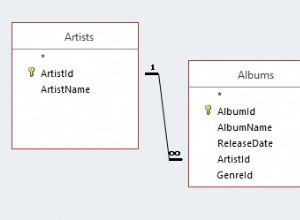
Wenn es viele Datensätze mit groupid=1886 gibt (aus dem Kommentar:Es gibt 200.563), um zu Datensätzen bei einem OFFSET einer sortierten Teilmenge von Zeilen zu gelangen, würde eine Sortierung (oder ein äquivalenter Heap-Algorithmus) erforderlich sein, was langsam ist.
Dies könnte durch Hinzufügen eines Index gelöst werden. In diesem Fall eine auf (groupid,id) und eine andere auf (groupid,created) .
Aus Kommentar:Dies hat tatsächlich geholfen und die Laufzeit auf 5 ms-10 ms verkürzt.