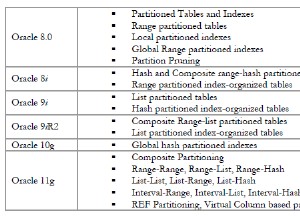
Einige Probleme stechen hervor:
Erwägen Sie zunächst ein Upgrade auf eine aktuelle Version von Postgres . Zum Zeitpunkt des Schreibens ist das Seite 9.6 oder Seite 10 (derzeit Beta). Seit Pg 9.4 gibt es zahlreiche Verbesserungen für GIN-Indizes, das Zusatzmodul pg_trgm und Big Data im Allgemeinen.
Als nächstes benötigen Sie viel mehr RAM , insbesondere ein höheres work_mem Einstellung. Das erkenne ich an dieser Zeile im EXPLAIN Ausgabe:
Heap Blocks: exact=7625 lossy=223807
"verlustbehaftet" in den Details für einen Bitmap-Heap-Scan (mit Ihren konkreten Zahlen) weist auf einen dramatischen Mangel an work_mem hin . Postgres sammelt nur Blockadressen im Bitmap-Index-Scan anstelle von Zeilenzeigern, da dies mit Ihrem niedrigen work_mem voraussichtlich schneller ist Einstellung (kann keine genauen Adressen im RAM halten). Im folgenden Bitmap Heap Scan müssen viele weitere nicht qualifizierende Zeilen gefiltert werden Hier entlang. Diese verwandte Antwort enthält Details:
Aber setzen Sie work_mem nicht auch hoch, ohne die Gesamtsituation zu berücksichtigen:
Es können andere Probleme wie aufgeblähte Indizes oder Tabellen oder weitere Konfigurationsengpässe auftreten. Aber wenn Sie nur diese beiden Elemente korrigieren, sollte die Abfrage viel lauten schon schneller.
Müssen Sie wirklich alle 40.000 Zeilen im Beispiel abrufen? Wahrscheinlich möchten Sie ein kleines LIMIT hinzufügen zu der Abfrage hinzufügen und daraus eine Suche nach dem "nächsten Nachbarn" machen - in diesem Fall ist ein GiST-Index schließlich die bessere Wahl, weil das soll mit einem GiST-Index schneller sein. Beispiel: