Wenn Sie an einem Projekt arbeiten, das aus vielen Microservices besteht, enthält es wahrscheinlich auch mehrere Datenbanken.
Beispielsweise könnten Sie eine MySQL-Datenbank und eine PostgreSQL-Datenbank haben, die beide auf separaten Servern laufen.
Um die Daten aus den beiden Datenbanken zusammenzuführen, müssten Sie normalerweise einen neuen Microservice einführen, der die Daten zusammenführt. Dies würde jedoch die Komplexität des Systems erhöhen.
In diesem Tutorial verwenden wir Materialise, um MySQL und Postgres in einer materialisierten Live-Ansicht zu verbinden. Wir können das dann direkt abfragen und Ergebnisse aus beiden Datenbanken in Echtzeit mit Standard-SQL zurückerhalten.
Materialise ist eine in Rust geschriebene, quellenverfügbare Streaming-Datenbank, die die Ergebnisse einer SQL-Abfrage (eine materialisierte Ansicht) im Speicher hält, wenn sich die Daten ändern.
Das Tutorial enthält ein Demoprojekt, das Sie mit docker-compose starten können .
Das Demoprojekt, das wir verwenden werden, überwacht die Bestellungen auf unserer Scheinwebsite. Es generiert Ereignisse, die später verwendet werden können, um Benachrichtigungen zu senden, wenn ein Einkaufswagen für längere Zeit aufgegeben wurde.
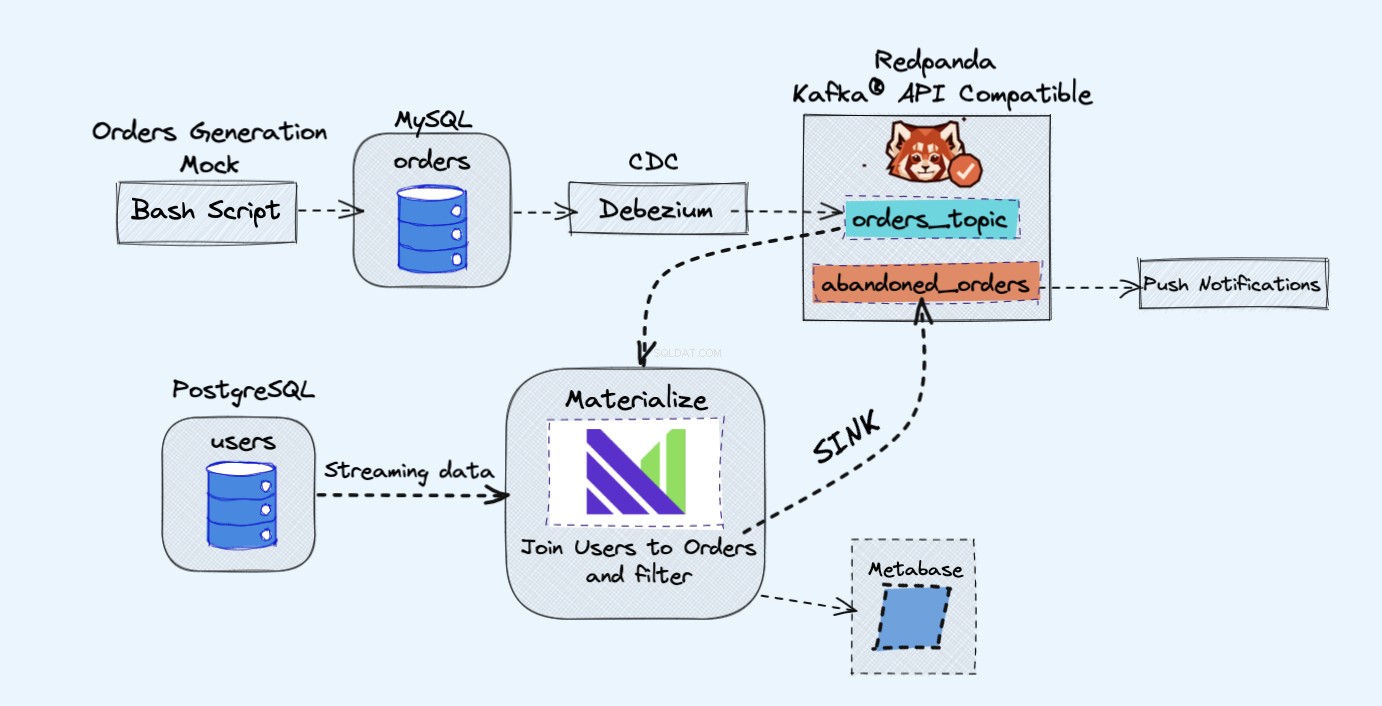
Die Architektur des Demoprojekts ist wie folgt:
Voraussetzungen
Alle Dienste, die wir in der Demo verwenden, werden in Docker-Containern ausgeführt, sodass Sie auf Ihrem Laptop oder Server keine zusätzlichen Dienste anstelle von Docker und Docker Compose installieren müssen.
Falls Sie Docker und Docker Compose noch nicht installiert haben, können Sie den offiziellen Anweisungen hier folgen:
- Installieren Sie Docker
- Installieren Sie Docker Compose
Übersicht
Wie im obigen Diagramm gezeigt, haben wir die folgenden Komponenten:
- Ein Scheindienst, um kontinuierlich Bestellungen zu generieren.
- Die Bestellungen werden in einer MySQL-Datenbank gespeichert .
- Während die Datenbankschreibvorgänge stattfinden, Debezium streamt die Änderungen von MySQL zu einem Redpanda Thema.
- Wir werden auch ein Postgres haben Datenbank, wo wir unsere Benutzer bekommen können.
- Wir nehmen dann dieses Redpanda-Thema in Materialise auf direkt zusammen mit den Benutzern aus der Postgres-Datenbank.
- In Materialise führen wir unsere Bestellungen und Benutzer zusammen, nehmen einige Filter vor und erstellen eine materialisierte Ansicht, die die Informationen zu verlassenen Warenkörben anzeigt.
- Wir werden dann eine Senke erstellen, um die verlassenen Einkaufswagendaten an ein neues Redpanda-Thema zu senden.
- Am Ende verwenden wir Metabase um die Daten zu visualisieren.
- Sie könnten später die Informationen aus diesem neuen Thema verwenden, um Benachrichtigungen an Ihre Benutzer zu senden und sie daran zu erinnern, dass sie einen verlassenen Einkaufswagen haben.
Als Randnotiz hier wäre es vollkommen in Ordnung, Kafka anstelle von Redpanda zu verwenden. Ich mag einfach die Einfachheit, die Redpanda auf den Tisch bringt, da Sie eine einzelne Redpanda-Instanz anstelle aller Kafka-Komponenten ausführen können.
So führen Sie die Demo aus
Beginnen Sie zunächst damit, das Repository zu klonen:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Danach können Sie auf das Verzeichnis zugreifen:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Beginnen wir damit, zuerst den Redpanda-Container auszuführen:
docker-compose up -d redpanda
Erstellen Sie die Bilder:
docker-compose build
Starten Sie abschließend alle Dienste:
docker-compose up -d
Um die Materialise CLI zu starten, können Sie den folgenden Befehl ausführen:
docker-compose run mzcli
Dies ist nur eine Verknüpfung zu einem Docker-Container mit postgres-client vorinstalliert. Wenn Sie bereits psql haben Sie könnten psql -U materialize -h localhost -p 6875 materialize ausführen stattdessen.
So erstellen Sie eine Materialise-Kafka-Quelle
Jetzt, da Sie sich in der Materialise CLI befinden, definieren wir die orders Tabellen im mysql.shop Datenbank als Redpanda-Quellen:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Wenn Sie die verfügbaren Spalten aus den orders überprüfen würden source, indem Sie die folgende Anweisung ausführen:
SHOW COLUMNS FROM orders;
Da Materialise die Nachrichtenschemadaten aus der Redpanda-Registrierung abruft, können Sie sehen, dass es die für jedes Attribut zu verwendenden Spaltentypen kennt:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
So erstellen Sie materialisierte Ansichten
Als Nächstes erstellen wir unsere erste Materialisierte Ansicht, um alle Daten aus den orders zu erhalten Redpanda-Quelle:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Sie können jetzt SELECT * FROM abandoned_orders; verwenden um die Ergebnisse zu sehen:
SELECT * FROM abandoned_orders;
Weitere Informationen zum Erstellen materialisierter Ansichten finden Sie im Abschnitt Materialisierte Ansichten der Materialise-Dokumentation.
So erstellen Sie eine Postgres-Quelle
Es gibt zwei Möglichkeiten, eine Postgres-Quelle in Materialise zu erstellen:
- Verwendung von Debezium, genau wie wir es mit der MySQL-Quelle gemacht haben.
- Verwenden der Postgres-Materialise-Quelle, mit der Sie Materialise direkt mit Postgres verbinden können, sodass Sie Debezium nicht verwenden müssen.
Für diese Demo verwenden wir die Postgres Materialise Source nur als Demonstration, wie man sie verwendet, aber Sie können stattdessen Debezium verwenden.
Um eine Postgres Materialise Source zu erstellen, führen Sie die folgende Anweisung aus:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Ein kurzer Überblick über die obige Aussage:
MATERIALIZED:Materialisiert die Daten der PostgreSQL-Quelle. Alle Daten bleiben im Speicher erhalten und machen Quellen direkt wählbar.mz_source:Der Name für die PostgreSQL-Quelle.CONNECTION:Die PostgreSQL-Verbindungsparameter.PUBLICATION:Die PostgreSQL-Publikation, die die Tabellen enthält, die an Materialise gestreamt werden sollen.
Nachdem wir die PostgreSQL-Quelle erstellt haben, müssten wir, um die PostgreSQL-Tabellen abfragen zu können, Ansichten erstellen, die die Originaltabellen der Upstream-Veröffentlichung darstellen.
In unserem Fall haben wir nur eine Tabelle namens users Die Anweisung, die wir ausführen müssten, lautet also:
CREATE VIEWS FROM SOURCE mz_source (users);
Um die verfügbaren Ansichten anzuzeigen, führen Sie die folgende Anweisung aus:
SHOW FULL VIEWS;
Danach können Sie die neuen Ansichten direkt abfragen:
SELECT * FROM users;
Lassen Sie uns als Nächstes fortfahren und ein paar weitere Ansichten erstellen.
So erstellen Sie eine Kafka-Senke
Mit Senken können Sie Daten von Materialise an eine externe Quelle senden.
Für diese Demo verwenden wir Redpanda.
Redpanda ist Kafka-API-kompatibel und Materialise kann Daten daraus genauso verarbeiten, wie es Daten aus einer Kafka-Quelle verarbeiten würde.
Lassen Sie uns eine materialisierte Ansicht erstellen, die alle unbezahlten Bestellungen mit hohem Volumen enthält:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Wie Sie sehen können, schließen wir uns hier tatsächlich den users an view, die die Daten direkt aus unserer Postgres-Quelle aufnimmt, und die abandond_orders Ansicht, die die Daten aus dem Redpanda-Thema zusammen aufnimmt.
Lassen Sie uns eine Senke erstellen, an die wir die Daten der obigen materialisierten Ansicht senden:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Wenn Sie sich jetzt mit dem Redpanda-Container verbinden und das rpk topic consume verwenden Befehl, können Sie die Datensätze des Themas lesen.
Derzeit können wir die Ergebnisse jedoch nicht mit rpk in der Vorschau anzeigen weil es AVRO-formatiert ist. Redpanda würde dies höchstwahrscheinlich in Zukunft implementieren, aber im Moment können wir das Thema tatsächlich zurück in Materialise streamen, um das Format zu bestätigen.
Rufen Sie zuerst den Namen des automatisch generierten Themas ab:
SELECT topic FROM mz_kafka_sinks;
Ausgabe:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
Weitere Informationen darüber, wie die Themennamen generiert werden, finden Sie in der Dokumentation hier.
Erstellen Sie dann eine neue Materialisierte Quelle aus diesem Redpanda-Thema:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Achten Sie darauf, den Themennamen entsprechend zu ändern!
Fragen Sie abschließend diese neue materialisierte Ansicht ab:
SELECT * FROM high_volume_orders_test LIMIT 2;
Nachdem Sie nun die Daten im Thema haben, können Sie andere Dienste damit verbinden und nutzen und dann beispielsweise E-Mails oder Benachrichtigungen auslösen.
So verbinden Sie die Metabase
Um auf die Metabase-Instanz zuzugreifen, besuchen Sie https://localhost:3030 wenn Sie die Demo lokal ausführen oder https://your_server_ip:3030 wenn Sie die Demo auf einem Server ausführen. Folgen Sie dann den Schritten, um die Metabase-Einrichtung abzuschließen.
Stellen Sie sicher, dass Sie Materialise als Quelle der Daten auswählen.
Sobald Sie fertig sind, können Sie Ihre Daten so visualisieren, wie Sie es mit einer Standard-PostgreSQL-Datenbank tun würden.
So stoppen Sie die Demo
Führen Sie den folgenden Befehl aus, um alle Dienste zu stoppen:
docker-compose down
Schlussfolgerung
Wie Sie sehen können, ist dies ein sehr einfaches Beispiel für die Verwendung von Materialise. Sie können Materialise verwenden, um Daten aus einer Vielzahl von Quellen aufzunehmen und sie dann an eine Vielzahl von Zielen zu streamen.
Hilfreiche Ressourcen:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT