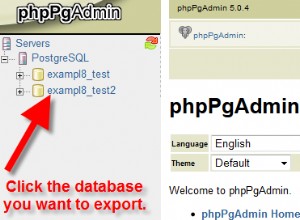
Schritt 1:Lösen Sie die Handbremsen
SELECT to_char(MIN(ts)::timestamptz, 'YYYY-MM-DD HH24:MI:SS TZ') AS min_time
,SUM(CASE WHEN sensor_id = 572 THEN value ELSE 0.0 END) AS nickname1
,SUM(CASE WHEN sensor_id = 542 THEN value ELSE 0.0 END) AS nickname2
,SUM(CASE WHEN sensor_id = 571 THEN value ELSE 0.0 END) AS nickname3
FROM sensor_values
-- LEFT JOIN sensor_values_cleaned s2 USING (sensor_id, ts)
WHERE ts >= '2013-10-14T00:00:00+00:00'::timestamptz::timestamp
AND ts < '2013-10-18T00:00:00+00:00'::timestamptz::timestamp
AND sensor_id IN (572, 542, 571, 540, 541, 573)
GROUP BY ts::date AS day
ORDER BY 1;
Wichtige Punkte
-
Ersetzen Sie reservierte Wörter (in Standard-SQL) in Ihren Bezeichnern.
timestamp->tstime->min_time -
Da der Join auf identischen Spaltennamen erfolgt, können Sie die einfacheren
USINGKlausel in der Join-Bedingung:USING (sensor_id, ts)
Aber seit der zweiten Tabellesensor_values_cleanedfür diese Abfrage zu 100 % irrelevant ist, habe ich sie vollständig entfernt. -
Wie @joop bereits empfohlen hat, schalten Sie
min()um undto_char()in Ihrer ersten Ausgabespalte. Auf diese Weise kann Postgres das Minimum aus dem ursprünglichen Spaltenwert ermitteln , die im Allgemeinen schneller ist und möglicherweise einen Index verwenden kann. In diesem speziellen Fall Bestellung nachdateist auch günstiger als die Bestellung pertext, die auch Kollatierungsregeln berücksichtigen müsste. -
Eine ähnliche Überlegung gilt für Ihr
WHEREBedingung:WHERE ts::timestamptz>='2013-10-14T00:00:00+00:00'::timestamptzWHERE ts >= '2013-10-14T00:00:00+00:00'::timestamptz::timestampDer zweite ist sargable und kann einen einfachen Index auf
tsverwenden - mit großer Wirkung auf die Leistung an großen Tischen! -
Verwenden von
ts::datestattdate_trunc('day', ts). Einfacher, schneller, gleiches Ergebnis. -
Höchstwahrscheinlich ist Ihre zweite WHERE-Bedingung leicht falsch. Im Allgemeinen würden Sie den oberen Rand ausschließen :
AND ts <= '2013-10-18T00:00:00+00:00' ...AND ts < '2013-10-18T00:00:00+00:00' ... -
Beim Mischen von
timestampundtimestamptzman muss sich der Wirkung bewusst sein. Zum Beispiel IhrWHEREBedingung schneidet nicht um 00:00 Ortszeit (außer wenn die Ortszeit mit UTC zusammenfällt). Details hier:
Zeitzonen in Rails und PostgreSQL komplett ignorieren
Schritt 2:Ihre Anfrage
Und damit meinen Sie vermutlich:
...den Unterschied zwischen dem Wert von die neuesten und frühesten Zeitstempel ...
Sonst wäre es viel einfacher.
Verwenden Sie Fensterfunktionen
dafür insbesondere first_value() und last_value() . Seien Sie vorsichtig mit der Kombination, Sie möchten einen non -Standard-Fensterrahmen
für last_value() in diesem Fall. Vergleichen Sie:
PostgreSQL-Aggregat oder Fensterfunktion, um nur den letzten Wert zurückzugeben
Ich kombiniere dies mit DISTINCT ON
, was in diesem Fall bequemer ist als GROUP BY (was eine andere Unterabfrageebene erfordern würde):
SELECT DISTINCT ON (ts::date, sensor_id)
ts::date AS day
,to_char((min(ts) OVER (PARTITION BY ts::date))::timestamptz
,'YYYY-MM-DD HH24:MI:SS TZ') AS min_time
,sensor_id
,last_value(value) OVER (PARTITION BY ts::date, sensor_id ORDER BY ts
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
- first_value(value) OVER (PARTITION BY ts::date, sensor_id ORDER BY ts)
AS val_range
FROM sensor_values
WHERE ts >= '2013-10-14T00:00:00+0'::timestamptz::timestamp
AND ts < '2013-10-18T00:00:00+0'::timestamptz::timestamp
AND sensor_id IN (540, 541, 542, 571, 572, 573)
ORDER BY ts::date, sensor_id;
Schritt 3:Pivot-Tabelle
Aufbauend auf der obigen Abfrage verwende ich crosstab()
aus dem Zusatzmodul tablefunc :
SELECT * FROM crosstab(
$$SELECT DISTINCT ON (1,3)
ts::date AS day
,to_char((min(ts) OVER (PARTITION BY ts::date))::timestamptz,'YYYY-MM-DD HH24:MI:SS TZ') AS min_time
,sensor_id
,last_value(value) OVER (PARTITION BY ts::date, sensor_id ORDER BY ts RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
- first_value(value) OVER (PARTITION BY ts::date, sensor_id ORDER BY ts) AS val_range
FROM sensor_values
WHERE ts >= '2013-10-14T00:00:00+0'::timestamptz::timestamp
AND ts < '2013-10-18T00:00:00+0'::timestamptz::timestamp
AND sensor_id IN (540, 541, 542, 571, 572, 573)
ORDER BY 1, 3$$
,$$VALUES (540), (541), (542), (571), (572), (573)$$
)
AS ct (day date, min_time text, s540 numeric, s541 numeric, s542 numeric, s571 numeric, s572 numeric, s573 numeric);
Retouren (und viel schneller als zuvor):
day | min_time | s540 | s541 | s542 | s571 | s572 | s573
------------+--------------------------+-------+-------+-------+-------+-------+-------
2013-10-14 | 2013-10-14 03:00:00 CEST | 18.82 | 18.98 | 19.97 | 19.47 | 17.56 | 21.27
2013-10-15 | 2013-10-15 00:15:00 CEST | 22.59 | 24.20 | 22.90 | 21.27 | 22.75 | 22.23
2013-10-16 | 2013-10-16 00:16:00 CEST | 23.74 | 22.52 | 22.23 | 23.22 | 23.03 | 22.98
2013-10-17 | 2013-10-17 00:17:00 CEST | 21.68 | 24.54 | 21.15 | 23.58 | 23.04 | 21.94