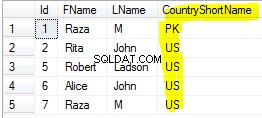
Den Fahrgast mit dem längsten Namen pro Gruppe können Sie bequem mit DISTINCT ON abrufen .
Aber ich sehe keine Möglichkeit, dies (oder eine andere einfache Möglichkeit) mit Ihrer ursprünglichen Abfrage in einem einzigen SELECT zu kombinieren . Ich schlage vor, zwei separate Unterabfragen zu verbinden:
SELECT *
FROM ( -- your original query
SELECT orig
, count(*) AS flight_cnt
, count(distinct passenger) AS pass_cnt
, percentile_cont(0.5) WITHIN GROUP (ORDER BY bags) AS bag_cnt_med
FROM table1
GROUP BY orig
) org_query
JOIN ( -- my addition
SELECT DISTINCT ON (orig) orig, passenger AS pass_max_len_name
FROM table1
ORDER BY orig, length(passenger) DESC NULLS LAST
) pas USING (orig);
USING in der join-Klausel gibt praktischerweise nur eine Instanz von orig aus , sodass Sie einfach SELECT * verwenden können im äußeren SELECT .
Wenn passenger NULL sein kann, ist es wichtig, NULLS LAST hinzuzufügen :
Aus mehreren Passagiernamen mit gleicher Maximallänge in derselben Gruppe erhalten Sie eine beliebige Auswahl - es sei denn, Sie fügen ORDER BY weitere Ausdrücke hinzu als Tiebreak. Ausführliche Erklärung in der oben verlinkten Antwort.
Leistung?
In der Regel ist ein einzelner Scan überlegen, insbesondere bei sequentiellen Scans.
Die obige Abfrage verwendet zwei Scans (vielleicht Index-/Nur-Index-Scans). Aber der zweite Scan ist vergleichsweise billig, es sei denn, die Tabelle ist zu groß, um (meistens) in den Cache zu passen. Lukas schlug eine alternative Abfrage mit nur einer einzelnen vor SELECT
Hinzufügen:
, (ARRAY_AGG (passenger ORDER BY LENGTH (passenger) DESC))[1] -- I'd add NULLS LAST
Die Idee ist schlau, aber habe ich zuletzt getestet
, array_agg mit ORDER BY lief nicht so gut. (Der Overhead von ORDER BY pro Gruppe ist beträchtlich, und die Handhabung von Arrays ist ebenfalls teuer.)
Derselbe Ansatz kann mit einer benutzerdefinierten Aggregatfunktion first() billiger sein wie hier im Postgres-Wiki beschrieben
. Oder, noch schneller, mit einer in C geschriebenen Version, verfügbar auf PGXN
. Eliminiert die zusätzlichen Kosten für die Handhabung von Arrays, aber wir brauchen immer noch pro Gruppe ORDER BY . Kann schneller sein für nur wenige Gruppen. Sie würden dann hinzufügen:
, first(passenger ORDER BY length(passenger) DESC NULLS LAST)
Gordon
und Lukas
erwähnen Sie auch die Fensterfunktion first_value()
. Fensterfunktionen werden nach angewendet aggregierte Funktionen. Um es im selben SELECT zu verwenden , müssten wir passenger aggregieren irgendwie first - catch 22. Gordon löst dies mit einer Unterabfrage - ein weiterer Kandidat für eine gute Leistung mit Standard-Postgres.
first() macht dasselbe ohne Unterabfrage und sollte einfacher und etwas schneller sein. Aber es wird immer noch nicht schneller sein als ein separates DISTINCT ON in den meisten Fällen mit wenigen Zeilen pro Gruppe. Für viele Zeilen pro Gruppe ist eine rekursive CTE-Technik typischerweise schneller. Es gibt noch schnellere Techniken, wenn Sie eine separate Tabelle haben, die alle relevanten, eindeutigen orig enthält Werte. Einzelheiten:
Die beste Lösung hängt von verschiedenen Faktoren ab. Probieren geht über Studieren. Um die Leistung zu optimieren, müssen Sie mit Ihrem Setup testen. Die obige Abfrage sollte zu den schnellsten gehören.