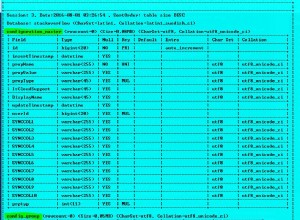
Zähle alle Zeilen
SELECT date, '1_D' AS time_series, count(DISTINCT user_id) AS cnt
FROM uniques
GROUP BY 1
UNION ALL
SELECT DISTINCT ON (1)
date, '2_W', count(*) OVER (PARTITION BY week_beg ORDER BY date)
FROM uniques
UNION ALL
SELECT DISTINCT ON (1)
date, '3_M', count(*) OVER (PARTITION BY month_beg ORDER BY date)
FROM uniques
ORDER BY 1, time_series
-
Ihre Spalten
week_begundmonth_begsind 100 % redundant und können einfach durchdate_trunc('week', date + 1) - 1ersetzt werden unddate_trunc('month', date)bzw.. -
Ihre Woche scheint am Sonntag (off by one) zu beginnen, daher der
+ 1 .. - 1. -
Der Standardrahmen einer Fensterfunktion mit
ORDER BYimOVERKlausel verwendet istRANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Genau das brauchen Sie. -
Verwenden Sie
UNION ALL, nichtUNION. -
Ihre unglückliche Wahl für
time_series(D, W, M) sortiert nicht gut, ich habe umbenannt, um den endgültigenORDER BYzu machen einfacher. -
Diese Abfrage kann mehrere Zeilen pro Tag verarbeiten. Zählt alle Peers für einen Tag.
-
Mehr über
DISTINCT ON:
DISTINCT Nutzer pro Tag
Um jeden Benutzer nur einmal pro Tag zu zählen, verwenden Sie einen CTE mit DISTINCT ON :
WITH x AS (SELECT DISTINCT ON (1,2) date, user_id FROM uniques)
SELECT date, '1_D' AS time_series, count(user_id) AS cnt
FROM x
GROUP BY 1
UNION ALL
SELECT DISTINCT ON (1)
date, '2_W'
,count(*) OVER (PARTITION BY (date_trunc('week', date + 1)::date - 1)
ORDER BY date)
FROM x
UNION ALL
SELECT DISTINCT ON (1)
date, '3_M'
,count(*) OVER (PARTITION BY date_trunc('month', date) ORDER BY date)
FROM x
ORDER BY 1, 2
DISTINCT Nutzer über einen dynamischen Zeitraum
Sie können jederzeit auf korrelierte Unterabfragen zurückgreifen . Neigen dazu, bei großen Tabellen langsam zu sein!
Aufbauend auf den vorherigen Abfragen:
WITH du AS (SELECT date, user_id FROM uniques GROUP BY 1,2)
,d AS (
SELECT date
,(date_trunc('week', date + 1)::date - 1) AS week_beg
,date_trunc('month', date)::date AS month_beg
FROM uniques
GROUP BY 1
)
SELECT date, '1_D' AS time_series, count(user_id) AS cnt
FROM du
GROUP BY 1
UNION ALL
SELECT date, '2_W', (SELECT count(DISTINCT user_id) FROM du
WHERE du.date BETWEEN d.week_beg AND d.date )
FROM d
GROUP BY date, week_beg
UNION ALL
SELECT date, '3_M', (SELECT count(DISTINCT user_id) FROM du
WHERE du.date BETWEEN d.month_beg AND d.date)
FROM d
GROUP BY date, month_beg
ORDER BY 1,2;
SQL-Fiddle für alle drei Lösungen.
Schneller mit dense_rank()
@Clodoaldo
kam mit einer großen Verbesserung:Verwenden Sie die Fensterfunktion dense_rank()
. Hier ist eine weitere Idee für eine optimierte Version. Es sollte noch schneller gehen, tägliche Duplikate sofort auszuschließen. Der Leistungsgewinn wächst mit der Anzahl der Zeilen pro Tag.
Aufbauend auf einem vereinfachten und bereinigten Datenmodell - ohne die überflüssigen Spalten - day als Spaltenname anstelle von date
date ist ein reserviertes Wort in Standard-SQL
und ein einfacher Typname in PostgreSQL und sollte nicht als Bezeichner verwendet werden.
CREATE TABLE uniques(
day date -- instead of "date"
,user_id int
);
Verbesserte Abfrage:
WITH du AS (
SELECT DISTINCT ON (1, 2)
day, user_id
,date_trunc('week', day + 1)::date - 1 AS week_beg
,date_trunc('month', day)::date AS month_beg
FROM uniques
)
SELECT day, count(user_id) AS d, max(w) AS w, max(m) AS m
FROM (
SELECT user_id, day
,dense_rank() OVER(PARTITION BY week_beg ORDER BY user_id) AS w
,dense_rank() OVER(PARTITION BY month_beg ORDER BY user_id) AS m
FROM du
) s
GROUP BY day
ORDER BY day;
SQL-Fiddle
demonstriert die Leistung von 4 schnelleren Varianten. Es hängt von Ihrer Datenverteilung ab, welche für Sie am schnellsten ist.
Alle sind etwa 10x so schnell wie die Version mit korrelierten Unterabfragen (was für korrelierte Unterabfragen nicht schlecht ist).