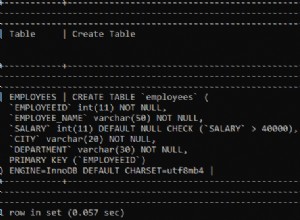
Hey, ich würde vorschlagen, den folgenden Prozess zu verwenden:
1- Identifizieren Sie, wenn eine Zeile neu ist, also geben Sie den Werten, die sich nicht überschneiden, den Wert 1 (CTE b)
2- Sequenzieren Sie die Reihen, die sich mit anderen überschneiden. Auf diese Weise können Sie sehen, dass Sie einen gemeinsamen Bezeichner haben, der es Ihnen ermöglicht, MAX und MIN zu beginnen und zu beenden (CTE c)
3- Geben Sie für jede Sequenz das MIN von begat und das MAX von endat an, damit Sie Ihre endgültigen Werte haben
WITH a AS (
select '2017-09-16 07:12:57' as begat,'2017-09-16 11:30:22' as endat
union
select '2017-09-18 17:05:21' ,'2017-09-19 13:18:01'
union
select '2017-09-19 15:34:40' ,'2017-09-22 13:29:37'
union
select '2017-09-22 12:24:16' ,'2017-09-22 13:18:29'
union
select '2017-09-28 09:48:54' ,'2017-09-28 13:39:13'
union
select '2017-09-20 13:52:43' ,'2017-09-20 14:14:43'
)
, b AS (
SELECT
begat
, endat
, (begat > MAX(endat) OVER w IS TRUE)::INT is_new
FROM a
WINDOW w AS (ORDER BY begat ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING)
)
, c AS (
SELECT
begat
, endat
, SUM((is_new)) OVER (ORDER BY begat) seq
FROM b
)
SELECT
MIN(begat) beg_at
, MAX(endat) end_at
FROM c
GROUP BY seq