Und jetzt kommen wir zum zweiten Artikel in unserer Serie Migration von Oracle zu PostgreSQL. Dieses Mal werfen wir einen Blick auf den START WITH/CONNECT BY konstruieren.
In Oracle START WITH/CONNECT BY wird verwendet, um eine einfach verknüpfte Listenstruktur zu erstellen, die bei einer bestimmten Sentinel-Zeile beginnt. Die verknüpfte Liste kann die Form eines Baums annehmen und hat keine Ausgleichsanforderungen.
Beginnen wir zur Veranschaulichung mit einer Abfrage und nehmen an, dass die Tabelle 5 Zeilen enthält.
SELECT * FROM person;
last_name | first_name | id | parent_id
------------+------------+----+-----------
Dunstan | Andrew | 1 | (null)
Roybal | Kirk | 2 | 1
Riggs | Simon | 3 | 1
Eisentraut | Peter | 4 | 1
Thomas | Shaun | 5 | 3
(5 rows)Hier ist die hierarchische Abfrage der Tabelle mit Oracle-Syntax.
select id, parent_id
from person
start with parent_id IS NULL
connect by prior id = parent_id;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3Und hier wird wieder PostgreSQL verwendet.
WITH RECURSIVE a AS (
SELECT id, parent_id
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT id, parent_id FROM a;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3
(5 rows)Diese Abfrage nutzt viele PostgreSQL-Funktionen, gehen wir sie also langsam durch.
WITH RECURSIVE
Dies ist ein „Common Table Expression“ (CTE). Es definiert eine Reihe von Abfragen, die in derselben Anweisung ausgeführt werden, nicht nur in derselben Transaktion. Sie können eine beliebige Anzahl von Ausdrücken in Klammern und eine abschließende Anweisung haben. Für diese Verwendung benötigen wir nur einen. Indem Sie diese Anweisung als RECURSIVE deklarieren , wird es iterativ ausgeführt, bis keine Zeilen mehr zurückgegeben werden.
SELECT
UNION ALL
SELECTDies ist ein vorgeschriebener Ausdruck für eine rekursive Abfrage. Es ist in der Dokumentation als Methode zur Unterscheidung von Startpunkt und Rekursionsalgorithmus definiert. In Oracle-Begriffen können Sie sich diese als die Klausel START WITH zusammen mit der Klausel CONNECT BY vorstellen.
JOIN a ON a.id = d.parent_idDies ist eine Selbstverknüpfung mit der CTE-Anweisung, die die vorherigen Zeilendaten für die nachfolgende Iteration bereitstellt.
Um zu veranschaulichen, wie dies funktioniert, fügen wir der Abfrage einen Iterationsindikator hinzu.
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT * FROM a;
id | parent_id | recursion_level
----+-----------+-----------------
1 | (null) | 1
4 | 1 | 2
3 | 1 | 2
2 | 1 | 2
5 | 3 | 3
(5 rows)Wir initialisieren den Rekursionsstufenindikator mit einem Wert. Beachten Sie, dass in den zurückgegebenen Zeilen die erste Rekursionsebene nur einmal vorkommt. Das liegt daran, dass die erste Klausel nur einmal ausgeführt wird.
In der zweiten Klausel geschieht die iterative Magie. Hier haben wir Sichtbarkeit der vorherigen Zeilendaten zusammen mit den aktuellen Zeilendaten. Dadurch können wir die rekursiven Berechnungen durchführen.
Simon Riggs hat ein sehr schönes Video darüber, wie man diese Funktion für das Design von Graphdatenbanken verwendet. Es ist sehr informativ und Sie sollten es sich ansehen.

Sie haben vielleicht bemerkt, dass diese Abfrage zu einer Zirkelbedingung führen kann. Das ist richtig. Es ist Sache des Entwicklers, der zweiten Abfrage eine einschränkende Klausel hinzuzufügen, um diese endlose Rekursion zu verhindern. Zum Beispiel nur 4 Ebenen tief wiederholen, bevor man einfach aufgibt.
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level --<-- initialize it here
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1 --<-- iteration increment
FROM person d
JOIN a ON a.id = d.parent_id
WHERE d.recursion_level <= 4 --<-- bail out here
) SELECT * FROM a;
Die Spaltennamen und Datentypen werden durch die erste Klausel bestimmt. Beachten Sie, dass das Beispiel einen Casting-Operator für die Rekursionsebene verwendet. In einem sehr tiefen Diagramm könnte dieser Datentyp auch als 1::bigint recursion_level definiert werden .
Dieser Graph lässt sich sehr einfach mit einem kleinen Shell-Skript und dem Dienstprogramm graphviz visualisieren.
#!/bin/bash -
#===============================================================================
#
# FILE: pggraph
#
# USAGE: ./pggraph
#
# DESCRIPTION:
#
# OPTIONS: ---
# REQUIREMENTS: ---
# BUGS: ---
# NOTES: ---
# AUTHOR: Kirk Roybal (), example@sqldat.com
# ORGANIZATION:
# CREATED: 04/21/2020 14:09
# REVISION: ---
#===============================================================================
set -o nounset # Treat unset variables as an error
dbhost=localhost
dbport=5432
dbuser=$USER
dbname=$USER
ScriptVersion="1.0"
output=$(basename $0).dot
#=== FUNCTION ================================================================
# NAME: usage
# DESCRIPTION: Display usage information.
#===============================================================================
function usage ()
{
cat <<- EOT
Usage : ${0##/*/} [options] [--]
Options:
-h|host name Database Host Name default:localhost
-n|name name Database Name default:$USER
-o|output file Output file default:$output.dot
-p|port number TCP/IP port default:5432
-u|user name User name default:$USER
-v|version Display script version
EOT
} # ---------- end of function usage ----------
#-----------------------------------------------------------------------
# Handle command line arguments
#-----------------------------------------------------------------------
while getopts ":dh:n:o:p:u:v" opt
do
case $opt in
d|debug ) set -x ;;
h|host ) dbhost="$OPTARG" ;;
n|name ) dbname="$OPTARG" ;;
o|output ) output="$OPTARG" ;;
p|port ) dbport=$OPTARG ;;
u|user ) dbuser=$OPTARG ;;
v|version ) echo "$0 -- Version $ScriptVersion"; exit 0 ;;
\? ) echo -e "\n Option does not exist : $OPTARG\n"
usage; exit 1 ;;
esac # --- end of case ---
done
shift $(($OPTIND-1))
[[ -f "$output" ]] && rm "$output"
tee "$output" <<eof< span="">
digraph g {
node [shape=rectangle]
rankdir=LR
EOF
psql -h $dbhost -U $dbuser -d $dbname -p $dbport -qtAf cte.sql |
sed -e 's/^/node/' -e 's/.*(null)|/node/' -e 's/^/\t/' -e 's/|[[:digit:]]*$//' |
sed -e 's/|/ -> node/' | tee -a "$output"
tee -a "$output" <<eof< span="">
}
EOF
dot -Tpng "$output" > "${output/dot/png}"
[[ -f "$output" ]] && rm "$output"
open "${output/dot/png}"</eof<></eof<>Dieses Skript erfordert diese SQL-Anweisung in einer Datei namens cte.sql
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT parent_id, id, recursion_level FROM a;Dann rufst du es so auf:
chmod +x pggraph
./pggraphUnd Sie werden das resultierende Diagramm sehen.

INSERT INTO person (id, parent_id) VALUES (6,2);Führen Sie das Dienstprogramm erneut aus und sehen Sie sich die sofortigen Änderungen an Ihrem gerichteten Graphen an:

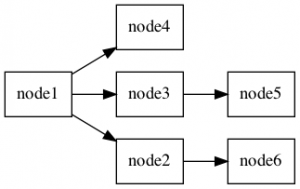
Nun, das war jetzt nicht so schwer, oder?