Im Folgenden finden Sie einen Auszug aus unserem Whitepaper „How to Design Highly Available Open Source Database Environments“, das kostenlos heruntergeladen werden kann.
Ein paar Worte zu „Hochverfügbarkeit“
Heutzutage ist Hochverfügbarkeit ein Muss für jeden ernsthaften Einsatz. Längst vorbei sind die Zeiten, in denen Sie eine mehrstündige Ausfallzeit Ihrer Datenbank einplanen konnten, um eine Wartung durchzuführen. Wenn Ihre Dienste nicht verfügbar sind, verlieren Sie Kunden und Geld. Daher hat die Hochverfügbarkeit einer Datenbankumgebung normalerweise eine der höchsten Prioritäten.
Dies stellt eine erhebliche Herausforderung für Datenbankadministratoren dar. Zunächst einmal, wie können Sie feststellen, ob Ihre Umgebung hochverfügbar ist oder nicht? Wie würden Sie es messen? Welche Schritte müssen Sie unternehmen, um die Verfügbarkeit zu verbessern? Wie gestalten Sie Ihr Setup so, dass es von Anfang an hochverfügbar ist?
Es gibt viele, viele HA-Lösungen im MySQL- (und MariaDB-) Ökosystem, aber woher wissen wir, welchen wir vertrauen können? Einige Lösungen funktionieren möglicherweise unter bestimmten Bedingungen, verursachen jedoch möglicherweise mehr Probleme, wenn sie außerhalb dieser Bedingungen angewendet werden. Selbst eine Basisfunktionalität wie die MySQL-Replikation, die auf viele Arten konfiguriert werden kann, kann erheblichen Schaden anrichten - zum Beispiel die zirkuläre Replikation mit mehreren beschreibbaren Mastern. Obwohl es einfach ist, ein „Multi-Master-Setup“ mithilfe der Replikation einzurichten, kann es sehr leicht brechen und uns mit divergierenden Datensätzen auf verschiedenen Servern zurücklassen. Für eine Datenbank, die oft als Single Source of Truth angesehen wird, kann eine beeinträchtigte Datenintegrität katastrophale Folgen haben.
In den folgenden Kapiteln besprechen wir die Anforderungen für Hochverfügbarkeit in Datenbank-Setups
und wie das System von Grund auf entworfen wird.
Hochverfügbarkeit messen
Was ist Hochverfügbarkeit? Um entscheiden zu können, ob eine bestimmte Umgebung hochverfügbar ist oder nicht, muss man dafür einige Metriken haben. Es gibt zahlreiche Möglichkeiten, wie Sie Hochverfügbarkeit messen können. Wir konzentrieren uns auf einige der grundlegendsten Dinge.
Aber lassen Sie uns zuerst überlegen, was es mit dieser ganzen Hochverfügbarkeit auf sich hat? Was ist seine Aufgabe? Es geht darum sicherzustellen, dass Ihre Umgebung ihren Zweck erfüllt. Der Zweck kann auf viele Arten definiert werden, aber in der Regel geht es darum, einen Dienst zu erbringen. In der Datenbankwelt hat es typischerweise etwas mit Daten zu tun. Es könnte Daten an Ihre interne Anwendung liefern. Es kann sein, Daten zu speichern und durch analytische Verfahren abfragbar zu machen. Es kann sein, dass einige Daten für Ihre Benutzer gespeichert und auf Anfrage bereitgestellt werden. Sobald wir uns über den Zweck im Klaren sind, können wir die beteiligten Erfolgsfaktoren ermitteln. Dies hilft uns zu definieren, was Hochverfügbarkeit in unserem speziellen Fall bedeutet.
SLAs
Vereinbarung zum Servicelevel (SLA). Es ist auch durchaus üblich, SLAs für interne Dienste zu definieren. Was ist ein SLA? Es ist eine Definition des Service-Levels, das Sie Ihren Kunden bieten möchten. Auf diese Weise können sie besser verstehen, welches Maß an Stabilität Sie für einen Service planen, den sie gekauft haben oder kaufen möchten. Es gibt zahlreiche Methoden, die Sie nutzen können, um ein SLA zu erstellen, aber typische sind:
- Verfügbarkeit des Dienstes (Prozent)
- Reaktionsfähigkeit des Dienstes – Latenz (Durchschnitt, Maximum, 95. Perzentil, 99. Perzentil)
- Paketverlust über das Netzwerk (Prozent)
- Durchsatz (Durchschnitt, Minimum, 95. Perzentil, 99. Perzentil)
Es kann jedoch komplexer werden. In einer fragmentierten Umgebung mit mehreren Benutzern können Sie Ihr SLA beispielsweise wie folgt definieren:„Service will be available 99,99% of the time, downtime wird deklariert, wenn mehr als 2% der Benutzer betroffen sind. Kein Vorfall kann länger als 15 Minuten dauern, um gelöst zu werden.“ Ein solches SLA kann auch um die Abfrageantwortzeit erweitert werden:„Ausfallzeit wird aufgerufen, wenn 99 Perzentile der Latenz für Abfragen 200 Millisekunden überschreiten.“
Neuner
Die Verfügbarkeit wird typischerweise in „Neunen“ gemessen, schauen wir uns an, was genau eine bestimmte Anzahl von „Neunen“ garantiert. Die folgende Tabelle stammt aus Wikipedia:
| Verfügbarkeit % | Ausfallzeit pro Jahr | Ausfallzeit pro Monat | Ausfallzeit pro Woche | Ausfallzeit pro Tag |
|---|---|---|---|---|
| 90 % ("eins neun") | 36,5 Tage | 72 Stunden | 16,8 Stunden | 2,4 Stunden |
| 95 % ("eineinhalb Neunen") | 18,25 Tage | 36 Stunden | 8,4 Stunden | 1,2 Stunden |
| 97 % | 10,96 Tage | 21,6 Stunden | 5,04 Stunden | 43,2 Minuten |
| 98 % | 7,30 Tage | 14,4 Stunden | 3,36 Stunden | 28,8 Minuten |
| 99 % ("zwei Neunen") | 3,65 Tage | 7.20 Stunden | 1,68 Stunden | 14,4 min |
| 99,5 % ("zweieinhalb Neunen") | 1,83 Tage | 3,60 Stunden | 50,4 min | 7,2 Minuten |
| 99,8 % | 17.52 Uhr | 86,23 min | 20.16 min | 2,88 min |
| 99,9 % ("drei Neunen") | 8,76 Stunden | 43,8 Minuten | 10,1 min | 1,44 min |
| 99,95 % ("dreieinhalb Neunen") | 4,38 Stunden | 21.56 min | 5,04 min | 43,2 Sekunden |
| 99,99 % ("vier Neunen") | 52,56 min | 4,38 min | 1,01 min | 8,64 s |
| 99,995 % ("viereinhalb Neunen") | 26.28 min | 2,16 min | 30,24 Sek. | 4,32 Sekunden |
| 99,999 % ("fünf Neunen") | 5,26 min | 25,9 s | 6,05 s | 864,3 ms |
| 99,9999 % ("sechs Neunen") | 31,5 Sek. | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999 % ("sieben Neunen") | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999 % ("acht Neunen") | 315,569 ms | 26,297 ms | 6,048 ms | 0,864 ms |
| 99,9999999 % ("neun Neunen") | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Wie wir sehen können, eskaliert es schnell. Fünf Neunen (99,999 % Verfügbarkeit) entsprechen 5,26 Minuten Ausfallzeit im Laufe eines Jahres. Die Verfügbarkeit kann auch in verschiedenen, kleineren Bandbreiten berechnet werden:pro Monat, pro Woche, pro Tag. Denken Sie an diese Zahlen, da sie nützlich sein werden, wenn wir beginnen, die Kosten zu diskutieren, die mit der Aufrechterhaltung unterschiedlicher Verfügbarkeitsstufen verbunden sind.
Verfügbarkeit messen
Um festzustellen, ob eine Ausfallzeit vorliegt oder nicht, muss man Einblick in die Umgebung haben. Sie müssen die Metriken verfolgen, die die Verfügbarkeit Ihrer Systeme definieren. Es ist wichtig, daran zu denken, dass Sie es aus der Sicht eines Kunden messen und das Gesamtbild berücksichtigen sollten. Es spielt keine Rolle, ob Ihre Datenbanken aktiv sind, wenn beispielsweise aufgrund eines Netzwerkproblems keine Anwendung sie erreichen kann. Jeder einzelne Baustein Ihres Setups wirkt sich auf die Verfügbarkeit aus.
Einer der guten Orte, an denen Sie nach Verfügbarkeitsdaten suchen können, sind Webserver-Protokolle. Alle Anfragen, die mit Fehlern endeten, bedeuten, dass etwas passiert ist. Es könnte der von der Anwendung zurückgegebene HTTP-Fehler 500 sein, weil die Datenbankverbindung fehlgeschlagen ist. Das könnten Programmfehler sein, die auf einige Datenbankprobleme hinweisen und die im Fehlerprotokoll von Apache gelandet sind. Sie können auch eine einfache Metrik als Betriebszeit von Datenbankservern verwenden, obwohl es bei komplexeren SLAs schwierig sein kann, festzustellen, wie sich die Nichtverfügbarkeit einer Datenbank auf Ihre Benutzerbasis ausgewirkt hat. Unabhängig davon, was Sie tun, sollten Sie mehr als eine Metrik verwenden - dies ist erforderlich, um Probleme zu erfassen, die möglicherweise auf verschiedenen Ebenen Ihrer Umgebung aufgetreten sind.
Magische Zahl:„Drei“
Auch wenn es bei Hochverfügbarkeit auch um Redundanz geht, ist bei Datenbank-Clustern die Drei eine magische Zahl. Es reicht nicht aus, zwei Knoten für Redundanz zu haben – ein solches Setup bietet keine integrierte Hochverfügbarkeit. Sicher, es könnte besser sein als nur ein einzelner Knoten, aber menschliches Eingreifen ist erforderlich, um Dienste wiederherzustellen. Mal sehen, warum das so ist.
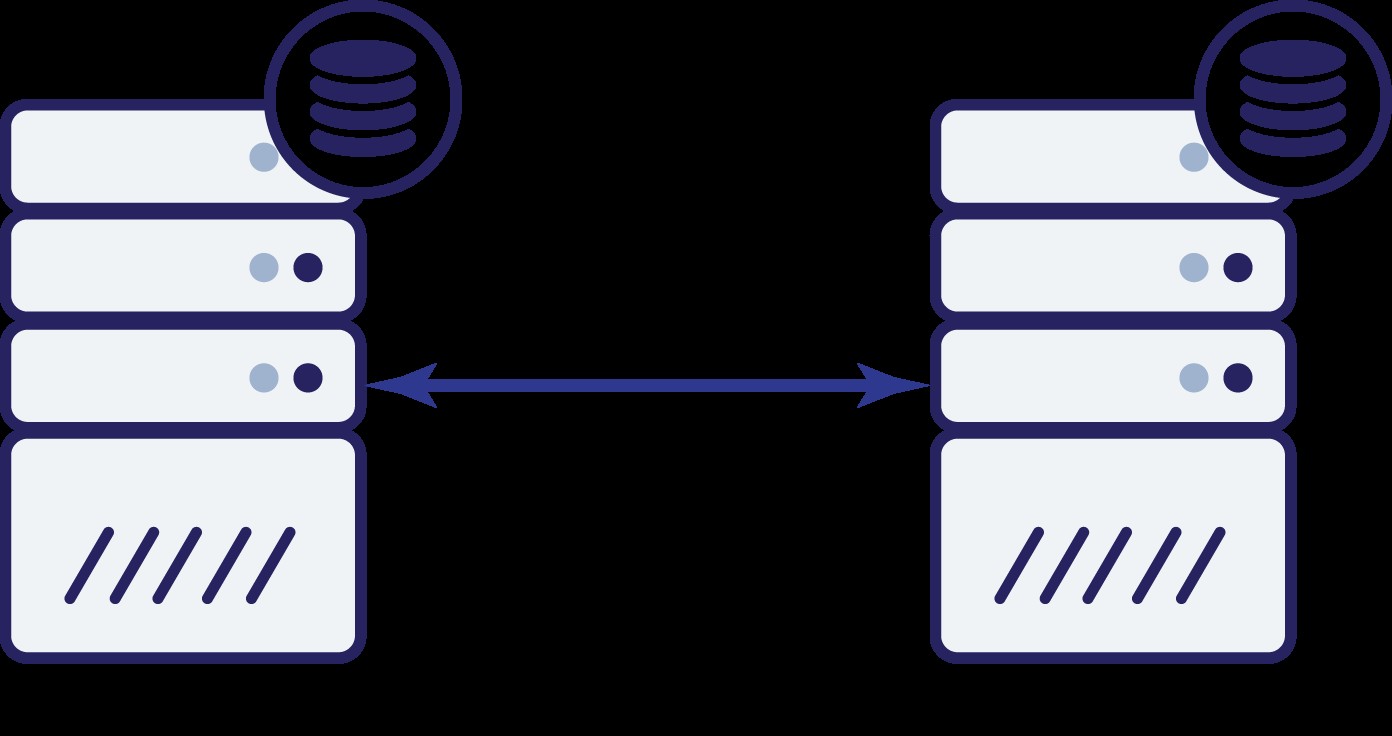
Nehmen wir an, wir haben zwei Knoten, A und B. Zwischen ihnen besteht eine Netzwerkverbindung. Nehmen wir an, dass sowohl A als auch B Schreibvorgänge ausführen und die Anwendung zufällig auswählt, wo eine Verbindung hergestellt werden soll (was bedeutet, dass ein Teil der Anwendung eine Verbindung zu Knoten A und der andere Teil eine Verbindung zu Knoten B herstellt). Stellen wir uns nun vor, wir hätten ein Netzwerkproblem, das zu einem Verlust der Netzwerkverbindung zwischen A und B führt.
Was jetzt? Weder A noch B können den Zustand des anderen Knotens kennen. Es gibt zwei Aktionen, die von beiden Knoten ausgeführt werden können:
- Sie können weiterhin Datenverkehr akzeptieren
- Sie können den Betrieb einstellen und jeglichen Verkehr verweigern
Denken wir über die erste Option nach. Solange der andere Knoten tatsächlich ausgefallen ist, ist dies die bevorzugte Maßnahme – wir möchten, dass unsere Datenbank weiterhin Datenverkehr bereitstellt. Das ist schließlich die Grundidee hinter Hochverfügbarkeit. Was würde jedoch passieren, wenn beide Knoten weiterhin Datenverkehr akzeptieren würden, während sie voneinander getrennt sind? Auf beiden Seiten werden neue Daten hinzugefügt, und die Datensätze werden nicht mehr synchron sein. Wenn das Netzwerkproblem gelöst ist, wird es eine entmutigende Aufgabe sein, diese beiden Datensätze zusammenzuführen. Daher ist es nicht akzeptabel, beide Knoten am Laufen zu halten. Das Problem ist - wie kann Knoten A feststellen, ob Knoten B lebt oder nicht (und umgekehrt)? Die Antwort ist - es kann nicht. Wenn die gesamte Konnektivität unterbrochen ist, gibt es keine Möglichkeit, einen ausgefallenen Knoten von einem ausgefallenen Netzwerk zu unterscheiden. Daher besteht die einzig sichere Maßnahme darin, dass beide Knoten alle Operationen einstellen und sich weigern,
Datenverkehr zu bedienen.
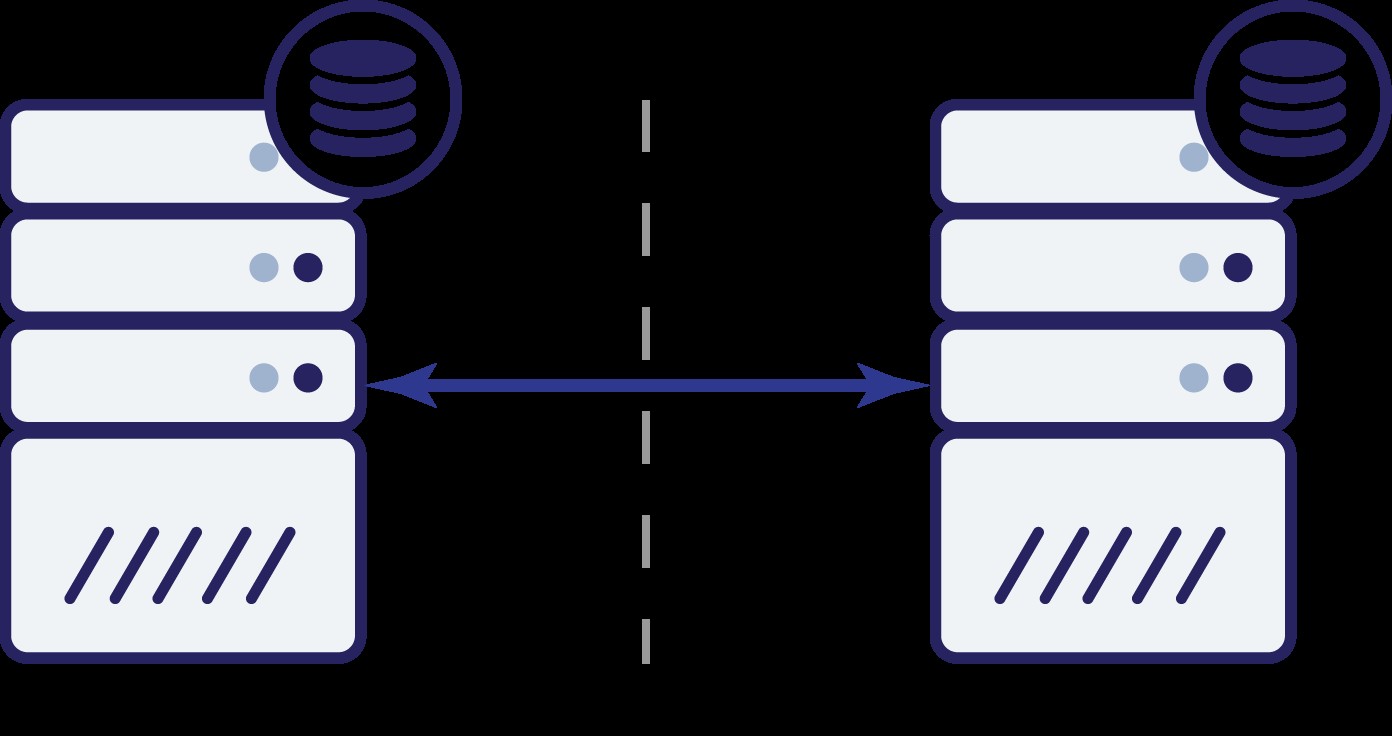
Lassen Sie uns jetzt überlegen, wie uns ein dritter Knoten in einer solchen Situation helfen kann.
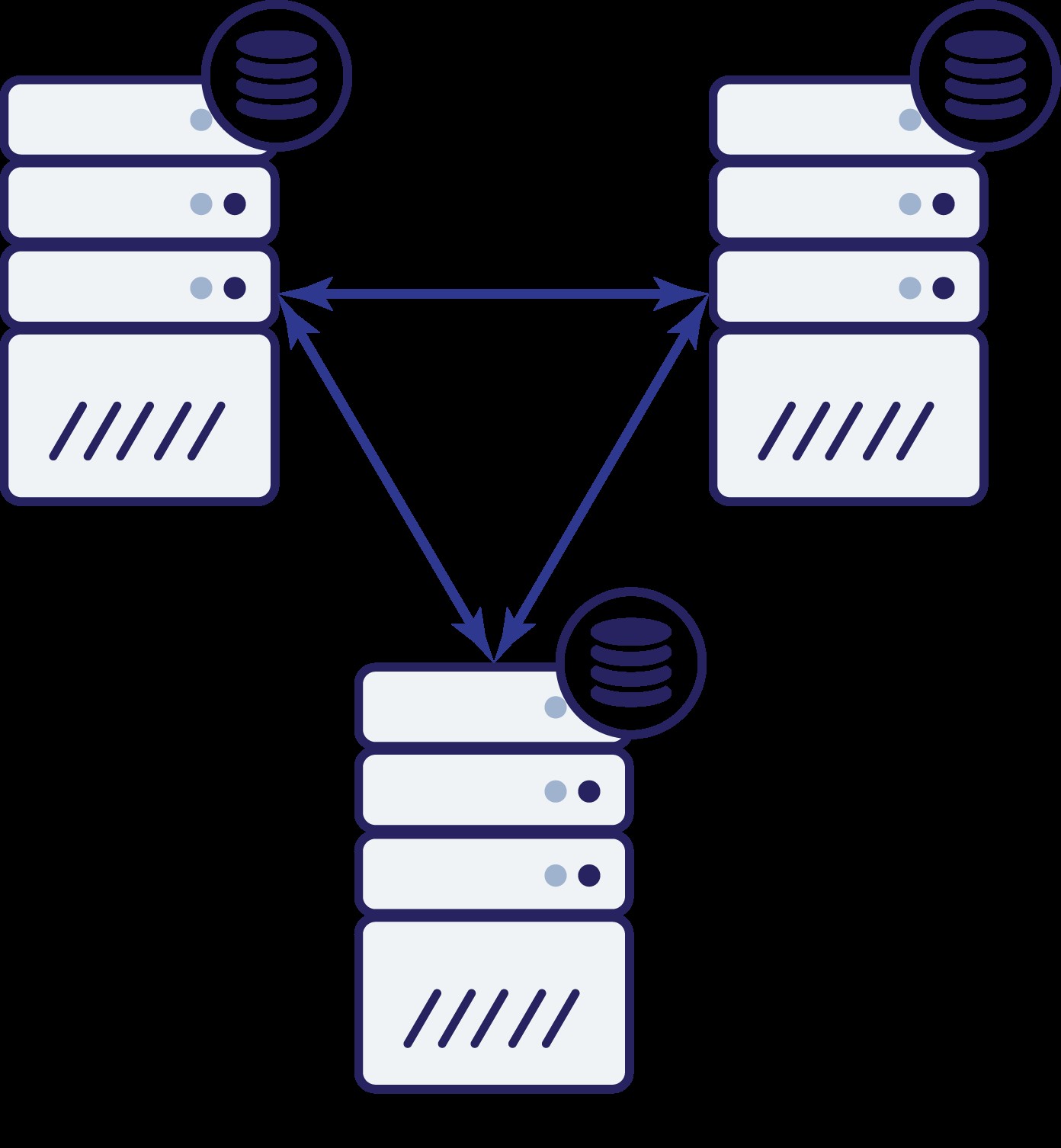
Wir haben also jetzt drei Knoten:A, B und C. Alle sind miteinander verbunden, alle handhaben Lese- und Schreibvorgänge.
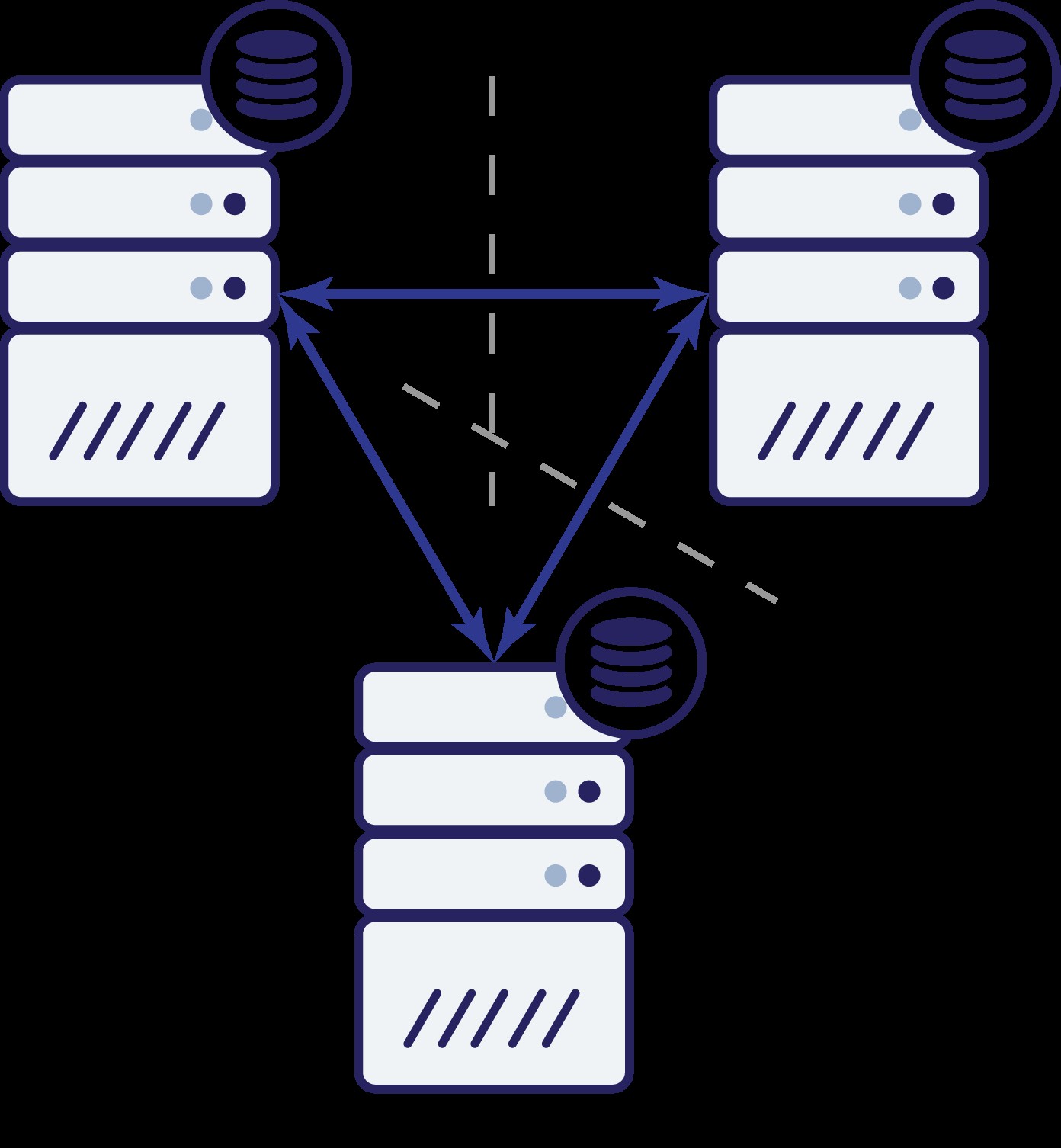
Auch hier wurde Knoten B wie im vorherigen Beispiel aufgrund von Netzwerkproblemen vom Rest des Clusters abgeschnitten. Was kann als nächstes passieren? Nun, die Situation ist ziemlich ähnlich zu dem, was wir zuvor besprochen haben. Zwei Optionen:Knoten B kann entweder ausgefallen sein (und der Rest des Clusters sollte fortfahren) oder er kann in Betrieb sein, in diesem Fall sollte er keinen Datenverkehr verarbeiten dürfen. Können wir jetzt sagen, wie der Zustand des Clusters ist? Eigentlich ja. Wir können sehen, dass die Knoten A und C miteinander sprechen können und sich folglich darauf einigen können, dass Knoten B nicht verfügbar ist. Sie können nicht sagen, warum es passiert ist, aber sie wissen, dass von drei Knoten im Cluster zwei immer noch miteinander verbunden sind. Da diese beiden Knoten einen Großteil des Clusters bilden, ist es möglich, den Datenverkehr weiter zu verarbeiten. Gleichzeitig kann Knoten B auch ableiten, dass das Problem auf seiner Seite liegt. Er kann weder auf Knoten A noch auf Knoten C zugreifen, wodurch Knoten B vom Rest des Clusters getrennt wird. Da es isoliert ist und nicht Teil einer Mehrheit (1 von 3), ist die einzige sichere Maßnahme, die es ergreifen kann, den Datenverkehr zu stoppen und die Annahme von Anfragen zu verweigern, um sicherzustellen, dass keine Datendrift auftritt.
Das bedeutet natürlich nicht, dass Sie nur drei Knoten im Cluster haben können. Wenn Sie eine bessere Fehlertoleranz wünschen, können Sie weitere hinzufügen. Denken Sie jedoch daran, dass es eine ungerade Zahl sein sollte, wenn Sie die Hochverfügbarkeit verbessern möchten. Außerdem haben wir in den obigen Beispielen über „Knoten“ gesprochen. Bitte beachten Sie, dass dies auch für Rechenzentren, Verfügbarkeitszonen usw. gilt. Wenn Sie zwei Rechenzentren haben, die jeweils die gleiche Anzahl von Knoten haben (sagen wir jeweils drei Knoten), und Sie die Konnektivität zwischen diesen beiden DCs verlieren, gelten hier dieselben Prinzipien - Sie können nicht sagen, welche Hälfte des Clusters mit der Verarbeitung des Datenverkehrs beginnen soll. Um das sagen zu können, muss man einen Beobachter in einem dritten Rechenzentrum haben. Es kann sich um eine weitere Gruppe von Knoten oder nur um einen einzelnen Host handeln, der
die Aufgabe hat, den Zustand der verbleibenden Datenaufnehmer zu beobachten und an Entscheidungen teilzunehmen (ein Beispiel wäre hier der Galera-Arbitrator).
Single Points of Failure
Bei Hochverfügbarkeit geht es darum, Single Points of Failure (SPOF) zu beseitigen und keine neuen in den Prozess einzuführen. Was sind die SPOFs? Jeder Teil Ihrer Infrastruktur, der bei einem Ausfall Ausfallzeiten gemäß SLA verursacht, wird als SPOF bezeichnet. Infrastrukturdesign erfordert einen ganzheitlichen Ansatz, die verschiedenen Komponenten können nicht unabhängig voneinander entworfen werden. Höchstwahrscheinlich sind Sie nicht für das gesamte Design verantwortlich -
Datenbankadministratoren konzentrieren sich in der Regel auf Datenbanken und nicht beispielsweise auf die Netzwerkschicht. Dennoch müssen Sie die anderen Teile im Auge behalten und mit den Teams zusammenarbeiten, die dafür verantwortlich sind, um sicherzustellen, dass nicht nur der Teil, für den Sie verantwortlich sind, korrekt entworfen wurde, sondern auch, dass die restlichen Teile der Infrastruktur mithilfe von entworfen wurden gleichen Prinzipien. Darüber hinaus hilft Ihnen dieses Wissen darüber, wie die gesamte
Infrastruktur gestaltet ist, auch beim Entwerfen des Datenbank-Stacks. Zu wissen, welche Probleme auftreten können, hilft beim Aufbau einiger Mechanismen, um zu verhindern, dass sie die Verfügbarkeit der Datenbank beeinträchtigen.