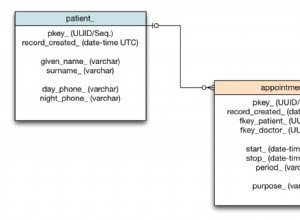
Einfacher, kürzer, schneller mit DISTINCT ON von PostgreSQL :
SELECT DISTINCT ON (a.id)
a.id, a.name, a.date, b.code1, b.code2
FROM table_a a
LEFT JOIN table_b b USING (id)
ORDER BY a.id, b.sort
Details, Erläuterungen, Benchmarks und Links in dieser eng verwandten Antwort
.
Ich verwende einen LEFT JOIN , sodass Zeilen aus table_a ohne übereinstimmende Zeile in table_b werden nicht gelöscht.
Randbemerkungen:
Obwohl es in PostgreSQL erlaubt ist, ist es unklug, date zu verwenden als Spaltenname. Es ist ein reserviertes Wort
in jedem SQL-Standard und ein Typname in PsotgreSQL.
Es ist auch ein Anti-Muster, eine ID-Spalte id zu benennen . Nicht beschreibend und nicht hilfreich. Eine (von vielen) möglichen Namenskonventionen wäre, sie nach der Tabelle zu benennen, in der sie der Primärschlüssel ist:table_a_id . Gleicher Name für darauf verweisende Fremdschlüssel (wenn kein anderer natürlicher Name Vorrang hat).