Skalierbarkeit ist die Eigenschaft eines Systems, eine wachsende Menge an Anforderungen durch Hinzufügen von Ressourcen zu bewältigen. Die Gründe für diese Menge an Nachfragen können vorübergehend sein, beispielsweise wenn Sie einen Rabatt auf einen Verkauf einführen, oder dauerhaft, um die Anzahl der Kunden oder Mitarbeiter zu erhöhen. In jedem Fall sollten Sie in der Lage sein, Ressourcen hinzuzufügen oder zu entfernen, um diese Änderungen entsprechend den Anforderungen oder dem Anstieg des Datenverkehrs zu verwalten.
Es gibt verschiedene Ansätze, um Ihre Datenbank zu skalieren. In diesem Blog sehen wir uns an, was diese Ansätze sind und wie Sie Ihre PostgreSQL-Datenbank mit Connection Poolers und Load Balancern skalieren.
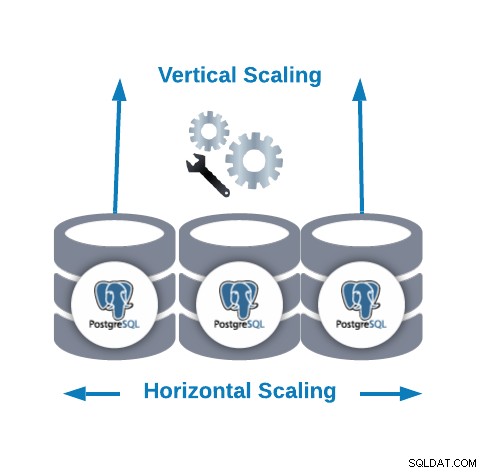
Horizontale und vertikale Skalierung
Es gibt zwei Möglichkeiten, Ihre Datenbank zu skalieren.
- Horizontale Skalierung (Scale-out):Dies wird durch Hinzufügen weiterer Datenbankknoten durchgeführt, wodurch ein Datenbankcluster erstellt oder vergrößert wird. Es kann Ihnen helfen, die Leseleistung zu verbessern, indem der Datenverkehr zwischen den Knoten ausgeglichen wird.
- Vertikale Skalierung (Scale-up):Es wird durchgeführt, indem einem vorhandenen Datenbankknoten weitere Hardwareressourcen (CPU, Arbeitsspeicher, Festplatte) hinzugefügt werden. Es kann erforderlich sein, einige Konfigurationsparameter zu ändern, damit PostgreSQL eine neue oder bessere Hardware-Ressource verwenden kann.
Verbindungspooler und Load Balancer
Bei horizontaler und vertikaler Skalierung kann es nützlich sein, ein externes Tool hinzuzufügen, um die Belastung Ihrer Datenbank zu verringern und die Leistung zu verbessern. Vielleicht ist es nicht genug, aber es ist ein guter Ausgangspunkt. Dafür ist es eine gute Idee, einen Connection Pooler und einen Load Balancer zu implementieren. Ich habe „und“ gesagt, weil sie für unterschiedliche Rollen ausgelegt sind.
Ein Verbindungs-Pooling ist eine Methode, um einen Pool von Verbindungen zu erstellen und diese wiederzuverwenden, ohne ständig neue Verbindungen zur Datenbank öffnen zu müssen, wodurch die Leistung Ihrer Anwendungen erheblich gesteigert wird. PgBouncer ist ein beliebter Verbindungspooler, der für PostgreSQL entwickelt wurde.
Die Verwendung eines Load Balancers ist eine Möglichkeit, Hochverfügbarkeit in Ihrer Datenbanktopologie zu erreichen, und es ist auch nützlich, die Leistung zu steigern, indem der Datenverkehr zwischen den verfügbaren Knoten verteilt wird. Aus diesem Grund ist HAProxy eine gute Option für PostgreSQL, da es sich um einen Open-Source-Proxy handelt, der zur Implementierung von Hochverfügbarkeit, Lastausgleich und Proxying für TCP- und HTTP-basierte Anwendungen verwendet werden kann.
Wie man eine Kombination aus HAProxy, PgBouncer und PostgreSQL implementiert
Eine Kombination beider Technologien, HAProxy und PgBouncer, ist wahrscheinlich der beste Weg, um die Leistung in Ihrer PostgreSQL-Umgebung zu skalieren und zu verbessern. Wir werden also sehen, wie man es mit der folgenden Architektur implementiert:
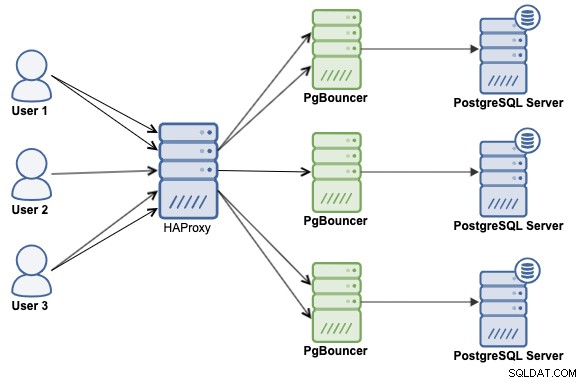
Wir gehen davon aus, dass Sie ClusterControl installiert haben, wenn nicht, können Sie zu gehen die offizielle Seite, oder beziehen Sie sich sogar auf die offizielle Dokumentation, um es zu installieren.
Zunächst müssen Sie Ihren PostgreSQL-Cluster mit HAProxy davor bereitstellen. Befolgen Sie dazu bitte die Schritte in diesem Blogbeitrag, um sowohl PostgreSQL als auch HAProxy mithilfe von ClusterControl bereitzustellen.
An diesem Punkt haben Sie so etwas:
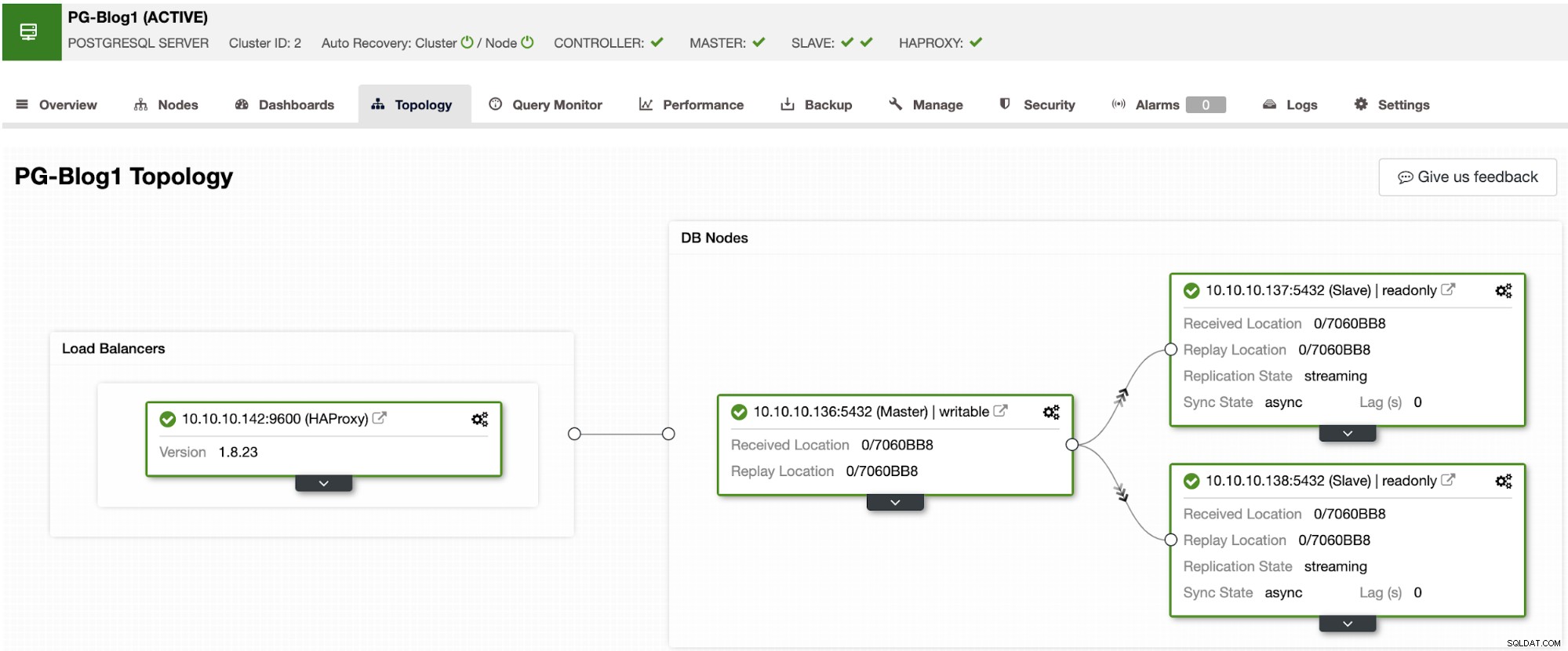
Jetzt können Sie PgBouncer auf jedem Datenbankknoten oder auf einem externen Rechner installieren .
Um die PgBouncer-Software zu erhalten, können Sie zum PgBouncer-Downloadbereich gehen oder die RPM- oder DEB-Repositories verwenden. Für dieses Beispiel verwenden wir CentOS 8 und installieren es aus dem offiziellen PostgreSQL-Repository.
Laden Sie zuerst das entsprechende Repository von der PostgreSQL-Site herunter und installieren Sie es (falls Sie es noch nicht eingerichtet haben):
$ wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
$ rpm -Uvh pgdg-redhat-repo-latest.noarch.rpmInstallieren Sie dann das PgBouncer-Paket:
$ yum install pgbouncerWenn es abgeschlossen ist, haben Sie eine neue Konfigurationsdatei, die sich in /etc/pgbouncer/pgbouncer.ini befindet. Als Standard-Konfigurationsdatei können Sie das folgende Beispiel verwenden:
$ cat /etc/pgbouncer/pgbouncer.ini
[databases]
world = host=127.0.0.1 port=5432 dbname=world
[pgbouncer]
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admindbUnd die Authentifizierungsdatei:
$ cat /etc/pgbouncer/userlist.txt
"admindb" "root123"Dies ist nur ein einfaches Beispiel. Um alle verfügbaren Parameter zu erhalten, können Sie die offizielle Dokumentation einsehen.
Also, in diesem Fall habe ich PgBouncer im selben Datenbankknoten installiert, hört alle IP-Adressen ab und stellt eine Verbindung zu einer PostgreSQL-Datenbank namens „world“ her. Ich verwalte auch die erlaubten Benutzer in der userlist.txt-Datei mit einem Klartext-Passwort, das bei Bedarf verschlüsselt werden kann.
Um den PgBouncer-Dienst zu starten, müssen Sie nur den folgenden Befehl ausführen:
$ pgbouncer -d /etc/pgbouncer/pgbouncer.iniFühren Sie nun den folgenden Befehl mit Ihren lokalen Informationen (Port, Host, Benutzername und Datenbankname) aus, um auf die PostgreSQL-Datenbank zuzugreifen:
$ psql -p 6432 -h 127.0.0.1 -U admindb world
Password for user admindb:
psql (12.4)
Type "help" for help.
world=#Dies ist eine grundlegende Topologie. Sie können es verbessern, indem Sie beispielsweise zwei oder mehr Load-Balancer-Knoten hinzufügen, um einen einzelnen Fehlerpunkt zu vermeiden, und ein Tool wie „Keepalived“ verwenden, um die Verfügbarkeit sicherzustellen. Dies kann auch mit ClusterControl erfolgen.
Weitere Informationen zu PgBouncer und seiner Verwendung finden Sie in diesem Blogbeitrag.
Fazit
Wenn Sie Ihren PostgreSQL-Cluster skalieren müssen, ist das Hinzufügen von HAProxy und PgBouncer eine gute Möglichkeit zum gleichzeitigen Auf- und Aufskalieren, da Sie weitere Hot-Standby-Knoten hinzufügen können, um den Datenverkehr auszugleichen und Sie werden die Leistung verbessern, indem Sie geöffnete Verbindungen wiederverwenden.
ClusterControl bietet eine ganze Reihe von Funktionen, von Überwachung, Alarmierung, automatischem Failover, Backup, Point-in-Time-Recovery, Backup-Verifizierung bis hin zur Skalierung von Read Replicas. Dies kann Ihnen dabei helfen, Ihre PostgreSQL-Datenbank über eine benutzerfreundliche und intuitive Benutzeroberfläche horizontal oder vertikal zu skalieren.