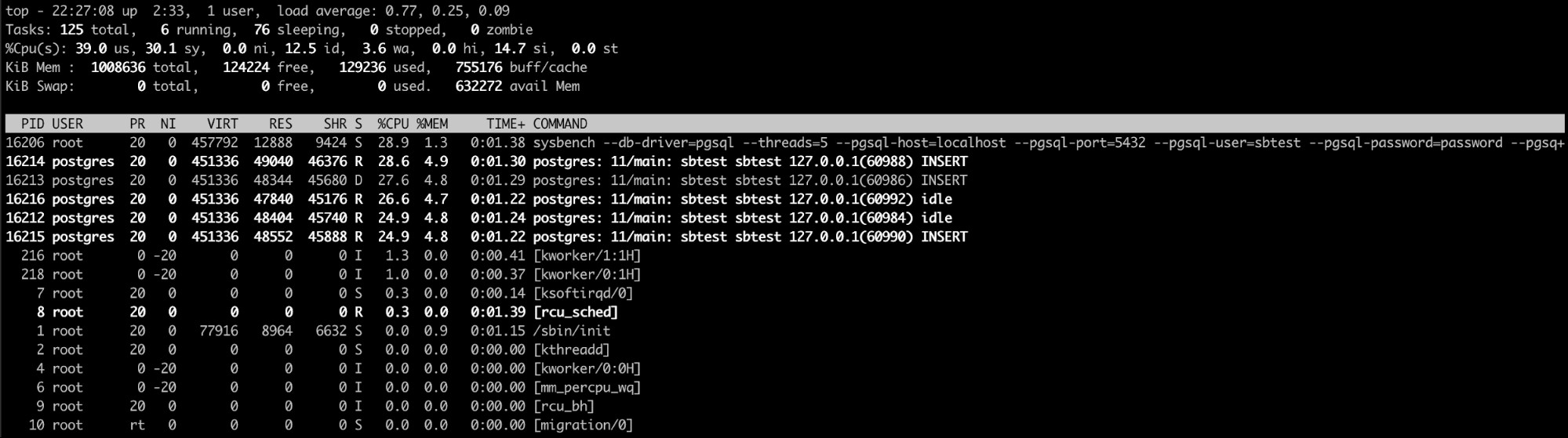
Der Top-Linux-Befehl ist hier wahrscheinlich die beste Option (oder sogar eine ähnliche eine wie htop). Mit diesem Befehl können Sie die Prozesse sehen, die zu viel Speicher verbrauchen.
Wenn Sie bestätigen, dass PostgreSQL für dieses Problem verantwortlich ist, prüfen Sie im nächsten Schritt, warum.
Verwenden des PostgreSQL-Protokolls
Das Überprüfen sowohl der PostgreSQL- als auch der Systemprotokolle ist definitiv eine gute Möglichkeit, mehr Informationen darüber zu erhalten, was in Ihrer Datenbank/Ihrem System passiert. Sie könnten Nachrichten sehen wie:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childWenn Sie nicht genug freien Speicherplatz haben.
Oder sogar mehrere Datenbanknachrichtenfehler wie:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedWenn Sie ein unerwartetes Verhalten auf der Datenbankseite haben. Die Protokolle sind also nützlich, um diese Art von Problemen und noch mehr zu erkennen. Sie können diese Überwachung automatisieren, indem Sie die Protokolldateien analysieren und nach Werken wie „FATAL“, „ERROR“ oder „Kill“ suchen, sodass Sie eine Benachrichtigung erhalten, wenn dies geschieht.
Pg_top verwenden
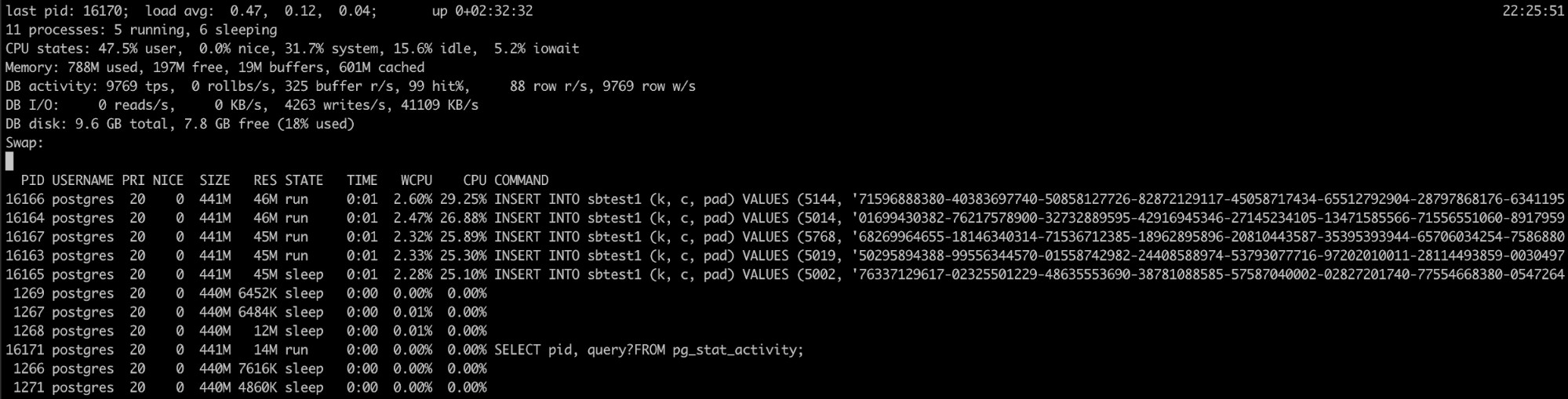
Wenn Sie wissen, dass der PostgreSQL-Prozess eine hohe Speicherauslastung hat, aber Die Protokolle haben nicht geholfen, Sie haben ein anderes Tool, das hier nützlich sein kann, pg_top.
Dieses Tool ähnelt dem Top-Linux-Tool, ist aber speziell für PostgreSQL. Wenn Sie es verwenden, erhalten Sie detailliertere Informationen darüber, was Ihre Datenbank ausführt, und Sie können sogar Abfragen beenden oder einen Explain-Job ausführen, wenn Sie einen Fehler feststellen. Weitere Informationen zu diesem Tool finden Sie hier.
Aber was passiert, wenn Sie keinen Fehler feststellen können und die Datenbank immer noch viel RAM verwendet? Daher müssen Sie wahrscheinlich die Datenbankkonfiguration überprüfen.
Welche Konfigurationsparameter zu berücksichtigen sind
Wenn alles gut aussieht, Sie aber immer noch das Problem der hohen Auslastung haben, sollten Sie die Konfiguration überprüfen, um zu bestätigen, ob sie korrekt ist. Die folgenden Parameter sollten Sie also in diesem Fall berücksichtigen.
shared_buffers
Dies ist die Speichermenge, die der Datenbankserver für gemeinsam genutzte Speicherpuffer verwendet. Wenn dieser Wert zu niedrig ist, würde die Datenbank mehr Festplatte verwenden, was zu mehr Verlangsamung führen würde, aber wenn er zu hoch ist, könnte es zu einer hohen Speicherauslastung kommen. Wenn Sie einen dedizierten Datenbankserver mit 1 GB oder mehr RAM haben, ist laut Dokumentation ein vernünftiger Startwert für shared_buffers 25 % des Speichers in Ihrem System.
work_mem
Es gibt die Speichermenge an, die von ORDER BY, DISTINCT und JOIN verwendet wird, bevor in die temporären Dateien auf der Festplatte geschrieben wird. Wie bei den shared_buffers können wir, wenn wir diesen Parameter zu niedrig konfigurieren, mehr Operationen auf die Festplatte übertragen, aber ein zu hoher Wert ist gefährlich für die Speichernutzung. Der Standardwert ist 4 MB.
max_connections
Work_mem geht auch Hand in Hand mit dem Wert max_connections, da jede Verbindung diese Operationen gleichzeitig ausführt und jede Operation so viel Speicher verwenden darf, wie durch diesen Wert davor angegeben beginnt, Daten in temporäre Dateien zu schreiben. Dieser Parameter bestimmt die maximale Anzahl gleichzeitiger Verbindungen zu unserer Datenbank. Wenn wir eine hohe Anzahl von Verbindungen konfigurieren und dies nicht berücksichtigen, können Ressourcenprobleme auftreten. Der Standardwert ist 100.
temp_buffers
Die temporären Puffer werden verwendet, um die temporären Tabellen zu speichern, die in jeder Sitzung verwendet werden. Dieser Parameter legt die maximale Speichermenge für diese Aufgabe fest. Der Standardwert ist 8 MB.
maintenance_work_mem
Dies ist der maximale Speicher, den eine Operation wie Vakuumieren, Hinzufügen von Indizes oder Fremdschlüsseln verbrauchen kann. Das Gute daran ist, dass nur eine Operation dieser Art in einer Sitzung ausgeführt werden kann und es nicht üblich ist, mehrere davon gleichzeitig im System auszuführen. Der Standardwert ist 64 MB.
autovacuum_work_mem
Das Vakuum verwendet standardmäßig das maintenance_work_mem, aber wir können es mit diesem Parameter trennen. Wir können hier die maximale Menge an Speicher angeben, die von jedem Autovacuum-Worker verwendet werden soll.
wal_buffers
Die Menge des gemeinsam genutzten Speichers, der für WAL-Daten verwendet wird, die noch nicht auf die Festplatte geschrieben wurden. Die Standardeinstellung ist 3 % von shared_buffers, aber nicht weniger als 64 KB und nicht mehr als die Größe eines WAL-Segments, typischerweise 16 MB.
Fazit
Es gibt verschiedene Gründe für eine hohe Speicherauslastung, und das Erkennen des Grundproblems kann eine zeitaufwändige Aufgabe sein. In diesem Blog haben wir verschiedene Möglichkeiten erwähnt, Ihre PostgreSQL-Speicherauslastung zu überprüfen und welche Parameter Sie berücksichtigen sollten, um sie zu optimieren, um eine übermäßige Speicherauslastung zu vermeiden.