- Kurz über Pivot-Tabellen
- Pivotieren von Daten mittels Tools (dbForge Studio für MySQL)
- Pivotierung von Daten mittels SQL
- T-SQL-basiertes Beispiel für SQL Server
- Beispiel für MySQL
- Automatisierung der Datenschwenkung, dynamisches Erstellen von Abfragen
Kurz über Pivot-Tabellen
Dieser Artikel befasst sich mit der Transformation von Tabellendaten von Zeilen in Spalten. Eine solche Transformation wird Pivot-Tabellen genannt. Häufig ist das Ergebnis des Pivots eine zusammenfassende Tabelle, in der statistische Daten in der für einen Bericht geeigneten oder erforderlichen Form dargestellt werden.
Außerdem kann eine solche Datentransformation nützlich sein, wenn eine Datenbank nicht normalisiert ist und die Informationen darin in einer nicht optimalen Form gespeichert sind. Wenn Sie also die Datenbank reorganisieren und Daten in neue Tabellen übertragen oder eine erforderliche Datendarstellung generieren, kann Daten-Pivot hilfreich sein, d. h. das Verschieben von Werten aus Zeilen in resultierende Spalten.
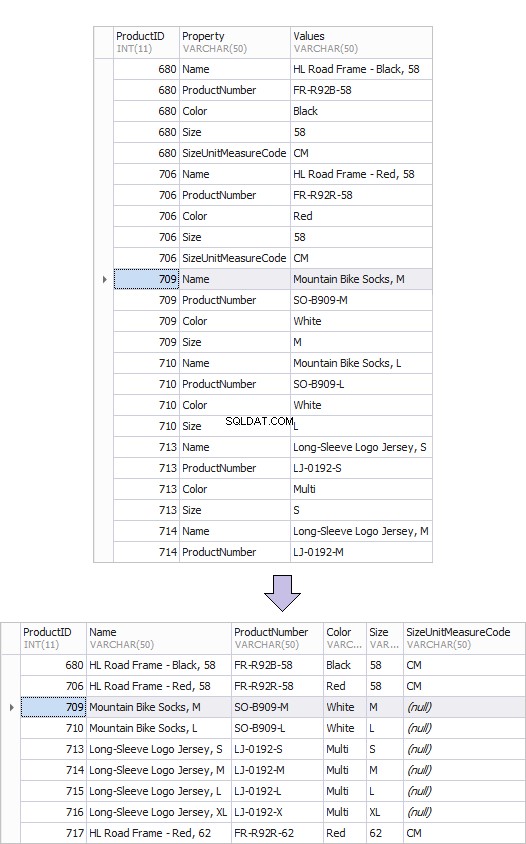
Unten sehen Sie ein Beispiel für die alte Produkttabelle – ProductsOld und die neue – ProductsNew. Durch die Umwandlung von Zeilen in Spalten kann ein solches Ergebnis leicht erreicht werden.
Hier ist ein Beispiel für eine Pivot-Tabelle.
Pivotierung von Daten mittels Tools (dbForge Studio for MySQL)
Es gibt Anwendungen, die über Tools verfügen, die es ermöglichen, Daten-Pivots in einer bequemen grafischen Umgebung zu implementieren. Beispielsweise enthält dbForge Studio für MySQL eine Pivot-Tabellen-Funktionalität, die das gewünschte Ergebnis in nur wenigen Schritten liefert.

Betrachten wir das Beispiel mit einer vereinfachten Bestelltabelle – PurchaseOrderHeader .
CREATE TABLE PurchaseOrderHeader (PurchaseOrderID INT(11) NOT NULL, EmployeeID INT(11) NOT NULL, VendorID INT(11) NOT NULL, PRIMARY KEY (PurchaseOrderID));INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (1 , 258, 1580); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (2, 254, 1496);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (3, 257, 1494);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID ) WERTE (4, 261, 1650); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (5, 251, 1654);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (6, 253, 1664);INSERT PurchaseOrderHeader(PurchaseOrderID , EmployeeID, VendorID) WERTE (7, 255, 1678); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (8, 256, 1616);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (9, 259, 1492); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (10, 250, 1602);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (11, 258, 1540);...
Angenommen, wir müssen eine Auswahl aus der Tabelle treffen und die Anzahl der Bestellungen bestimmter Mitarbeiter bei bestimmten Lieferanten ermitteln. Die Liste der Mitarbeiter, für die Informationen benötigt werden – 250, 251, 252, 253, 254.
Eine bevorzugte Ansicht für den Bericht ist wie folgt.
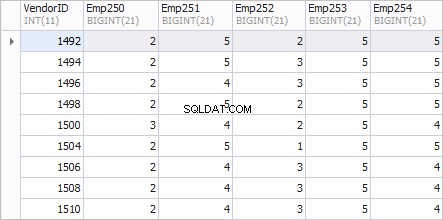
Die linke Spalte VendorID zeigt die IDs von Anbietern; Spalten Emp250 , Emp251 , Emp252 , Emp253 und Emp254 die Anzahl der Bestellungen anzeigen.
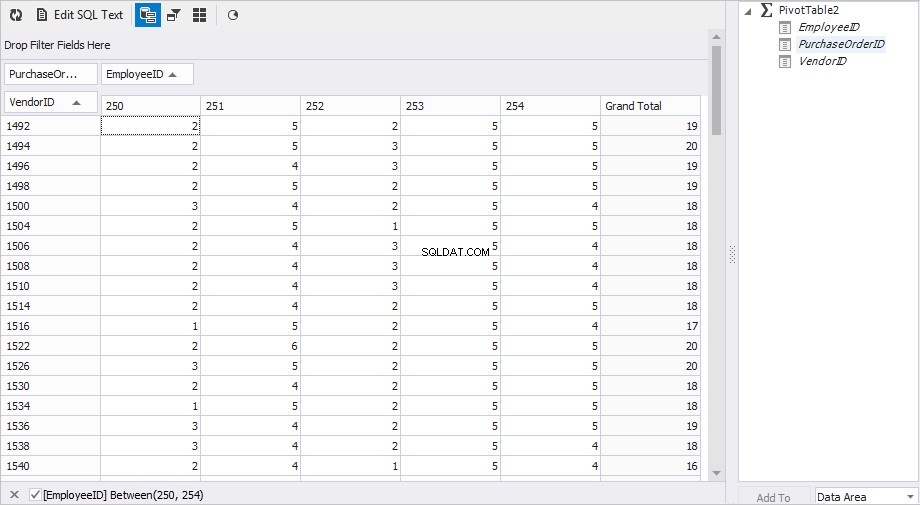
Um dies in dbForge Studio for MySQL zu erreichen, müssen Sie:
- Fügen Sie die Tabelle als Datenquelle für die „Pivot-Tabelle“-Darstellung des Dokuments hinzu. Klicken Sie im Datenbank-Explorer mit der rechten Maustaste auf PurchaseOrderHeader Tabelle und wählen Sie Senden an und dann Pivot-Tabelle im Popup-Menü.
- Geben Sie eine Spalte an, deren Werte Zeilen sein werden. Ziehen Sie die VendorID in das Feld „Zeilenfelder hier ablegen“.
- Geben Sie eine Spalte an, deren Werte Spalten sein werden. Ziehen Sie die EmployeeID Spalte in das Feld „Spaltenfelder hier ablegen“. Sie können auch einen Filter für die gewünschten Mitarbeiter (250, 251, 252, 253, 254) setzen.
- Geben Sie eine Spalte an, deren Werte die Daten sein werden. Ziehen Sie die PurchaseOrderID in das Feld „Datenelemente hier ablegen“.
- In den Eigenschaften der PurchaseOrderID Geben Sie in der Spalte die Art der Aggregation an – Anzahl der Werte .
Wir haben schnell das gewünschte Ergebnis erhalten.
Pivotierung von Daten mittels SQL
Natürlich kann die Datentransformation mittels einer Datenbank durchgeführt werden, indem eine SQL-Abfrage geschrieben wird. Aber es gibt ein kleines Problem, MySQL hat keine spezielle Anweisung, die dies erlaubt.
T-SQL-basiertes Beispiel für SQL Server
Beispielsweise haben SqlServer und Oracle den PIVOT-Operator, der eine solche Datentransformation ermöglicht. Wenn wir mit SqlServer arbeiten würden, würde unsere Abfrage so aussehen.
SELECT VendorID ,[250] AS Emp1 ,[251] AS Emp2 ,[252] AS Emp3 ,[253] AS Emp4 ,[254] AS Emp5FROM (SELECT PurchaseOrderID ,EmployeeID ,VendorID FROM Purchasing.PurchaseOrderHeader) pPIVOT( COUNT (PurchaseOrderID) FOR EmployeeID IN ([250], [251], [252], [253], [254])) AS tORDER BY t.VendorID;
Beispiel für MySQL
In MySQL müssen wir die Mittel von SQL verwenden. Die Daten sollten nach der Anbieterspalte gruppiert werden – VendorID , und für jeden erforderlichen Mitarbeiter (EmployeeID ), müssen Sie eine separate Spalte mit einer Aggregatfunktion erstellen.
In unserem Fall müssen wir die Anzahl der Bestellungen berechnen, also verwenden wir die Aggregatfunktion COUNT.
In der Quelltabelle werden die Informationen aller Mitarbeiter in einer Spalte EmployeeID gespeichert , und wir müssen die Anzahl der Bestellungen für einen bestimmten Mitarbeiter berechnen, also müssen wir unserer Aggregatfunktion beibringen, nur bestimmte Zeilen zu verarbeiten.
Die Aggregatfunktion berücksichtigt keine NULL-Werte, und wir nutzen diese Besonderheit für unsere Zwecke.
Sie können den bedingten Operator IF oder CASE verwenden, der einen bestimmten Wert für den gewünschten Mitarbeiter zurückgibt, andernfalls wird einfach NULL zurückgegeben; infolgedessen zählt die COUNT-Funktion nur Nicht-NULL-Werte.
Die resultierende Abfrage lautet wie folgt:
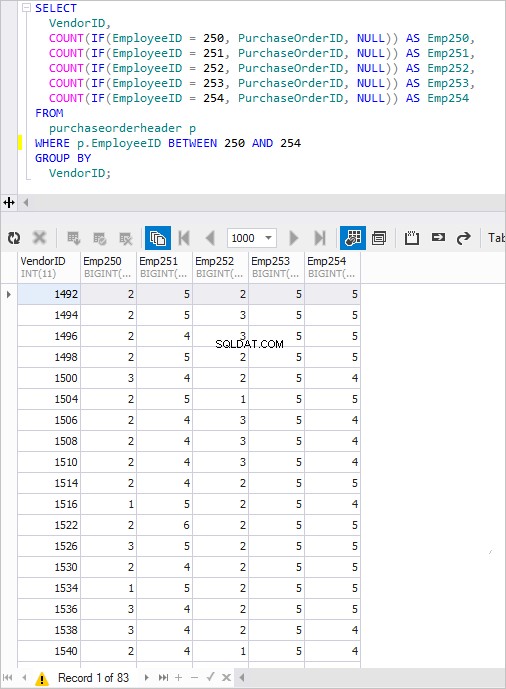
SELECT VendorID, COUNT(IF(EmployeeID =250, PurchaseOrderID, NULL)) AS Emp250, COUNT(IF(EmployeeID =251, PurchaseOrderID, NULL)) AS Emp251, COUNT(IF(EmployeeID =252, PurchaseOrderID, NULL) ) AS Emp252, COUNT(IF(EmployeeID =253, PurchaseOrderID, NULL)) AS Emp253, COUNT(IF(EmployeeID =254, PurchaseOrderID, NULL)) AS Emp254FROM PurchaseOrderHeader pWHERE p.EmployeeID BETWEEN 250 AND 254GROUP BY VendorID;
Oder sogar so:
VendorID, COUNT(IF(EmployeeID =250, 1, NULL)) AS Emp250, COUNT(IF(EmployeeID =251, 1, NULL)) AS Emp251, COUNT(IF(EmployeeID =252, 1, NULL)) AS Emp252, COUNT(IF(EmployeeID =253, 1, NULL)) AS Emp253, COUNT(IF(EmployeeID =254, 1, NULL)) AS Emp254FROM PurchaseOrderHeader pWHERE p.EmployeeID BETWEEN 250 AND 254GROUP BY VendorID;
Bei der Ausführung erhält man ein bekanntes Ergebnis.
Daten-Pivot automatisieren, Abfrage dynamisch erstellen
Wie man sieht, hat die Abfrage eine gewisse Konsistenz, d. h. alle transformierten Spalten sind ähnlich aufgebaut, und um die Abfrage zu schreiben, muss man die konkreten Werte aus der Tabelle kennen. Um eine Pivot-Abfrage zu erstellen, müssen Sie alle möglichen Werte überprüfen und erst dann sollten Sie die Abfrage schreiben. Alternativ können Sie diese Aufgabe an einen Server übergeben, der diese Werte erhält und die Routineaufgabe dynamisch ausführt.
Kehren wir zum ersten Beispiel zurück, in dem wir die neue Tabelle ProductsNew erstellt haben aus ProductsOld Tisch. Dort sind die Werte von Eigenschaften begrenzt, und wir können nicht einmal alle möglichen Werte kennen; Wir haben nur die Informationen darüber, wo die Namen der Eigenschaften und deren Wert gespeichert sind. Dies sind die Eigenschaften und Wert Spalten.
Der gesamte Algorithmus zum Erstellen der SQL-Abfrage läuft darauf hinaus, die Werte zu erhalten, aus denen neue Spalten und Verkettungen von unveränderlichen Teilen der Abfrage gebildet werden.
SELECT GROUP_CONCAT( CONCAT( ' MAX(IF(Property =''', t.Property, ''', Value, NULL)) AS ', t.Property ) ) INTO @PivotQueryFROM (SELECT Property FROM ProductOld GROUP BY Eigenschaft) t;SET @PivotQuery =CONCAT('SELECT ProductID,', @PivotQuery, 'FROM ProductOld GROUP BY ProductID'); Die Variable @PivotQuery speichert unsere Abfrage, der Text wurde der Übersichtlichkeit halber formatiert.
SELECT ProductID, MAX(IF(Property ='Color', Value, NULL)) AS Color, MAX(IF(Property ='Name', Value, NULL)) AS Name, MAX(IF(Property ='ProductNumber ', Wert, NULL)) AS ProductNumber, MAX(IF(Property ='Size', Value, NULL)) AS Size, MAX(IF(Property ='SizeUnitMeasureCode', Value, NULL)) AS SizeUnitMeasureCodeFROM ProductOldGROUP BY ProductIDNach der Ausführung erhalten wir das gewünschte Ergebnis entsprechend dem Schema der ProductsNew-Tabelle.
ausgeführt werden
Außerdem kann die Abfrage aus der Variablen @PivotQuery im Skript mit dem MySQL-Statement EXECUTE.PREPARE-Anweisung FROM @PivotQuery;EXECUTE-Anweisung;DEALLOCATE PREPARE-Anweisung;