LIMIT auf SQL-Ebene
Um die Größe der Ergebnismenge der SQL-Abfrage einzuschränken, können Sie die SQL:008-Syntax verwenden:
SELECT title
FROM post
ORDER BY created_on DESC
OFFSET 50 ROWS
FETCH NEXT 50 ROWS ONLY
das auf Oracle 12, SQL Server 2012 oder PostgreSQL 8.4 oder neueren Versionen funktioniert.
Für MySQL können Sie die LIMIT- und OFFSET-Klauseln verwenden:
SELECT title
FROM post
ORDER BY created_on DESC
LIMIT 50
OFFSET 50
Der Vorteil der Paginierung auf SQL-Ebene besteht darin, dass der Ausführungsplan der Datenbank diese Informationen verwenden kann.
Wenn wir also einen Index auf created_on haben Spalte:
CREATE INDEX idx_post_created_on ON post (created_on DESC)
Und wir führen die folgende Abfrage aus, die das LIMIT verwendet Klausel:
EXPLAIN ANALYZE
SELECT title
FROM post
ORDER BY created_on DESC
LIMIT 50
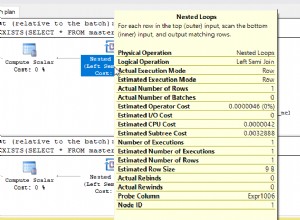
Wir können sehen, dass die Datenbank-Engine den Index verwendet, da der Optimierer weiß, dass nur 50 Datensätze abgerufen werden müssen:
Execution plan:
Limit (cost=0.28..25.35 rows=50 width=564)
(actual time=0.038..0.051 rows=50 loops=1)
-> Index Scan using idx_post_created_on on post p
(cost=0.28..260.04 rows=518 width=564)
(actual time=0.037..0.049 rows=50 loops=1)
Planning time: 1.511 ms
Execution time: 0.148 ms
JDBC-Anweisung maxRows
Gemäß dem setMaxRows Javadoc
:
Das ist nicht sehr beruhigend!
Wenn wir also die folgende Abfrage auf PostgreSQL ausführen:
try (PreparedStatement statement = connection
.prepareStatement("""
SELECT title
FROM post
ORDER BY created_on DESC
""")
) {
statement.setMaxRows(50);
ResultSet resultSet = statement.executeQuery();
int count = 0;
while (resultSet.next()) {
String title = resultSet.getString(1);
count++;
}
}
Wir erhalten den folgenden Ausführungsplan im PostgreSQL-Protokoll:
Execution plan:
Sort (cost=65.53..66.83 rows=518 width=564)
(actual time=4.339..5.473 rows=5000 loops=1)
Sort Key: created_on DESC
Sort Method: quicksort Memory: 896kB
-> Seq Scan on post p (cost=0.00..42.18 rows=518 width=564)
(actual time=0.041..1.833 rows=5000 loops=1)
Planning time: 1.840 ms
Execution time: 6.611 ms
Da der Datenbankoptimierer keine Ahnung hat, dass wir nur 50 Datensätze abrufen müssen, geht er davon aus, dass alle 5000 Zeilen gescannt werden müssen. Wenn eine Abfrage eine große Anzahl von Datensätzen abrufen muss, sind die Kosten für einen vollständigen Tabellenscan tatsächlich niedriger als bei Verwendung eines Index, daher verwendet der Ausführungsplan den Index überhaupt nicht.
Schlussfolgerung
Obwohl es wie setMaxRows aussieht ist eine portable Lösung, um die Größe des ResultSet zu begrenzen , ist die Paginierung auf SQL-Ebene viel effizienter, wenn der Datenbankserver-Optimierer die JDBC-maxRows nicht verwendet Eigentum.