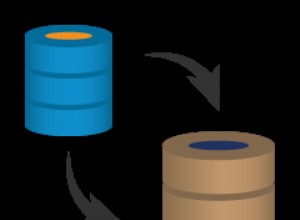
Oben gezeigt ist eine Übersicht über die asynchrone Slony-I-Replikation in Kurzform. Für weitere Informationen ist die Slony-I-Dokumentation Ihr bester Freund :).
Beginnen wir mit Replikationsmethoden, in der Perltools-Methode müssen Sie slony zum Zeitpunkt der Quellinstallation konfigurieren, um integrierte Perl-Skripte zu aktivieren. Diese Skripte beginnen mit „SLONIK_“ und sind für die Durchführung von Replikationsverwaltungsaufgaben konzipiert.
Meine Demo für zwei Methoden Shell (Slonik) &Perl ist auf Localhost Single Instance (5432) mit zwei Datenbanken Master &Slave, die eine Tabelle „rep_table“ replizieren. Für die Replikation sollten Master/Slave die gleiche Tabellenstruktur haben. Wenn Sie viele Tabellen haben, verwenden Sie die pg_dump/pg_restore-Struktur-Dump-Option. Da ich eine Tabelle repliziere, habe ich dieselbe auf Master/Slave erstellt.
Hinweis:Setzen Sie Umgebungsvariablen wie PGDATA, PGPORT, PGHOST, PGPASSWORD &PGUSER.
Quellinstallation:
Laden Sie die Slony-I 2.1-Quelle herunter (https://slony.info/downloads/)
#bunzip2 slony1-2.1.0.tar.bz2
#tar -xvf slony1 -2.1.0.tar
# cd slony1-2.1.0
#./configure --prefix=/opt/PostgreSQL/9.1/bin
--with-pgconfigdir=/opt/ PostgreSQL/9.1/bin
--with-perltools=/opt/PostgreSQL/9.1/bin
// --with-perltools ausschließen, falls nicht erforderlich
# make
# make installieren
Grundeinstellung auf Master/Slave
createdb -p 5432 master
createdb -p 5432 slave
psql -p 5432 -d master -c "create table rep_table(id int primary key);"
psql -p 5432 -d slave -c "create table rep_table(id int primary key);"
Fügen Sie einige Daten auf dem Master ein, um sie auf den Slave zu replizieren
psql -p 5432 -d master - c "insert into rep_table values(generate_series(1,10));"
Methode 1:–with-perltools :
1. Erstellen Sie eine standardmäßige .conf-Datei mit Informationen wie Protokollspeicherort, Anzahl der Knoten, Satz von Tabellen usw.,
$CLUSTER_NAME ='myrep';
$LOGDIR ='/opt/PostgreSQL/9.1/slonylogs';
$MASTERNODE =1;
$DEBUGLEVEL =2;
&add_node(node => 1,host => 'localhost',dbname => 'master',port => 5432,user => 'postgres',password => 'postgres');
&add_node (node => 2,host => 'localhost',dbname => 'slave',port => 5433,user => 'postgres',password => 'postgres');
$SLONY_SETS =
{
"set1" =>
{
"set_id" => 1,
"table_id" => 1,
"pkeyedtables" =>
[rep_table,],
},
};
Initialisieren, Set erstellen und Set abonnieren, das sind die drei Phasen der schleichenden Replikation. Für jede Phase werden „slonik_“-Perl-Skripte an dem Ort erstellt, der zum Zeitpunkt der Quellinstallation mit der Option „–with-perltools“ angegeben wurde. In meinem Fall ist es „/opt/PostgreSQL/9.1/bin“. Obige CONF-Datei wird in allen Phasen verwendet.
2. Initialisieren Sie den Cluster. Hier überprüft slonik die Knotenverbindung.
cd /opt/PostgreSQL/9.1/bin
./slonik_init_cluster -c slon.conf
./slonik_init_cluster -c slon.conf| ./slonik
3. Erstellen Sie einen Satz, d. h. welcher Tabellensatz von Knoten 1 auf Knoten 2 repliziert werden soll.
./slonik_create_set -c slon.conf 1
./slonik_create_set -c slon.conf 1|./slonik
4. Starten Sie Slon-Daemons. Jeder Knoten hat zwei Slon-Prozesse, um Arbeit zu transportieren. Jeder Node-Slon-Prozess sollte gestartet werden.
./slon_start -c slon.conf 1
./slon_start -c slon.conf 2
5. Subscribe Set, von hier an behält Slony die Datenkonsistenz zwischen zwei Knoten bei, indem es Master für alle DMLs zulässt und sie auf Slave verweigert.
./slonik_subscribe_set -c slon.conf 1 2
./slonik_subscribe_set -c slon.conf 1 2|./slonik
Nach den obigen Schritten hat Ihr Slave nun replizierte Daten.
Methode 2:Mit Standardskripten:
In Standard-Skriptmethoden gibt es viele Möglichkeiten zur Implementierung, aber um es klar zu verstehen, habe ich es genauso aufgeteilt wie Perl, wie wir es oben getan haben, wie Initialize, Create-Set &Subscribe Set. Alle Skripte sind mit dem SLONIK-Befehl gebunden.
1. Erstellen Sie zwei .conf-Dateien für den Master- und den Slave-Knoten.
vi master_slon.conf
cluster_name=myrep
pid_file='/opt/PostgreSQL/9.1/data/master_slon.pid'
conn_info='host=localhost dbname=master user=postgres port=5432'
vi slave_slon.conf
cluster_name=myrep
pid_file='/opt/PostgreSQL/9.1/data/slave_slon.pid'
conn_info=' host=localhost dbname=slave1 user=postgres port=5432'
2. Cluster initialisieren.
#!/bin/bash
# Cluster initialisieren (init_cluster.sh)
slonik <<_eof_
cluster name =myrep;
node 1 admin conninfo ='host=127.0.0.1 dbname=master user=postgres port=5432';
node 2 admin conninfo='host=127.0.0.1 dbname=slave1 user=postgres port=5432';
#Add Node
init cluster (id =1, comment ='Primary Node For the Slave postgres');
store node (id =2, event node =1, comment ='Slave Node For Das primäre Postgres');
#Speicherpfade festlegen ...
echo 'Alle Knoten in den Slony-Katalogen gespeichert';
Pfad speichern (Server =1, Client =2 , conninfo='host=127.0.0.1 dbname=master user=postgres port=5432');
store path(server =2, client =1, conninfo='host=127.0.0.1 dbname=slave1 user=postgres port=5432');
_eof_
$./init_cluster.sh
3. Erstellen Sie einen Satz.
#!/bin/bash
# Satz für Satz von Tabellen erstellen (create-set.sh)
slonik <<_eof_
cluster name =myrep;
Knoten 1 admin conninfo='host=127.0.0.1 dbname=master user=postgres port=5432';
Knoten 2 admin conninfo='host=127.0.0.1 dbname=slave1 user=postgres port=5432';
try { set erstellen (id =1 ,origin =1 , comment ='Set for public'); } on error { echo 'Set1 konnte nicht erstellt werden'; exit 1;}
set add table (set id =1 , origin =1, id =1, fullqualified name ='public.rep_table1', comment ='Table action with primary key');
_eof_
$./create-set.sh
4. Um Slon-Daemons zu starten, verwenden Sie ein benutzerdefiniertes Skript, das mit dem Quell-Tarbal unter „/tools“ im Verzeichnis „start_slon.sh“ geliefert wird. Ändern Sie das Skript, indem Sie die Speicherorte der .conf-Dateien für Master/Slave-Startskripts ändern. Dieses Skript bietet die Flexibilität, alle Slon-Prozesse mit Hilfe der in der .conf-Datei erwähnten PIDs zu verwenden und zu verfolgen.
Verwendung:./master_start_slon.sh [start|stop|status]
-bash-4.1$ ./master_start_slon.sh start
-bash-4.1$ ./slave_start_slon.sh start
Beispiel für die STATUS-Ausgabe:
-bash-4.1$ ./master_start_slon.sh status
-------------- -------
Slony-Konfigurationsdatei:/opt/PostgreSQL/9.1/slony_scripts/bash_slony/master_slon.conf
Slony-Bin-Pfad:/opt/PostgreSQL/9.1/bin
Slony Laufstatus :Läuft...
Slony Running (M)PID :28487
---------------------
4. Set abonnieren.
#!/bin/bash
# Subscribe Set (subscribe-set.sh)
slonik <<_eof_
cluster name =myrep;
node 1 admin conninfo='host=127.0.0.1 dbname=master user=postgres port=5432';
node 2 admin conninfo='host=127.0.0.1 dbname=slave1 user=postgres port=5432';
versuche {Subscribe Set (ID =1, Anbieter =1, Empfänger =2, Weiterleitung =Ja, Kopie weglassen =Falsch); } bei Fehler {Ausgang 1; } echo 'Subscribed nodes to set 1';
_eof_
$./subscribe-set.shJetzt hat Ihre Slave-Datenbank replizierte Daten in der Tabelle „rep_table“.
Diese beiden Methoden helfen, die grundlegende Einrichtung der Slony-Replikation zu verstehen. Wir werden mit fortgeschritteneren Slony-Konzepten zurück sein.