Vor ein paar Wochen wurden zwei schwerwiegende Sicherheitslücken (Codenamen Meltdown und Spectre) bekannt. Anfängliche Tests deuteten darauf hin, dass die Auswirkungen von (im Kernel hinzugefügten) Minderungen auf die Leistung bei einigen Workloads je nach Syscall-Rate bis zu ~30 % betragen könnten.
Diese frühen Schätzungen mussten schnell durchgeführt werden und basierten daher auf einer begrenzten Anzahl von Tests. Darüber hinaus haben sich die Kernel-Fixes im Laufe der Zeit weiterentwickelt und verbessert, und wir haben jetzt auch retpoline was Spectre v2 ansprechen sollte. Dieser Beitrag präsentiert Daten aus gründlicheren Tests und liefert hoffentlich zuverlässigere Schätzungen für typische PostgreSQL-Workloads.
Verglichen mit der frühen Bewertung von Meltdown-Korrekturen, die Simon am 10. Januar gepostet hat, sind die in diesem Post präsentierten Daten detaillierter, aber im Allgemeinen werden in diesem Post Match-Ergebnisse präsentiert.
Dieser Beitrag konzentriert sich auf PostgreSQL-Workloads, und obwohl er für andere Systeme mit hohen Systemaufruf-/Kontextwechselraten nützlich sein kann, ist er sicherlich nicht universell anwendbar. Wenn Sie an einer allgemeineren Erklärung der Schwachstellen und der Folgenabschätzung interessiert sind, hat Brendan Gregg vor ein paar Tagen einen hervorragenden Artikel zu KPTI/KAISER Meltdown Initial Performance Regressions veröffentlicht. Eigentlich könnte es nützlich sein, es zuerst zu lesen und dann mit diesem Beitrag fortzufahren.
Hinweis: Dieser Beitrag soll Sie nicht davon abhalten, die Fixes zu installieren, sondern Ihnen eine Vorstellung davon geben, wie sich die Auswirkungen auf die Leistung auswirken können. Sie sollten alle Fixes installieren, damit Ihre Umgebung sicher ist, und diesen Beitrag verwenden, um zu entscheiden, ob Sie möglicherweise Hardware aktualisieren müssen usw.
Welche Tests werden wir durchführen?
Wir werden uns zwei übliche grundlegende Workload-Typen ansehen – OLTP (kleine einfache Transaktionen) und OLAP (komplexe Abfragen, die große Datenmengen verarbeiten). Die meisten PostgreSQL-Systeme können als Mischung dieser beiden Workload-Typen modelliert werden.
Für OLTP haben wir pgbench verwendet, ein bekanntes Benchmarking-Tool, das mit PostgreSQL bereitgestellt wird. Wir haben beide schreibgeschützt getestet (-S ) und Lese-/Schreibzugriff (-N )-Modi mit drei verschiedenen Skalierungen – passt in shared_buffers, in RAM und größer als RAM.
Für den OLAP-Fall haben wir den dbt-3-Benchmark verwendet, der TPC-H ziemlich nahe kommt, mit zwei unterschiedlichen Datengrößen – 10 GB, die in den RAM passen, und 50 GB, die größer als der RAM sind (unter Berücksichtigung von Indizes usw.).
Alle präsentierten Zahlen stammen von einem Server mit 2x Xeon E5-2620v4, 64GB RAM und Intel SSD 750 (400GB). Auf dem System lief Gentoo mit Kernel 4.15.3, kompiliert mit GCC 7.3 (wird benötigt, um die vollständige retpoline zu aktivieren Fix). Die gleichen Tests wurden auch auf einem älteren/kleineren System mit i5-2500k CPU, 8GB RAM und 6x Intel S3700 SSD (in RAID-0) durchgeführt. Aber das Verhalten und die Schlussfolgerungen sind ziemlich gleich, daher werden wir die Daten hier nicht präsentieren.
Wie üblich sind vollständige Skripte/Ergebnisse für beide Systeme auf github verfügbar.
In diesem Beitrag geht es um die Auswirkungen der Minderung auf die Leistung. Konzentrieren wir uns also nicht auf absolute Zahlen und betrachten wir stattdessen die Leistung relativ zu einem ungepatchten System (ohne die Kernel-Minderungen). Alle Diagramme im OLTP-Bereich zeigen
(throughput with patches) / (throughput without patches)
Wir erwarten Zahlen zwischen 0 % und 100 %, wobei höhere Werte besser sind (geringere Auswirkungen von Minderungsmaßnahmen), wobei 100 % „keine Auswirkung“ bedeutet.
Hinweis: Die y-Achse beginnt bei 75 %, um die Unterschiede besser sichtbar zu machen.
OLTP / schreibgeschützt
Sehen wir uns zunächst die Ergebnisse für den schreibgeschützten pgbench an, der von diesem Befehl ausgeführt wird
pgbench -n -c 16 -j 16 -S -T 1800 test
und durch das folgende Diagramm veranschaulicht:
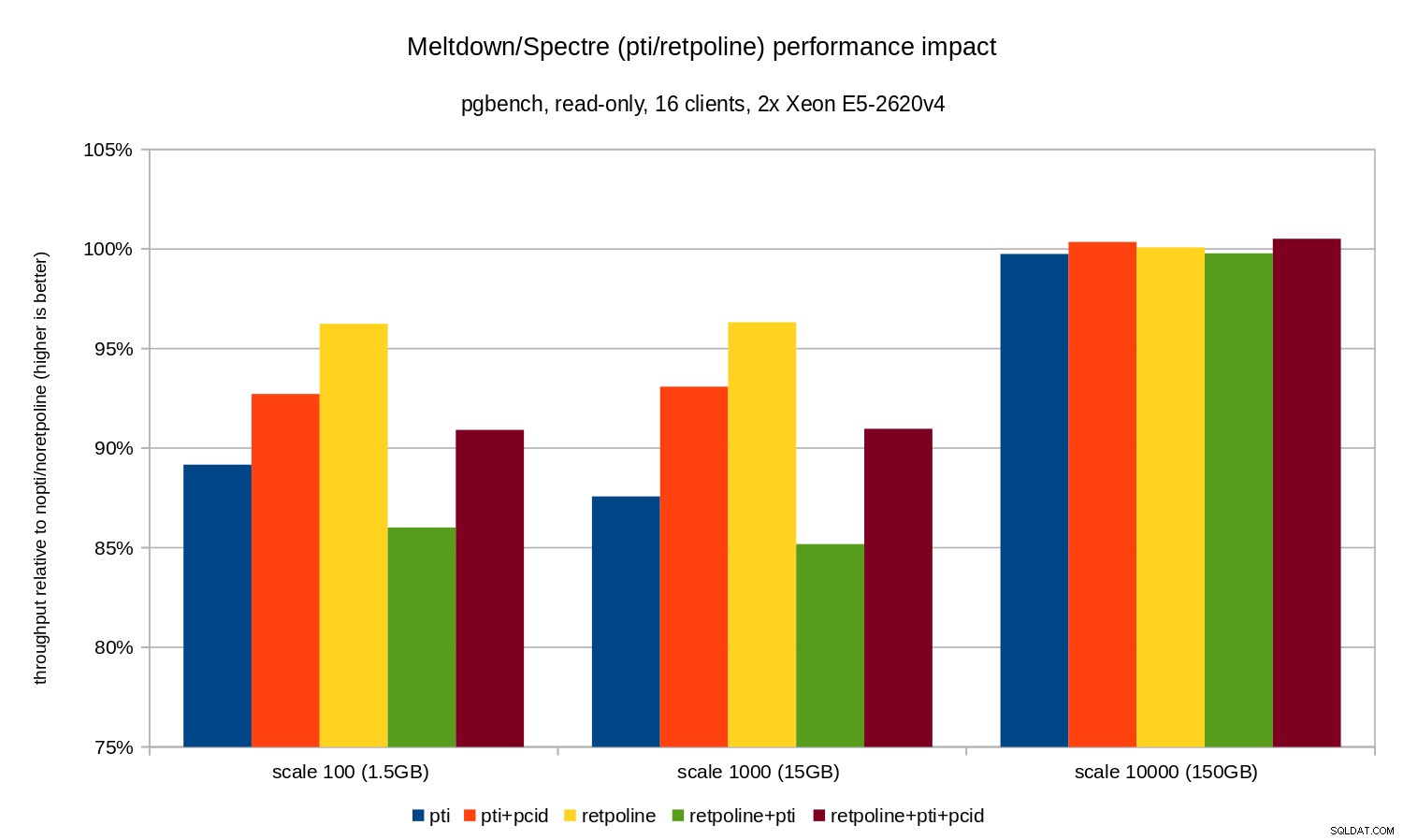
Wie Sie sehen können, sind die Leistungsauswirkungen von pti für Skalen, die in den Speicher passen, beträgt ungefähr 10-12 % und ist fast nicht messbar, wenn die Arbeitslast E/A-gebunden wird. Außerdem wird die Regression deutlich reduziert (oder verschwindet ganz), wenn pcid aktiviert. Dies steht im Einklang mit der Behauptung, dass PCID jetzt ein kritisches Leistungs-/Sicherheitsfeature auf x86 ist. Die Auswirkungen von retpoline ist viel kleiner – im schlimmsten Fall weniger als 4 %, was leicht auf Rauschen zurückzuführen sein kann.
OLTP/Lesen-Schreiben
Die Lese-Schreib-Tests wurden von einer pgbench durchgeführt Befehl ähnlich diesem:
pgbench -n -c 16 -j 16 -N -T 3600 test
Die Dauer war lang genug, um mehrere Checkpoints und -N abzudecken wurde verwendet, um Sperrkonflikte bei Zeilen in der (winzigen) Verzweigungstabelle zu beseitigen. Die relative Leistung wird durch dieses Diagramm veranschaulicht:
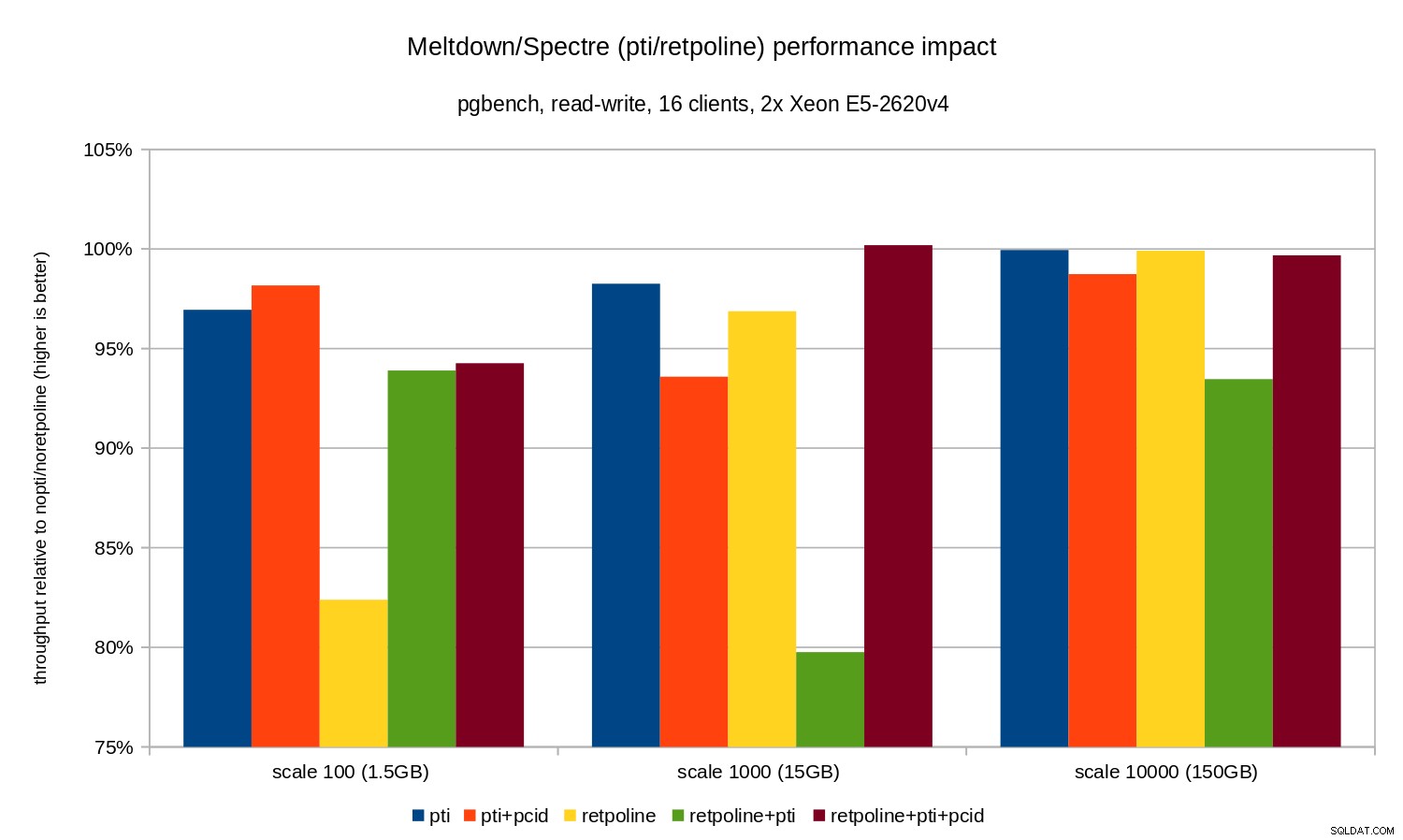
Die Regressionen sind etwas kleiner als im Nur-Lese-Fall – weniger als 8 % ohne pcid und weniger als 3 % mit pcid aktiviert. Dies ist eine natürliche Folge davon, dass mehr Zeit mit I/O-Vorgängen verbracht wird, während Daten in WAL geschrieben werden, geänderte Puffer während Checkpoints geleert werden usw.
Es gibt jedoch zwei seltsame Bits. Erstens die Auswirkungen von retpoline ist für den Maßstab 100 unerwartet groß (nahezu 20 %), und dasselbe geschah für retpoline+pti auf der Skala 1000. Die Gründe sind nicht ganz klar und bedürfen weiterer Untersuchungen.
OLAP
Die Analyse-Workload wurde durch den dbt-3-Benchmark modelliert. Schauen wir uns zunächst die 10-GB-Ergebnisse an, die vollständig in den Arbeitsspeicher passen (einschließlich aller Indizes usw.). Ähnlich wie bei OLTP sind wir nicht wirklich an absoluten Zahlen interessiert, die in diesem Fall die Dauer für einzelne Abfragen wären. Stattdessen betrachten wir die Verlangsamung im Vergleich zu nopti/noretpoline , das heißt:
(duration without patches) / (duration with patches)
Unter der Annahme, dass die Minderungen zu einer Verlangsamung führen, erhalten wir Werte zwischen 0 % und 100 %, wobei 100 % „keine Auswirkung“ bedeutet. Die Ergebnisse sehen so aus:
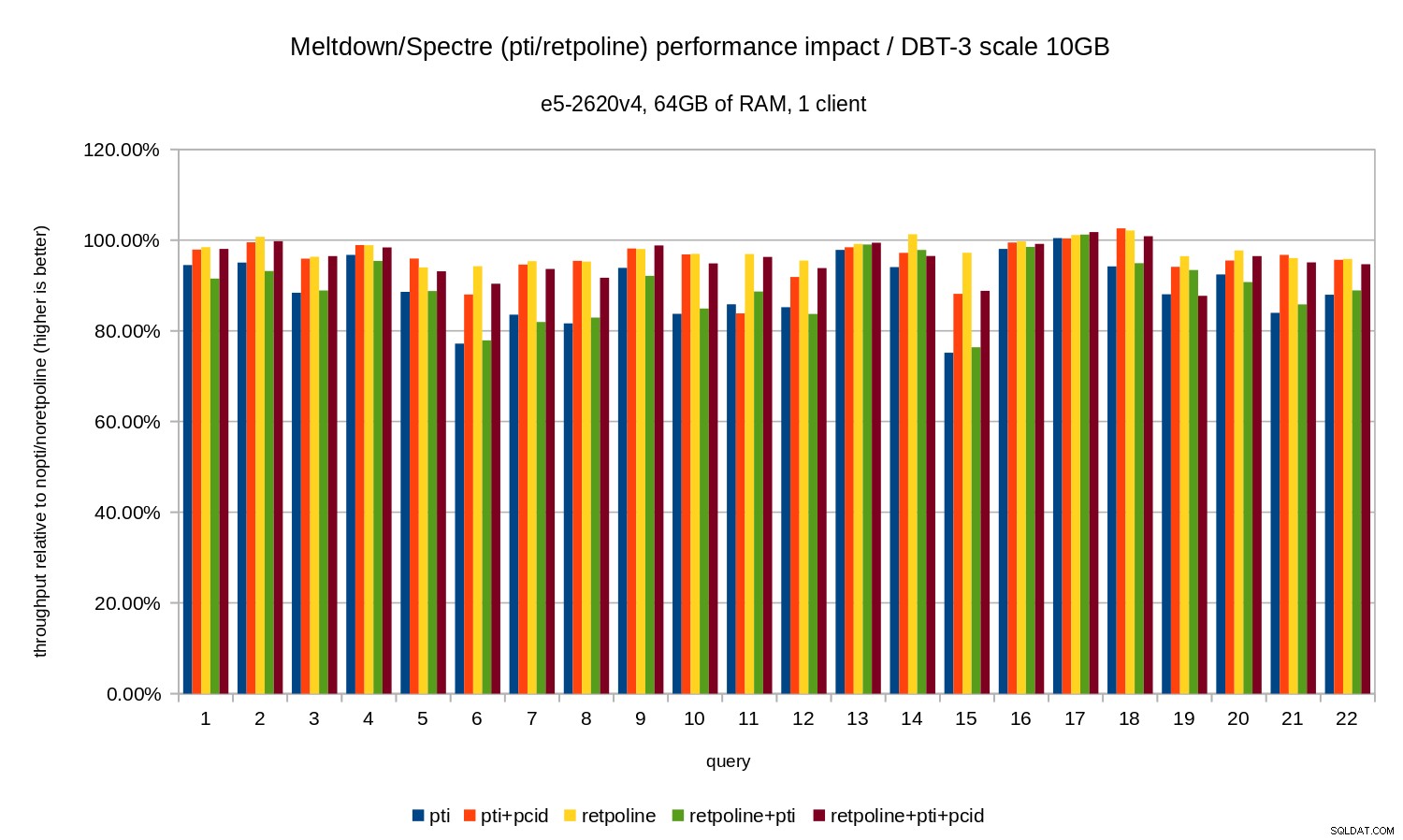
Das heißt, ohne pcid die Regression liegt in der Regel im Bereich von 10-20 %, je nach Abfrage. Und mit pcid die Regression fällt auf weniger als 5 % (und im Allgemeinen nahe 0 %). Dies bestätigt einmal mehr die Wichtigkeit von pcid Funktion.
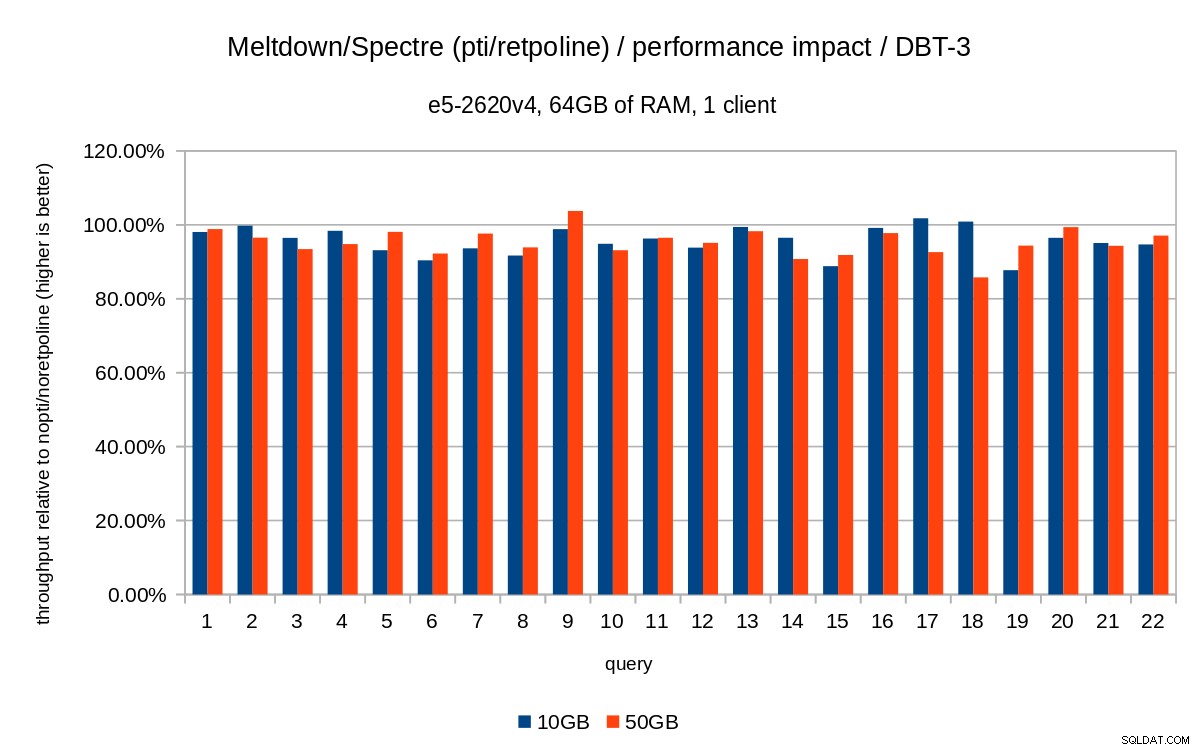
Für den 50-GB-Datensatz (das sind etwa 120 GB mit allen Indizes usw.) sehen die Auswirkungen so aus:
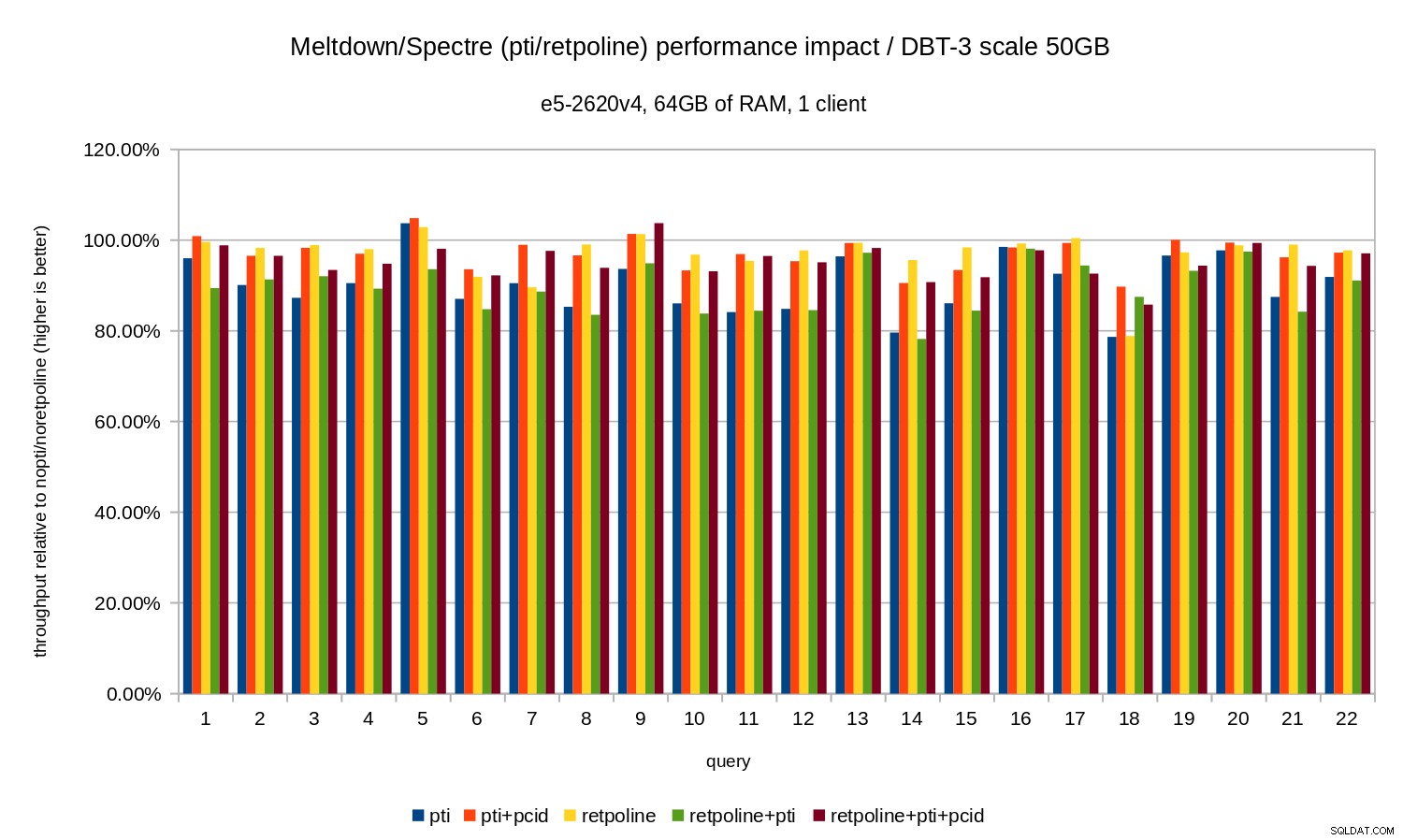
Genau wie im 10-GB-Fall liegen die Regressionen also unter 20 % und pcid deutlich reduziert – in den meisten Fällen nahe 0 %.
Die vorherigen Diagramme sind etwas überladen – es gibt 22 Abfragen und 5 Datenreihen, was für ein einzelnes Diagramm etwas zu viel ist. Hier ist also ein Diagramm, das die Auswirkungen nur für alle drei Funktionen zeigt (pti , pcid und retpoline ), für beide Datensatzgrößen.
Schlussfolgerung
Um die Ergebnisse kurz zusammenzufassen:
retpolinehat sehr geringe Auswirkungen auf die Leistung- OLTP – die Regression beträgt ungefähr 10–15 % ohne
pcid, und etwa 1-5 % mitpcid. - OLAP – die Regression beträgt bis zu 20 % ohne
pcid, und etwa 1-5 % mitpcid. - Für I/O-gebundene Workloads (z. B. OLTP mit dem größten Datensatz) hat Meltdown vernachlässigbare Auswirkungen.
Die Auswirkungen scheinen zumindest für die getesteten Workloads viel geringer zu sein als anfängliche Schätzungen vermuten lassen (30 %). Viele Systeme arbeiten zu Spitzenzeiten mit 70-80 % CPU, und die 30 % würden die CPU-Kapazität vollständig auslasten. Aber in der Praxis scheint die Auswirkung unter 5 % zu liegen, zumindest wenn die pcid Option verwendet wird.
Verstehen Sie mich nicht falsch, ein Rückgang um 5 % ist immer noch eine ernsthafte Regression. Es ist sicherlich etwas, um das wir uns während der PostgreSQL-Entwicklung kümmern würden, z. bei der Bewertung der Auswirkungen vorgeschlagener Patches. Aber es ist etwas, was vorhandene Systeme problemlos bewältigen sollten – wenn eine 5 %ige Erhöhung der CPU-Auslastung Ihr System über den Rand bringt, haben Sie Probleme, sogar ohne Meltdown/Spectre.
Dies ist natürlich nicht das Ende der Meltdown/Spectre-Korrekturen. Kernel-Entwickler arbeiten noch daran, den Schutz zu verbessern und neue hinzuzufügen, und Intel und andere CPU-Hersteller arbeiten an Microcode-Updates. Und es ist nicht so, dass wir alle möglichen Varianten der Schwachstellen kennen, da es Forschern gelang, neue Varianten der Angriffe zu finden.
Es wird also noch mehr kommen und es wird interessant sein zu sehen, wie sich dies auf die Leistung auswirken wird.



